CQRS 기초
Updated:
CQRS는 시스템의 복잡성이 증가함에 따라 명령과 조회를 별도의 모델로 분리하여 확장성과 유지 보수를 향상시키는 아키텍처 패턴이다.
- C: 명령(Command)
- Q: 조회(Query)
- R: 책임(Responsibility)
- S: 분리(Segregation)
즉, CQRS는 명령과 조회의 책임을 분리하는 것이다. 이는 DDD나 이벤트 기반 시스템, 고성능이 필요한 조회 API 설계에 자주 적용된다.
CQRS에서 명령이란 데이터를 변경하는 작업을 의미하고, 조회는 목록/상세 등 데이터를 조회하는 작업을 의미한다. 그래서 데이터를 변경하는 작업과 데이터를 조회하는 작업을 분리하는 것을 의미한다.
CQRS는 왜 사용할까?
조회 성능 향상
예를 들어, 업체 목록 조회 화면에서 업체 정보, 업체 담당자 이름, 소속 허브 이름의 정보가 함께 필요하다고 가정해보자. 모놀리식에서는 하나의 데이터베이스 안에서 JOIN으로 해결할 수 있다.
SELECT company.*, user.name, hub.name
FROM Company company
INNER JOIN User user ON company.user_id = user.id
INNER JOIN Hub uhb ON company.hub_id = hub.id
Company를 기준으로 N건을 순회하면서 User, Hub를 인덱스로 조회하므로 시간복잡도는 대략 O(N log M + N log H) 로 볼 수 있다. 다만, 조회 요구사항이 복잡해질수록 JOIN 대상 테이블이 많아지고, 정렬, 필터링, 집계가 추가되면서 성능 저하가 발생할 수 있다.
- JOIN 수 증가로 인한 쿼리 복잡도 증가
- 실행 계획 최적화 어려움
- 인덱스 설계 부담 증가
- 특정 조회 API가 DB에 큰 부하를 줄 수 있음
즉, 모놀리식에서도 조회 요구사항이 복잡해질수록 읽기 모델을 별도로 최적화할 필요성이 생긴다.
MSA에서는 Company, User, Hub가 각각 다른 서비스에 존재할 수 있기 때문에, DB JOIN 대신 서비스 간 호출로 데이터를 조합해야 한다.
public List<CompanyResponse> getCompanies() {
List<Company> companies = companyRepository.findAll();
return companies.stream().map(company -> {
User user = userClient.getUser(company.getUserId());
Hub hub = hubClient.getHub(company.getHubId());
return CompanyResponse.from(company,user,hub);
}).toList();
} // 네트워크 호출 2N
// 혹은 벌크로 한다면?
public List<CompanyResponse> getCompanies() {
List<Company> companies = companyRepository.findAll();
List<UUID> userIds = companies.stream()
.map(Company::getUserId)
.distinct()
.toList();
List<UUID> hubIds = companies.stream()
.map(Company::getHubId)
.distinct()
.toList();
Map<UUID, UserDto> usersById = userClient.getUsers(userIds).stream()
.collect(Collectors.toMap(UserDto::getId, Function.identity())); // 네트워크 호출
Map<UUID, HubDto> hubsById = hubClient.getHubs(hubIds).stream()
.collect(Collectors.toMap(HubDto::getId, Function.identity())); // 네트워크 호출
return companies.stream()
.map(company -> CompanyResponse.from(
company,
usersById.get(company.getUserId()),
hubsById.get(company.getHubId())
))
.toList();
}
여기에 CQRS를 적용해본다면, CQRS는 조회 전용 모델(Read Model)을 분리하여, 조회에 필요한 데이터를 미리 조합해 둔다.
public List<CompanyResponse> getCompanies() {
List<CompanyResponse> companies = companyQueryService.findAll();
}
역할이 다른 로직을 분리
글 작성 시에는 로그인한 사용자 검증, 제목/본문 유효성 검사, 금칙어 필터링, 저장 로직 등 복잡한 비즈니스 로직이 존재하지만, 글 상세조회는 단순히 ID 기반으로 데이터를 조회만 하면 된다.
이런 경우, Command와 Query를 분리하면 복잡한 변경 로직과 단순한 조회 로직이 섞이지 않아서 유지보수가 쉬워진다.
단일 DB의 한계
RDB 환경에서 5개 테이블을 조인해서 정보를 가져와야 하는 요구사항이 있다고 가정해보자.
SELECT
o.id AS order_id,
o.created_at AS order_date,
u.name AS customer_name,
oi.product_name,
oi.quantity,
oi.price,
p.payment_method,
p.payment_status,
p.paid_at
FROM orders o
JOIN users u ON o.user_id = u.id
JOIN shipping_address sa ON o.shipping_address_id = sa.id
JOIN order_items oi ON o.id = oi.order_id
LEFT JOIN payments p ON o.id = p.order_id
WHERE o.id = :orderId;
이런 복잡한 조회 쿼리는 실시간 트래픽이 많아질수록 성능 병목이 생길 수 있다. CQRS의 Query 모델에서는 위와 같은 결과를 별도 Read View로 분리 해서, Redis나 조회 전용 DB에 캐싱하면 복잡한 데이터를 훨씬 빠르고 가볍게 서빙할 수 있다는 장점이 있다.
서비스의 확정성과 장애대응 측면
예를 들어, 조회 트래픽이 높은 경우에는 Query 모델만 별도로 배포하거나, 읽기 전용 DB를 여러 개로 수평 확장할 수도 있다. 명령과 조회의 책임이 나뉘어 있기 때문에, 장애가 발생했을 때 조회 기능만 별도로 유지하는 등의 전략도 가능하다.
언제 사용하면 좋을까?
- 조회 트래픽이 매우 높은 경우
- 조회 요구사항이 복잡하고 다양한 경우
- 읽기와 쓰기의 비율 차이가 큰 경우
- 여러 서비스의 데이터를 조합해야 하는 경우 (MSA)
사용 예시
배달의 민족 B마트
- DB 스키마와 API 응답 구조 간 불일치로 인한 성능 문제
- DB는 정규화 중심 구조였으나, 클라이언트는 복잡한 데이터 구조를 원함
- 따라서 조회시 과도한 Join, 연관 조회로 성능 저하 방생
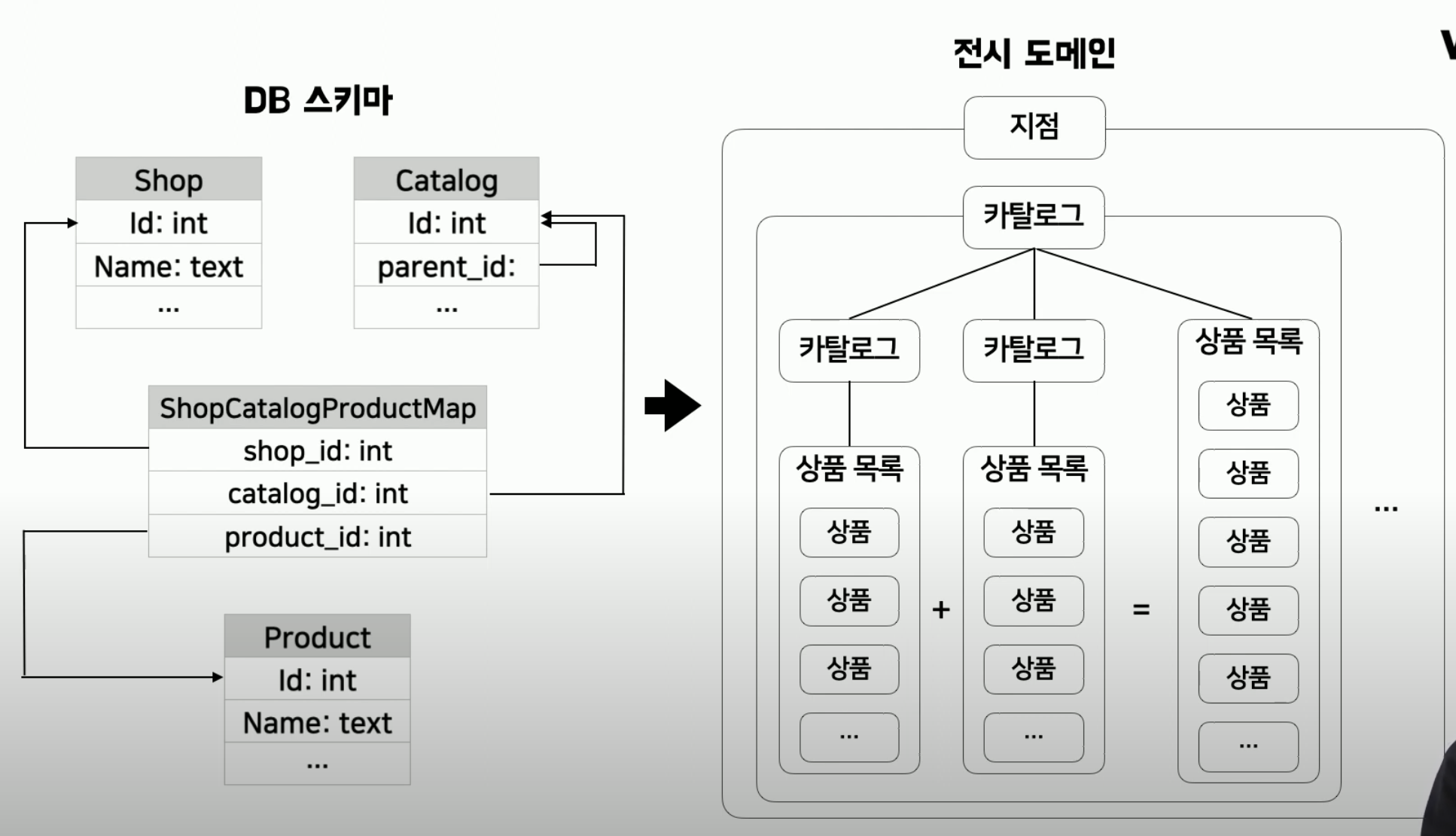
- 성능 문제를 개선하기 위해 도메인 모델을 분리하였지만, 구조적인 한계로 캐싱을 도입하였고, 그 결과로 캐시 관리에 어려움이 있었음
- 캐시 불일치, 동기화 이슈, 장애 복구 어려움의 문제가 발생
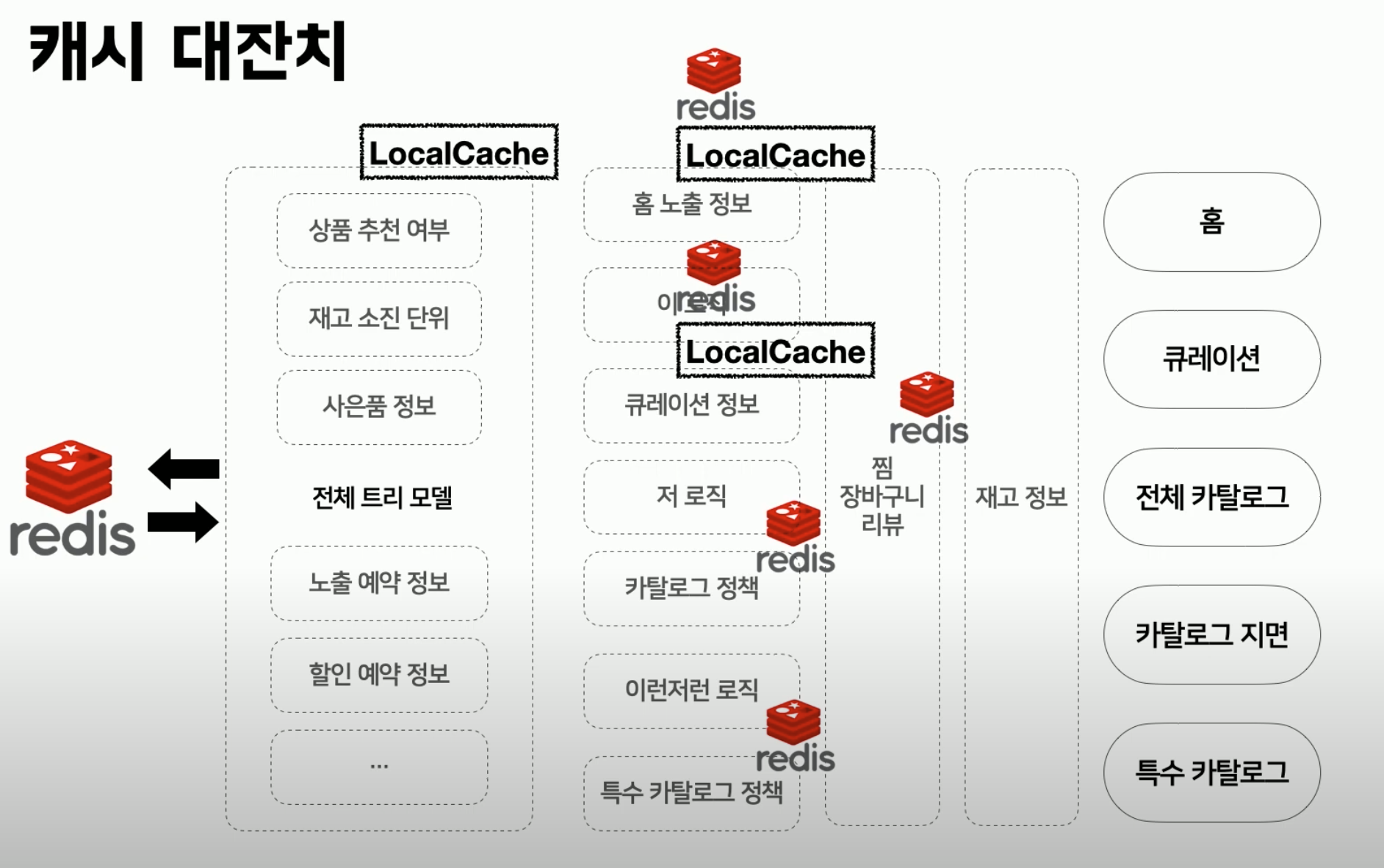
- 따라서 시스템의 요구사항에 따라 조회용 모델을 추출하고, Kafka를 통한 Event Driven 방식으로 CQRS를 구현하여 조회 성능 문제를 개선하였음
- DB 구조를 쓰기(주문, 재고 변경) / 읽기(전시, 추천 등) 모델로 분리
- 클라이언트 요구에 최적화된 조회 전용 DB / Read Model 구성
- Kafka를 통한 이벤트 기반 동기화 구현
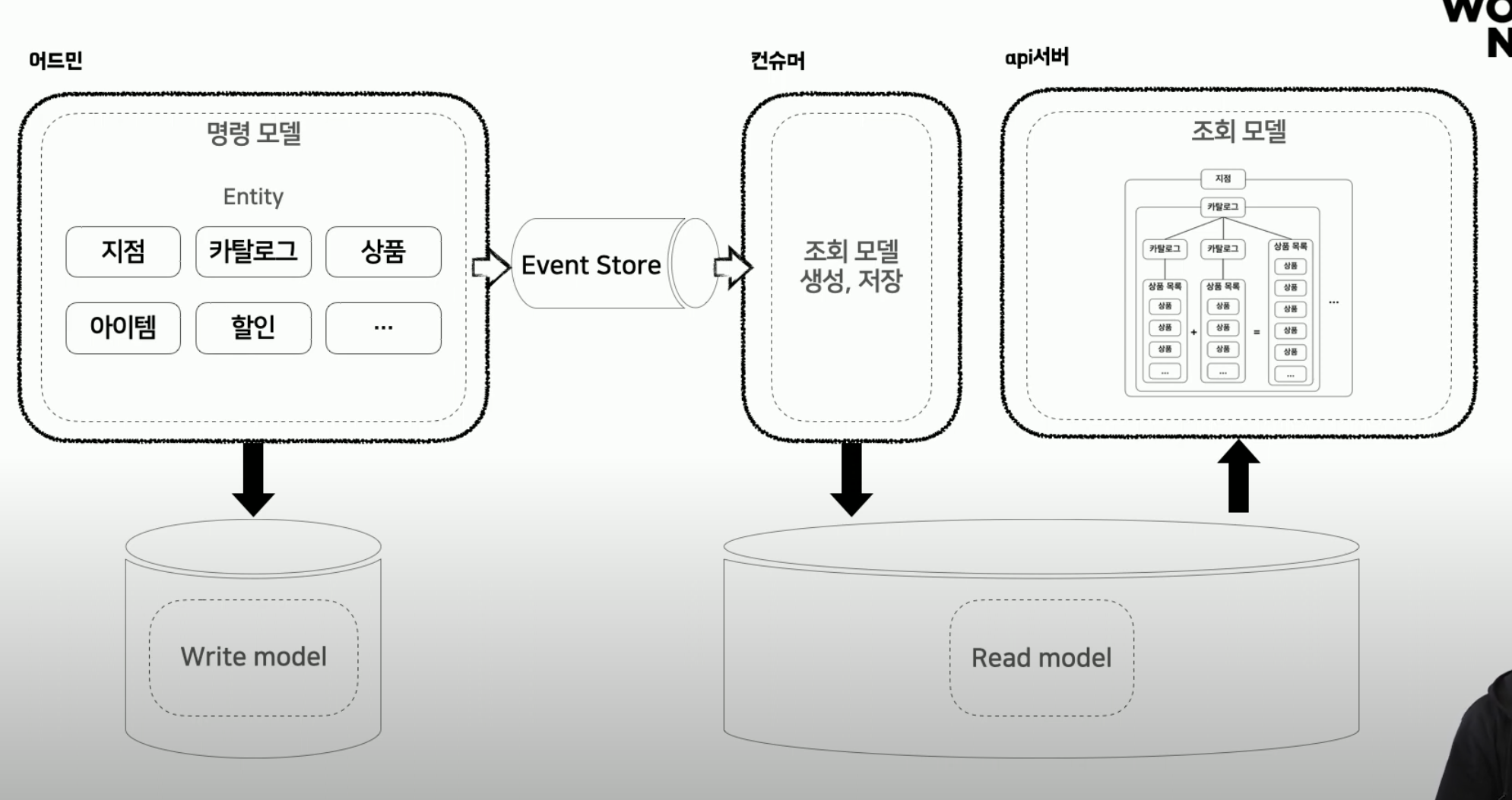
- 결과적으로 클라이언트 요구 데이터 조회 속도가 대폭 개선되었고, 캐시 관리 비용 및 장애율이 감소해 데이터 정합성이 증가하였음
펫프렌즈
- 모놀리식 구조의 한계
- 펫프렌즈 커머스팀은
Node.js기반 모놀리식 아키텍처를 운영 중이었음. - 서비스 규모가 커지면서 반복되는
Scale-Up과 코드 복잡도, 의존성, 품질 저하가 발생했고 하나의 DB 장애로 전체 서비스 마비되는SPOF문제가 있었음. - 특히 전시/상품 데이터를 하나의 DB에서 관리하기 때문에 “상품 목록 조회 시 10개 이상 테이블 JOIN”이라는 구조적 한계가 존재.
- 펫프렌즈 커머스팀은
- CQRS 도입 목적과 설계 방향
- 설계 방향을 고려하며 서비스에는 아래 3가지의 요구사항이 존재함
- 전시/상품 데이터는 분리되어 별도로 관리 되어야 한다.
- 관리자 페이지와 배치 시스템은 수정하지 않는다.
- 변경된 데이터는 실시간 반영되어야 한다.
- 위의 요구사항을 지키기 위한 3가지 방법을 서비스에 적용
- CQRS 패턴을 적용하여 Command / Query 역할 분리.
- Kafka CDC 를 이용하여 데이터 변경을 감지하고 실시간으로 반영할 이벤트 파이프라인 구축.
- 기존 시스템과의 정합성을 유지하며 점진적 MSA 전환 구조 설계
- 결과
- 성능 측정 결과 기존 시스템에 비해 개선된 시스템은 모든 지표가 3배 개선 되는 성과
- 조회를 위한 10개 테이블 JOIN 의 복잡한 쿼리문 개선
- DB 의 트래픽 분산으로 부하를 저감하였음
어떻게 사용할까?
다음은 이벤트 드리븐 방식의 설계 예시이다.(https://github.com/Kkaekkae/basic6-elk-cqrs)
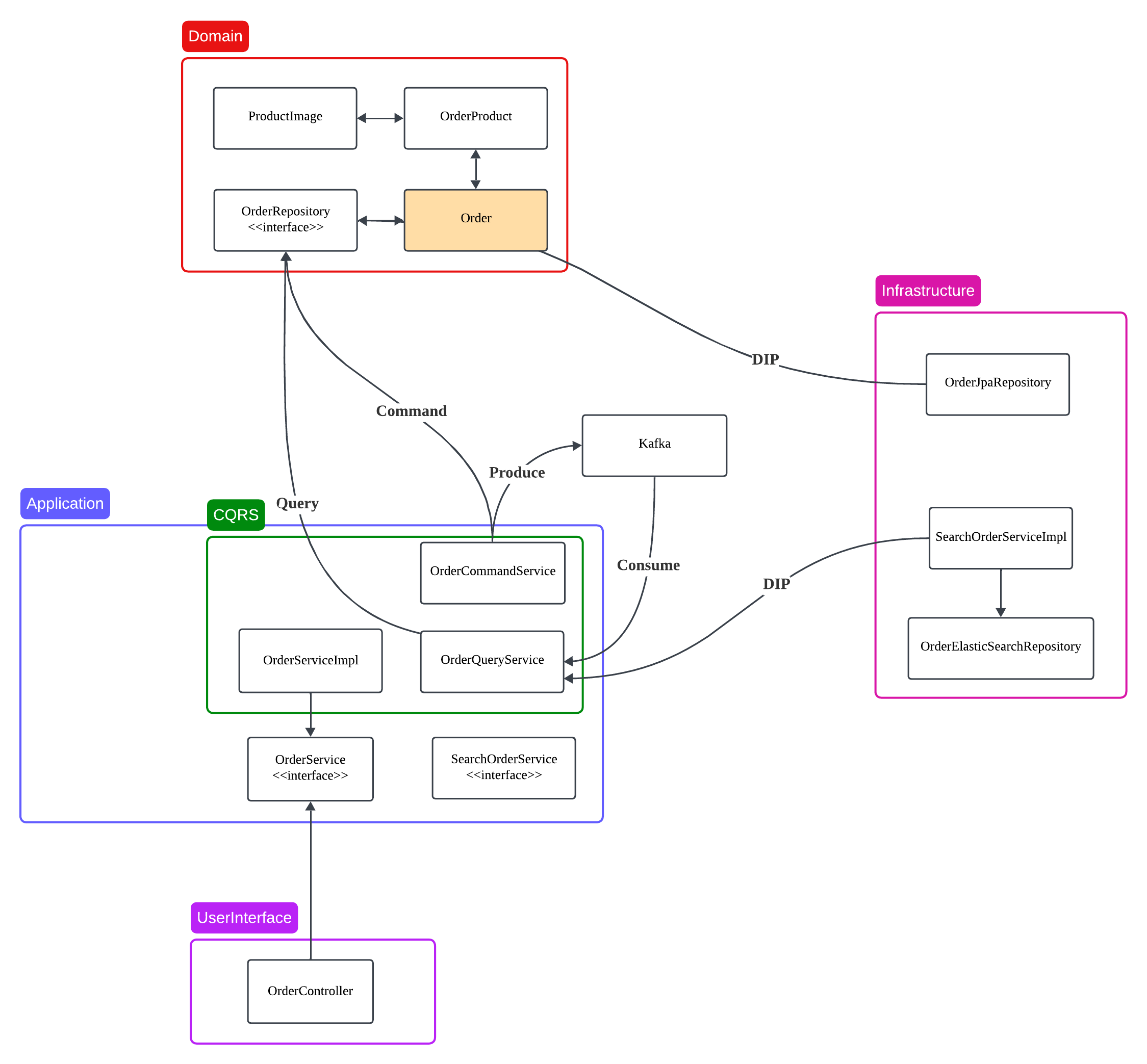
기존에는 다음과 같이 설계를 해왔다.
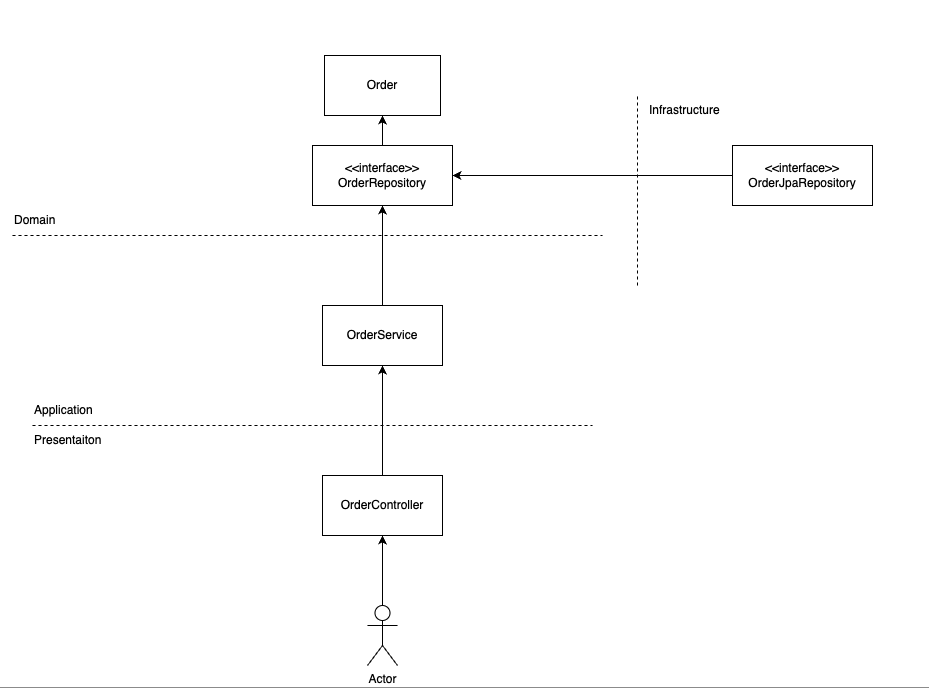
위 두 이미지의 차이점은 드리븐 방식에서 Order 쪽이 굉장히 분리되어 있다.
OrderService를 인터페이스로 두고 구현체를 분리- OrderController가
Command,Query서비스를 직접 알 필요 없이 OrderService 만 의존하게 해 계층 간 결합도를 낮출 수 있다.
- OrderController가
- 조회용 객체
SearchOrder를 Application 계층에 위치- DDD 에서 도메인 모델은
도메인 규칙을 가지고 있는 객체라고 이야기 하고 있기 때문에 도메인 규칙을 갖지 않는 단순 조회 DTO는 Domain 계층에 두지 않는 게 DDD 원칙에 부합
- DDD 에서 도메인 모델은
- 명령/조회용 Repository 분리
- 조회 성능을 위해 다른 DB(예: Elasticsearch, MongoDB)를 사용하는 경우에 유연하게 대응할 수 있도록 Repository 를 분리하는 것이 적합
CQRS를 적용할 때 고려해야 할 점
CQRS는 조회 성능을 크게 향상시키고, 복잡한 조회 로직을 단순화할 수 있는 장점이 있지만, 그만큼 시스템의 복잡도와 운영 부담이 증가하는 패턴이다. 따라서 모든 서비스에 무조건 적용하기보다는, 아래와 같은 사항들을 충분히 고려한 후 선택적으로 적용하는 것이 중요합니다.
- 조회 모델 데이터 동기화 문제
- CQRS에서는 쓰기 모델과 조회 모델이 분리되기 때문에, 쓰기 작업이 발생할 때마다 조회 모델에도 동일한 데이터가 반영되도록 동기화가 필요
- 그래서 만약 조회 모델 업데이트를 쓰기 트랜잭션 내부에서 함께 처리할 경우 트랜잭션이 길어지고, 쓰기 성능 저하 및 병목이 발생하는 문제가 발생할 수 있음
- 그래서 많은 서비스들은 이벤트 기반 비동기 방식으로 조회 모델을 업데이트 하고 있지만 이때 발생하는 가장 중요한 문제는 데이터 불일치 가능성이다.
- 예를 들어, 쓰기 모델에는 데이터가 정상적으로 저장되었지만 조회 모델에는 아직 반영되지 않았다면, 사용자는 최신 데이터를 조회하지 못하는 상황이 발생할 수 있다.
- 따라서 CQRS를 적용할 때는 이러한 최종 일관성을 허용할 수 있는지 반드시 고려해야 한다.
- 데이터 중복
- CQRS에서는 쓰기 모델과 조회 모델이 분리되어 있기 때문에, 데이터가 즉시 반영되지 않고 일정 지연이 발생할 수 있다.
- 따라서 CQRS를 적용할 때는 이러한 최종 일관성을 허용할 수 있는지 반드시 고려해야 한다.
- CQRS에서는 조회 성능을 높이기 위해 데이터를 중복 저장하는 경우가 많다.
- 예를 들어, Company 조회 모델에 User 이름과 Hub 이름을 함께 저장하면, 조회 시 별도의 JOIN이나 API 호출 없이 빠르게 데이터를 가져올 수 있다.
- 하지만 이 방식은 다음과 같은 단점을 가진다.
- 동일 데이터가 여러 곳에 존재하게 됨
- 데이터 변경 시 여러 모델을 함께 업데이트해야 함
- CQRS는 정규화된 구조를 일부 포기하고 성능을 얻는 방식이라고 볼 수 있다.
조회 DB에 데이터를 동기화 시키는 방법
CQRS 구조에서는 쓰기 모델(Write Model)과 조회 모델(Read Model)이 완전히 분리되어 운영된다.
이로 인해, 쓰기 모델에서 발생한 데이터 변경 사항을 조회 모델에 정확하고 빠르게 반영하는 것 이 시스템의 신뢰성과 성능에 핵심이 된다. 이를 위한 대표적인 결과적 일관성을 지키는 동기화 방식은 아래 3가지가 있습니다.
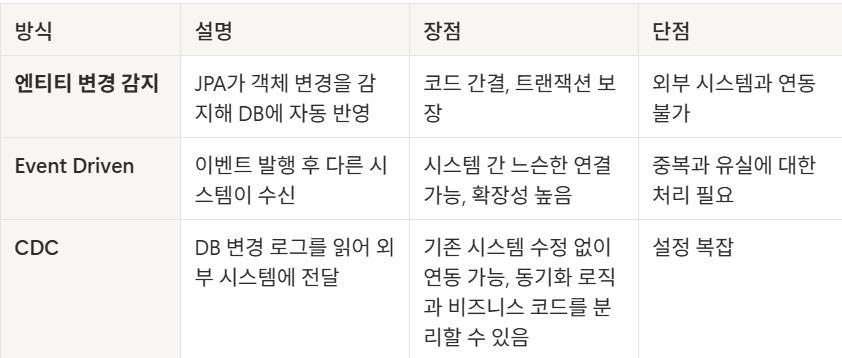
엔티티 객체 변경 감지
엔티티 객체 변경 감지는 JPA와 같은 ORM 환경에서 사용할 수 있다. 애플리케이션 내부에서 엔티티 객체의 상태가 바뀌었는지를 감지하고 그에 따라 동기화(주로 DB 반영)를 수행하는 방식이다.
이 방식은 JPA 내부 처리에 국한되며, 외부 시스템이나 별도 조회용 DB(예: Elasticsearch)로 동기화하려면 직접 구현 로직이 필요합니다. 그래서 대규모 시스템보다는 단일 시스템 또는 간단한 내부 조회 뷰에 주로 사용됩니다.
- Jpa EntityListener
@PrePersist,@PostPersist,@PreUpdate등의 어노테이션을 사용하여 엔티티 값에 변경이 일어날 경우 조회용 DB에 정보를 저장
- Hibernate EventListener
- Hibernate 의 EventListenerRegistry 를 사용하면 엔티티 객체 변경에 대한 이벤트를 콜백 받고,조회용 DB에 정보를 저장
- Spring AOP
- Spring AOP 의
@Around어노테이션을 사용하여 Repository 의 After 이벤트를 수신하고, 조회용 DB에 정보를 저장
- Spring AOP 의
이벤트 기반(Event Driven)
이벤트 기반(Event-Driven) 동기화란, 시스템 간의 데이터나 상태를 이벤트를 통해 비동기적으로 전달하고 동기화하는 방식을 말한다. Kafka, RabbitMQ, Amazon SQS 등의 기술로 다양하게 구현할 수 있습니다.
단점으로는, 이벤트 수신이 실패할 경우 유실을 방지하기 위해 Retry, DLQ (Dead Letter Queue) 와 같은 재시도 전략을 추가해야 한다.
@Service
@RequiredArgsConstructor
public class OrderService {
private final ApplicationEventPublisher publisher;
private final OrderRepository orderRepository;
@Transactional
public void createOrder(CreateOrderRequest request) {
Order order = new Order(...);
orderRepository.save(order);
publisher.publishEvent(new OrderCreatedEvent(order));
}
}
@Component
@RequiredArgsConstructor
public class ApplicationEventPublisher {
private final KafkaTemplate<String, OrderCreatedEvent> kafkaTemplate;
// 데이터 불일치를 방지하기 위해 트랜잭션이 커밋된 이후에만 실행하도록 설정
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handle(OrderCreatedEvent event) {
kafkaTemplate.send("order-created", event);
}
}
이후 Listener에서 이벤트를 받아 조회용 DB에 저장한다.
CDC(Change Data Capture)
CDC 는 데이터베이스의 데이터 변경 사항(Insert, Update, Delete)을 실시간으로 감지하고, 이를 외부 시스템으로 전달하는 기술 또는 패턴을 말한다.
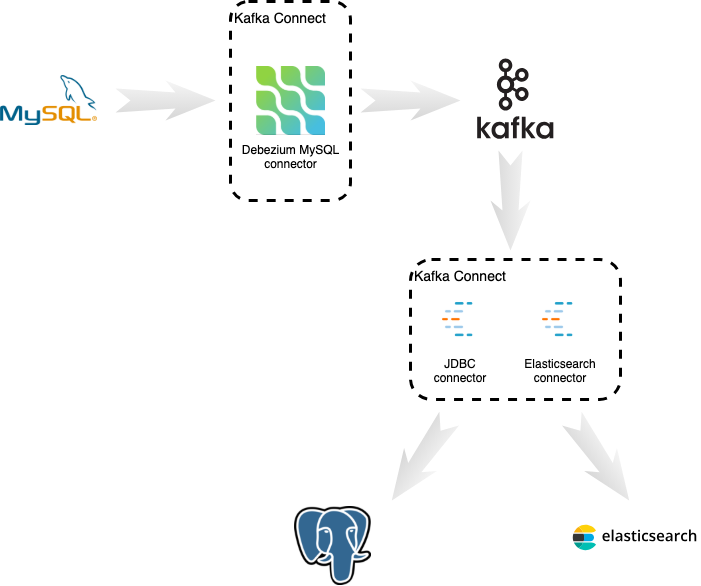
대표적으로는, Debezium을 사용하여 MySQL의 binlog를 읽고, kafka-connect 를 통해 Kafka로 변경 이벤트를 전송하여 Elasticsearch 또는 MongoDB로 데이터를 동기화 하는 방식입니다.
가장 강력하고 안전한 동기화 방식이지만, 설정이 복잡하고 관리가 어렵다는 단점이 있습니다.
정리
CQRS를 적용할 때 반드시 NoSQL을 사용해야 하는 것은 아니다. CQRS는 명령과 조회의 책임을 분리하여 각 측면을 독립적으로 최적화 할 수 있도록 설계된 아키텍처 패턴이다. 이 과정에서 조회 성능 향상이나 복잡한 데이터를 효율적으로 읽기 위해 NoSQL(예: MongoDB, Elasticsearch 등)을 도입하는 경우가 많지만, 이는 선택 사항일 뿐 필수는 아니다.
실제로는 관계형 데이터베이스(RDB) 내에서도 CQRS를 적용할 수 있으며, 조회 전용 인덱스 또는 별도 스키마로도 충분히 분리 효과를 누릴 수 있다.. 따라서 CQRS는 저장소의 종류보다 역할의 분리에 초점을 둔 설계 방식으로 보는 것이 맞다.
CQRS를 적용한다고 해서 무조건 성능이 향상되는 것은 아니다. 단일 테이블 중심의 단순 CRUD 서비스나, 조회 요구사항이 단순한 경우에는 CQRS를 적용했을 때 오히려 구조 복잡도와 운영 비용만 증가할 수 있다.
또한 CQRS는 쓰기 모델과 조회 모델이 분리되기 때문에, 데이터가 즉시 반영되지 않는 최종 일관성(Eventual Consistency) 특성을 가지기에 CQRS는 단순한 성능 최적화 기법이 아니라, 복잡한 조회 요구사항과 높은 트래픽을 해결하기 위한 아키텍처적 선택으로 접근해야 한다.
댓글남기기