데이터베이스 구축 2장 물리 데이터베이스 설계
Updated:
트랜잭션 분석/ CRUD 분석
트랜잭션(Transaction) 정의
트랜잭션은 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미한다. 트랜잭션은 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위로 사용된다. 트랜잭션은 사용자가 시스템에 대한 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업 단위로 사용된다.
트랜잭션의 상태
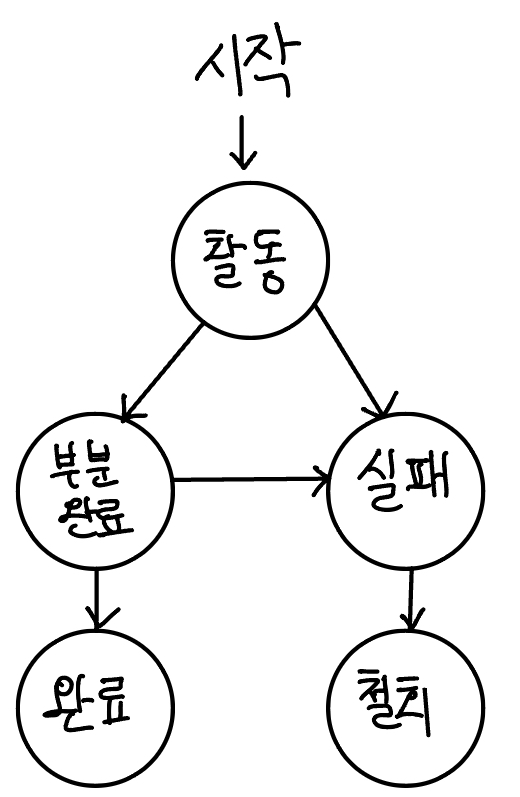
- 활동(Active): 트랜잭션이 실행 중인 상태이다.
- 실패(Failed): 트랜잭션 실행에 오류가 발생하여 중단된 상태이다.
- 철회(Aborted): 트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태이다.
- 부분 완료(Partially Committed): 트랜잭션을 모두 성공적으로 실행한 후 Commit 연산이 실행되기 직전인 상태이다.
- 완료(Committed): 트랜잭션을 모두 성공적으로 실행한 후 Commit 연산을 실행한 후의 상태이다.
트랜잭션의 특성
다음은 데이터의 무결성(Integrity)을 보장하기 위하여 DBMS의 트랜잭션이 가져야할 특성이다.
- Atomicity(원자성)
- 트랜잭션의 연산은 데이터베이스에 모두 반영되도록 완료(Commit)되든지 아니면 전혀 반영되지 않도록 복구(Pollback)되어야 한다.
- 트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 모두가 완벽히 수행되지 않고 어느 하나라도 오류가 발생하면 트랜잭션 전부가 취소되어야 한다.
- Consistency(일관성)
- 트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환한다.
- 시스템이 가지고 있는 고정 요소는 트랜잭션 수행 전과 트랜잭션 수행 완료 후의 상태가 같아야 한다.
- Isolation(독립성, 격리성, 순차성)
- 둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없다.
- 수행중인 트랜잭션은 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없다.
- Durability(영속성, 지속성)
- 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 한다.
CRUD 분석
CRUD는 ‘생성(Create), 읽기(Read), 갱신(Update), 삭제(Delete)’의 앞 글자만 모아서 만든 용어이며, CRUD 분석은 데이터베이스 테이블에 변화를 주는 트랜잭션의 CRUD 연산에 대해 CRUD 매트릭스를 작성하여 분석하는 것이다.
- CRUD 분석으로 테이블에 발생되는 트랜잭션의 주기별 발생 횟수를 파악하고 연관된 테이블들을 분석하면 테이블에 저장되는 데이터의 양을 유추할 수 있다.
- CRUD 분석을 통해 많은 트랜잭션이 몰리는 테이블을 파악할 수 있으므로 디스크 구성 시 유용한 자료로 활용할 수 있다.
- CRUD 분석을 통해 외부 프로세스 트랜잭션의 부하가 집중되는 데이터 베이스 채널을 파악하고 분산시킴으로써 연결 지연이나 타임아웃 오류를 방지할 수 있다.
CRUD 매트릭스
CRUD 매트릭스는 2차원 형태의 표로서, 행(Row)에는 프로세스를, 열(Column)에는 테이블을, 행과 열이 만나는 위치에는 프로세스가 테이블에 발생시키는 변화를 표시하는 업무 프로세스와 데이터 간 상관 분석표이다. CRUD 매트릭스를 통해 프로세스의 트랜잭션이 테이블에 수행하는 작업을 검증한다.
CRUD 매트릭스의 각 셀에는 Create, Read, Update, Delete의 앞 글자가 들어가며, 복수의 변화를 줄 때는 기본적으로 ‘C > D > U > R’의 우선순위를 적용하여 한가지만 적지만, 활용 목적에 따라 모두 기록할 수 있다. CRUD 매트릭스가 완성되었다면 C, R, U, D 중 어느 것도 적히지 않은 행이나 열, C나 R이 없는 열을 확인하여 불필요하거나 누락된 테이블 또는 프로세스를 찾는다.
트랜잭션 분석
트랜잭션 분석의 목적은 CRUD 매트리스를 기반으로 테이블에 발생하는 트랜잭션 양을 분석하여 테이블에 저장되는 테이터의 양을 유추하고 이를 근거로 DB 용량을 산정하고 DB 구조를 최적화하는 것이다. 트랜잭션 분석은 업무 개발 담장자가 수행한다. 트랜잭션 분석을 통해 프로세스가 과도하게 접근하는 테이블을 확인하여 여러 디스크에 배치함으로써 디스크 입•출력 분산을 통한 성능 향상을 가져올 수 있다.
트랜잭션 분석서
트랜잭션 분석서는 단위 프로세스와 CRUD 매트릭스를 이용하여 작성하며, 구성 요소에는 단위 프로세스, CRUD 연산, 테이블명, 컬럼명, 테이블 참조 횟수, 트랜잭션 수, 발생 주기 등이 있다.
- 단위 프로세스: 업무를 발생시키는 가장 작은 단위의 프로세스
- CRUD 연산: 프로세스의 트랜잭션이 데이터베이스 테이블에 영향을 주는 C, R, U, D의 4가지 연산
- 테이블명, 컬럼명: 프로세스가 접근하는 데이터베이스의 테이블명을 기록한다. 필요한 경우 테이블의 컬러명을 적는다. 컬럼영을 적을 때는 마침표로 연결하여 ‘테이블.컬럼명’과 같이 적는다.
- 테이블 참조 횟수: 프로세스가 테이블을 참조하는 횟수
- 트랜잭션 수: 주기별로 수행되는 트랜잭션 수
- 발생 주기: 연, 분기, 월, 일, 시간 등 트랜잭션 횟수를 측정하기 위한 발생 주기
인덱스 설계
인덱스(Index)의 개요
인덱스는 데이터 레코드를 빠르게 접근하기 위해 <키 값, 포인터> 쌍으로 구성되는 데이터 구조이다.
- 인덱스는 데이터가 저장된 물리적 구조와 밀접한 관계가 있다.
- 인덱스는 레코드가 저장된 물리적 구조에 접근하는 방법으로 제공한다.
- 인덱스를 통해서 파일의 레코드에 대한 액세스를 빠르게 수행할 수 있다.
- 레코드의 삽입과 삭제가 수시로 일어나는 경우에는 인덱스의 개수를 최소로 하는것이 효율적이다.
- 데이터 정의어(DDL)를 이용하여 사용자가 생성, 변경, 제거할 수 있다.
- 인덱스가 없으면 특정한 값을 찾기 위해 모든 데이터 페이지를 학인하는 TABLE SCAN이 발행한다.
- 기본키를 위한 인덱스를 기본 인덱스라 하고, 기본 인덱스가 아닌 인덱스들을 봉조 인덱스라고 한다. 대부분의 관계형 데이터베이스 관리 시스템에서 모든 기본키에 대해서 자동적으로 기본 인덱스를 생성한다.
- 레코드의 물리적 순서가 인덱스의 엔트리 순서와 일치하게 유지되도록 구성되는 인덱스를 믈러스터드(Clustered) 인덱스라고 한다.
- 인덱스는 인덱스를 구성하는 구조나 특징에 따라 트리 기반 인덱스, 비트맵 인덱스, 함수 기반 인덱스, 비트맵 조인 인덱스, 도메인 인덱스 등으로 분류된다.
트리 기반 인덱스
트리 기반 인덱스는 인덱스를 저장하는 블록들이 트리 구조를 이루고 있는 것으로, 상용 DBMS에서는 트리 구조 기반의 B+ 트리 인덱스를 주로 활용한다.
- B 트리 인덱스
- 일반적으로 사용되는 인덱스 방식으로, 루트 노드에서 하위 노드로 키 값의 크기를 비교해 나가면서 단말 노드에서 찾고자 하는 데이터를 검색한다.
- 키 값과 레코드를 가리키는 포인터들이 트리 노드에 오름차순으로 저장된다.
- 모든 리프 노드는 같은 레벨에 있다.
- 브랜치 블록(Branch Block)과 리프 블록(Leaf Block)으로 구성된다.
- 브랜치 블록: 분기를 위한 목적으로 사용되고, 다음 단계를 가리키는 포인터를 가지고 있음
- 리프 블록: 인덱스를 구성하는 컬럼 데이터와 해당 데이터의 행 위치를 가리키는 레코드 식별자로 구성됨
- B+ 트리 인덱스
- B+ 트리는 B 트리의 변형으로 단말 노드가 아닌 노드로 구성된 인덱스 세트(Index Set)와 단말 노드로만 구성된 순차 세트(Sequence Set)로 구분된다.
- 인덱스 세트에 있는 노드들은 단말 노드에 있는 키 값을 찾아갈 수 있는 경로로만 제공되며, 순차 세트에 있는 단말 노드가 해당 데이터 레코드의 주소를 가리킨다.
- 인덱스 세트에 있는 모든 키 값이 단말 노드에 다시 나타나므로 단말 노드만을 이용한 순차 처리가 가능하다.
비트맵 인덱스
비트맵 인덱스는 인덱스 컬럼의 데이터를 Bit 값인 0 또는 1로 변환하여 인덱스 키로 사용하는 방법이다. 비트맵 인덱스의 목적은 키 값을 포함하는 로우(Row)의 주소를 제공하는 것이다. 비트맵 인덱스는 분포도가 좋은 컬럼에 적합하며, 성능 향상 효과를 얻을 수 있다.
데이터가 Bit로 구성되어 있기 때문에 효율적인 논리 연산이 가능하고 저장 공간이 작다. 비트맵 인덱스는 다중 조건을 만족하는 튜플의 개수 계산에 적합하고 동일한 값이 반복되는 경우가 많아 압축 효율이 좋다.
함수 기반 인덱스
함수 기반 인덱스는 컬럼의 값 대신 컬럼에 특정 함수(Function)나 수식(Expression)을 적용하여 산출된 값을 사용하는 것으로, B+ 트리 인덱스 또는 비트맵 인덱스를 생성하여 사용한다. 함수 기반 인덱스는 데이터를 입력하거나 수정할 때 한수를 적용해야 하므로 부하가 발생할 수 있다. 사용된 함수가 사용자 정의 함수일 경우 시스템 함수보다 부하가 더 크다. 함수 기반 인덱스는 대소문자, 띄어쓰기 등에 상관없이 조회할 때 유용하게 사용된다.
적용 가능한 함수의 종류는 산술식(Arithmetic Expression), 사용자 정의 함수, PL/SQL Function, SQL Function, Package, C callout 등이 있다.
비트맵 조인 인덱스
비트맵 조인 인덱스는 다수의 조인된 객체로 구성된 인덱스로, 단일 객체로 구성된 일반적인 인덱스와 액세스 방법이 다르다. 배트맵 조인 인덱스는 비트맵 인덱스와 물리적 구조가 동일하다.
도메인 인덱스
도메인 인덱스는 개발자가 필요한 인덱스를 직접 만들어 사용하는 것으로, 확장형 인덱스(Extensible Index)라고도 한다. 개발자가 필요에 의해 만들었지만 프로그램에서 제공하는 인덱스처럼 사용할 수 도 있다.
인덱스 설계
인덱스를 설계할 때는 분명하게 드러난 컬럼에 대해 기본적인 인덱스를 먼저 지정한 후 개발 단계에서 필요한 인덱스의 설계를 반복적으로 진행한다. 인덱스 설계 순서는 다음과 같다.
- 인덱스의 대상 테이블이나 컬럼 등을 선정한다.
- 인덱스의 효율성을 검토하여 인덱스 최적화를 수행한다.
- 인덱스 정의서를 작성한다.
인덱스 대상 테이블 선정 기준
- MULTI BLOCK READ 수에 따라 판단
- 랜덤 액세스가 빈번한 테이블
- 특정 범위나 특정 순서로 데이터 조회가 필요한 테이블
- 다른 테이블과 순차적 조인이 발생되는 테이블
인덱스 대상 컬럼 선정 기준
- 인덱스 컬럼의 분포도가 10~15% 이내인 컬럼
- 분포도 = (컬럼값의 평균 Row 수 / 테이블의 총 Row 수) * 100
- 분포도가 10~15% 이상이어도 부분 처리를 목적으로 하는 컬럼
- 입•출력 장표 등에서 조회 및 출력 조건으로 사용되는 컬럼
- 인덱스가 자동으로 생성되는 기본키와 Unique키 제약 조건을 사용한 컬럼
- ORDER BY, GROUP BY, UNION 이 빈번한 컬럼
- 분포도가 좁은 컬럼은 단독 인덱스로 생성
- 인덱스들이 자주 조합되어 사용되는 경우 하나의 결합 인덱스(Concatenate Index)로 생성
인덱스 설계 시 고려사항
- 새로 추가되는 인덱스는 기존 액세스 경로에 영향을 미칠 수 있다.
- 인덱스를 지나치게 많이 만들면 오버헤드가 발생한다.
- 넓은 범위를 인덱스로 처리하면 많은 오버헤드가 발생한다.
- 인덱스를 만들면 추가적인 저장 공간이 필요하다.
- 인덱스와 테이블 데이터의 저장 공간이 분리되도록 설계한다.
뷰(View) 설계
뷰(View)의 개요
뷰는 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블이다. 뷰는 저장장치 내에 물리적으로 존재하지 않지만, 사용자에게는 있는 것처럼 간주된다.
뷰는 데이터 보정 작업, 처리 과정 시험 등 임시적인 작업을 위한 용도로 활용되며 조인문의 사용 최소화로 사용상의 편의성을 최대화한다. 뷰를 생성하면 뷰 정의가 시스템 내에 저장되었다가 생성된 뷰 이름을 질의어(SQL)에서 사용할 경우 질의어가 실행될 때 뷰에 정의된 기본 테이블로 대체되어 기본 테이블에 대해 실행된다.
뷰의 특징
- 뷰는 기본 테이블로부터 유도된 테이블이기 때문에 기본 테이블과 같은형태의 구조를 사용하며, 조작도 기본 테이블과 거의 같다.
- 뷰는 가상 테이블이기 때문에 물리적으로 구현되어 있지 않다.
- 데이터의 논리적 독립성을 제공할 수 있다.
- 필요한 데이터만 뷰로 정의해서 처리할 수 있기 때문에 관리가 용이하고 명령문이 간단해진다.
- 뷰를 통해서만 데이터에 접근하게 하면 뷰에 나타나지 않는 데이터를 안전하게 보호하는 효율적인 기법으로 사용할 수 있다.
- 기본 테이블의 기본키를 포함한 속성(열) 집합으로 뷰를 구성해야만 삽입, 삭제, 갱신 연산이 가능하다.
- 일단 정의된 뷰는 다른 뷰의 정의에 기초가 될 수 있다.
- 뷰가 정의된 기본 테이블이나 뷰를 삭제하면 그 테이블이나 뷰를 기초로 정의된 다른 뷰도 자동으로 삭제된다.
- 뷰를 정의할 때는 CREATE문, 제거할 때는 DROP문을 사용한다.
뷰의 장•단점
- 장점
- 논리적 데이터 독립성을 제공한다.
- 동일 데이터에 대해 동시에 여러 사용자의 상이한 응용이나 요구를 지원해 준다.
- 사용자의 데이터 관리를 간단하게 해준다.
- 접근 제어를 통한 자동 보안이 제공된다.
- 단점
- 독립적인 인덱스를 가질 수 없다.
- 뷰의 정의를 변경할 수 없다.
- 뷰로 구성된 내용에 대한 삽입, 삭제, 갱신 연산에 제약이 따른다.
뷰 설계 순서
- 대상 테이블을 선정한다.
- 외부 시스템과 인터페이스에 관여하는 테이블
- CRUD 매트릭스를 통해 여러 테이블이 동시에 자주 조인되어 접근되는 테이블
- SQL문 작성 시 거의 모든 문장에서 인라인 뷰 방식으로 접근되는 테이블
- 대상 컬럼을 선정한다.
- 보안을 유지해야 하는 컬럼은 주의하여 선별한다.
- 정의서를 작성한다.
뷰 설계 시 고려 사항
- 테이블 구조가 단순화 될 수 있도록 반복적으로 조인을 설정하여 사용하거나 동일한 조건절을 사용하는 테이블을 뷰로 사용한다.
- 동일한 테이블이라도 업무에 따라 테이블을 이용하는 부분이 달라질 수 있으므로 사용할 데이터를 다양한 관점에서 제시해야 한다.
- 데이터의 보안 유지를 고려하여 설계한다.
파티션 설계
파티션(Patition)의 개요
데이터베이스에서 파티션은 대용량의 테이블이나 인덱스를 작은 논리적 단위인 파티션으로 나누는 것을 말한다. 대용량 DB의 경우 중요한 몇 개의 테이블에만 집중되어 데이터가 증가되므로, 이런 테이블들을 작은 단위로 나눠 분산시키면 성능 저하를 방지할 뿐만 아니라 데이터 관리도 쉬워진다.
테이블이나 인덱스를 파티셔닝 하면 파티션키 또는 인덱스키에 따라 물리적으로 별도의 공간에 데이터가 저장된다. 데이터 처리는 테이블 단위로 이뤄지고, 데이터 저장은 파티션 별로 수행된다.
파티션의 장•단점
- 장점
- 데이터 접근 시 액세스 범위를 줄여 쿼리 성능이 향상된다.
- 파티션별로 데이터가 분산되어 저장되므로 디스크의 성능이 향상된다.
- 파티션별로 백업 및 복구를 수행하므로 속도가 빠르다.
- 데이터 가용성이 향상된다.
- 파티션 단위로 입•출력을 분산시킬 수 있다.
- 단점
- 하나의 테이블을 세분화하여 관리하므로 세심한 관리가 요구된다.
- 테이블간 조인에 대한 비용이 증가한다.
- 용량이 작은 테이블에 파티셔닝을 수행하면 오히려 성능이 저하된다.
파티션의 종류
- 범위 분할(Range Partitioning)
- 지정한 열의 값을 기준으로 범위를 지정하여 분할한다.
- 해시 분할(Hash Partitioning)
- 해시 함수를 적용한 결과 값에 따라 데이터를 분할한다.
- 특정 파티션에 데이터가 집중되는 범위 분할의 단점을 보완한 것으로, 데이터를 고르게 분산할 때 유용하다.
- 특정 데이터가 어디 있는지 판단할 수 있다.
- 고객번호, 주민번호 등과 같이 데이터가 고른 컬럼에 효과적이다.
- 조합 분할(Composite Partitioning)
- 범위 분할로 분할한 다음 해시 함수를 적용하여 다시 분할하는 방법이다.
- 범위 분할한 파티션이 너무 커서 관리가 어려울 때 유용하다.
- 목록 분할(List Partitioning)
- 지정한 열 값에 대한 목록을 만들어 이를 기준으로 분할한다.
- 라운드 로빈 분할(Round Robin Partitioning)
- 레코드를 균일하게 분배하는 방식이다.
- 각 레코드가 순차적으로 분배되며, 기본키가 필요없다.
파티션키 선정 시 고려사항
- 파티션키는 테이블 접근 유형에 따라 파티셔닝이 이뤄지도록 선정한다.
- 데이터 관리의 용이성을 위해 이력성 데이터는 파티션 생성주기와 소멸주기를 일치시켜야 한다.
- 매일 생성되는 날짜 컬럼, 백업의 기준이 되는 날짜 컬럼, 파티션 간 이동이 없는 컬럼, I/O 병목을 줄일 수 있는 데이터 분포가 양호한 컬럼 등을 파티션키로 선정한다.
인덱스 파티션
인덱스 파티션은 파티션된 테이블의 데이터를 관리하기 위해 인덱스를 나눈 것이다. 인덱스 파티션은 파티션된 테이블의 종속 여부에 따라 다음과 같이 나뉜다.
- Local Partitioned Index: 테이블 파티션과 인덱스 파티션이 1:1 대응되도록 파티셔닝한다.
- Global Partitioned Index: 테이블 파티션과 인덱스 파티션이 독립적으로 구성되도록 파티셔닝한다.
Local Partitioned Index가 Global Partitioned Index에 비해 데이터 관리가 쉽다.
인덱스 파티션은 인덱스 파티션키 컬럼의 위치에 따라 다음과 같이 나뉜다.
- Prefixed Partitioned Index: 인덱스 파티션키와 인덱스 첫 번째 컬럼이 같다.
- Non-Prefixed Partitioned Index: 인덱스 파티션키와 인덱스 첫 번째 컬럼이 다르다.
Local과 Global, Prefixed와 Nonprefixed를 조합하여 사용한다.
분산 데이터베이스 설계
분산 데이터베이스 정의
분산 데이터베이스는 논리적으로는 하나의 시스템에 속하지만 물리적으로는 네트워크를 통해 연결된 여러 개의 컴퓨터 사이트(Site)에 분산되어 있는 데이터베이스를 말한다. 분산 데이터베이스는 데이터의 처리나 이용이 많은 지역에 데이터베이스를 위치시킴으로써 데이터의 처리가 가능한 해당 지역에서 해결될 수 있도록 한다.
분산 데이터베이스의 구성 요소
- 분산 처리기: 자체적으로 처리 능력을 가지며, 지리적으로 분산되어 있는 컴퓨터 시스템을 말한다.
- 분산 데이터베이스: 지리적으로 분산되어 있는 데이터베이스로서 해당 지역의 특성에 맞게 데이터베이스가 구성된다.
- 통신 네트워크: 분산 처리기들을 통신망으로 연결하여 논리적으로 하나의 시스템처럼 작동할 수 있도록 하는 통신 네트워크를 말한다.
분산 데이터베이스 설계 시 고려 사항
- 자업 부하(Work Load)의 노드별 분산 정책
- 지역의 자치성 보장 정책
- 데이터의 일관성 정책
- 사이트나 회선의 고장으로부터의 회복 기능
- 통신 네트워크를 통한 원격 접근 기능
분산 데이터베이스의 목표
- 위치 투명성(Location Transparency)
- 액세스하려는 데이터베이스의 실제 위치를 알 필요 없이 단지 데이터베이스의 논리적인 명칭만으로 액세스할 수 있다.
- 중복 투명성(Replication Transparency)
- 동일 데이터가 여러 곳에 중복되어 있더라도 사용자는 마치 하나의 데이터만 존재하느 것처럼 사용하고, 시스템은 자동을 여러 자료에 대한 작업을 수행한다.
- 병행 투명성(Concurrency Transparency)
- 분산 데이터베이스와 관련된 다수의 트랜잭션들이 동시에 실현되더라도 그 태랜잭션의 결과는 영향을 받지 않는다.
- 장애 투명성(Failure Transparency)
- 트랜잭션, DBMS, 네트워크, 컴퓨터 장애에도 불구하고 트랜잭션을 정확하게 처리한다.
분산 데이터베이스의 장•단점
- 장점
- 지역 자치성이 높다.
- 자료의 공유성이 향상된다.
- 분산 제어가 가능하다.
- 시스템 성능이 향상된다.
- 중앙 컴퓨터의 장애가 전체 시스템에 영향을 끼치지 않는다.
- 효용성과 융통성이 높다.
- 신뢰성 및 가용성이 높다.
- 점진적인 시스템 용량 확장이 용이하다.
- 단점
- DBMS가 수행할 기능이 복잡하다.
- 데이터베이스 설계가 어렵다.
- 소프트웨어 개발 비용이 중기한다.
- 처리 비용이 증가한다.
- 잠재적 오류가 증가한다.
분산 데이터베이스 설계
분산 데이터베이스 걸계는 애플리케이션이나 사용자가 분산되어 저장된 데이터에 접근하게 하는 것을 목적으로 한다. 잘못 설계된 분산 데이터베이스는 복잡성 증가, 응답 속도 저하, 비용 증가 등의 문제가 발생한다. 분산 데이터베이스의 설계는 전역 관계망을 논리적 측면에서 소규모 단위로 분할한 후, 분할된 결과를 복수의 노드에 할당하는 과정으로 진행된다. 노드에 할단된 소규모 단위를 분할(Fragment)이라 부른다.
테이블 위치 분산
테이블 위치 분산은 데이터베이스의 테이블을 각기 다른 서버에 분산시켜 배치하는 방법을 의미한다. 테이블 위치를 분산할 때는 테이블의 구조를 변경하지 않으며, 다른 데이터베이스의 테이블과 중복되지 않게 배치한다. 데이터베이스의 테이블을 각각 다른 위치에 배치하려면 해당 테이블들이 놓일 서버들을 미리 설정해야 한다.
분할(Fragment)
분할은 테이블의 데이터를 분할하여 분산시키는 것이다.
- 분할 규칙
- 완전성(Completeness): 전체 데이터를 대상으로 분할해야 한다.
- 재구성(Reconstruction): 분할된 데이터는 관계 연산을 활용하여 본래의 데이터로 재구성할 수 있어야 한다.
- 상호 중첩 배제(Dis-jointness): 분할된 데이터는 서로 다른 분할의 항목에 속하지 않아야 한다.
주요 분할 방법은 다음과 같다.
- 수평 분할: 특정 속성의 값을 기준으로 행(Row) 단위로 분할
- 수직 분할: 데이터 컬럼(속성) 단위로 분할
할당(Allocation)
할당은 동일한 분할을 여러 개의 서버에 생성하는 분산 방법으로, 중복이 없는 할당과 중복이 있는 할당으로 나뉜다.
- 비중복 할당 방식
- 최적의 노드를 선택해서 분산 데이터베이스의 단일 노드에서만 분할이 존재하도록 하는 방식이다.
- 일반적으로 애플리케이션에는 릴레이션을 배타적 분할로 분리하기 힘든 요구가 포함되므로 분할된 테이블 간의 의존성은 무시하고 비용 증가, 성능 저하 등의 문제가 발생할 수 있다.
- 중복 할당 방식
- 동일한 테이블을 다른 서버에 복제하는 방식으로, 일부만 복제하는 부분 복제와 전체를 복제하는 완전 복제가 있다.
데이터베이스 보안/암호화
데이터베이스 보안의 개요
데이터베이스 보안이란 데이터베이스의 일부분 또는 전체에 대해서 권한이 없느 사용자가 액세스하는 것을 금지하기 위해 사용되는 기술이다. 보안을 위한 데이터 단위는 테이블 전체로부터 특정 테이블의 특정한 행과 열 위치에 있는 특정한 데이터 값에 이르기까지 다양하다. 데이터베이스 사용자들은 일반적으로 서로 다른 객체에 대하여 다른 접근 권리 또는 권한을 갖게 된다.
암호화(Encryption)
암호화는 데이터를 보낼 때 송수신자가 지정한 수신자 이외에는 그 내용을 알 수 없도록 평문을 암호문으로 변환하는 것이다.
- 암호화(Encryption) 과정: 암호화되지 않은 평문을 정보 보호를 위해 암호문으로 바꾸는 과정
- 복호화(Decryption) 과정: 암호문을 원래의 평문으로 바꾸는 과정
- 암호화 기법에는 개인키 암호 방식과 공개키 암호 방식이 있다.
개인키 암호 방식(Private Key Encryption), 비밀키 암호 방식
비밀키 암호화 기법은 동일한 키로 데이터를 암호화하고 복호화한다. 비밀키 암호화 기법은 대칭 암호 방식 또는 단일키 암호화 기법이라고도 한다. 비밀키는 제3자에게는 노출시키지 않고 데이터베이스 사용 권한이 있는 사용자만 나누어 가진다.
종류에는 전위 기법, 대체 기법, 대수 기법, 합성 기법(DES,LUCIFER)가 있다.
공개키 암호 방식(Public Key Encryption)
공개키 암호 방식은 서로 다른 키로 데이터를 암호화하고 복호화한다. 데이터를 암호화할 때 사용하는 키(공개키, Public Key)는 데이터베이스 사용자에게 공개하고, 복호화할 떄의 키(비밀키, Secret Key)는 관리자가 비밀리에 관리하는 방법이다. 공개키 암호화 기법은 비대칭 암호 방식이라고도 하며, 대표적으로 RSA(Rivest Sharmir Adleman)가 있다.
데이터베이스 보안- 접근 통제
접근 통제
접근 통제는 데이터가 저장된 객체와 이를 사용하려는 주체사이의 정보 흐름을 제한하는 것이다. 접근통제는 데이터에 대해 다음과 같은 통제를 함으로써 자원의 불법적인 접근 및 파괴를 예방한다.
- 비인가된 사용자의 접근 감시
- 접근 요구의 정당성 확인 및 기록
- 보안 정책에 근거한 접근의 승인 및 거부 등
- 접근 요구자의 사용자 식별
접근통제 기술은 다음과 같다.
- 임의 접근통제(DAC; Discretionary Access Control)
- 임의 접근통제는 데이터에 접근하는 사용자의 신원에 따라 접근 권한을 부여하는 방식이다.
- 데이터 소유자가 접근통제 권한을 지정하고 제어한다.
- 객체를 생성한 사용자가 생성된 객체에 대한 모든 권한을 부여받고, 부여된 권한을 다른 사용자에게 허가할 수도 있다.
- 임의 접근통제에 사용되는 SQL 명령어에는 GRANT와 REVOKE가 있다.
- 강제 접근통제(MAC; Mandatory Access Control)
- 강제 접근통제는 주체와 객체의 등급을 비교하여 접근 권한을 부여하는 방식이다.
- 시스템이 접근통제 권한을 지정한다.
- 데이터베이스 객체별로 보안 등급을 부여할 수 있고, 사용자별로 인가 등급을 부여할 수 있다.
- 주체는 자신보다 보안 등급이 높은 객체에 대해 읽기, 수정, 등록이 모두 불가능하고, 보안 등급이 같은 객체에 대해서는 읽기, 수정, 등록이 가능하고, 보안 등급이 낮은 객체는 읽기가 가능하다.
- 벨 라파듈라 모델(Bell-LaPadula Model)
- 군대의 보안 레벨처럼 정보의 기밀성에 따라 상하 관계가 구분된 정보를 보호하기 위해 사용한다.
- 보안 취급자의 등급을 기주으로 읽기 권한과 쓰기 권한이 제한된다.
- 자신의 보안 레벨 이상의 문서를 작성할 수 있고, 자신의 보안 레벨이하의 문서는 읽을 수 있다.
- 비바 무결성 모델(Biba Integrity Model)
- 벨 라파뷸라 모델을 보완한 수하적 모델로, 무결성을 보장하는 최초의 모델이다.
- 비인가자에 의한 데이터 변형을 감지힌다.
- 클락-윌슨 무결성 모델(Clark-Wilson Integrity Model)
- 무결성 중심의 상업용 모델로, 사용자가 직접 객체에 접근할 수 없고 프로그램에 의해 접근이 가능한 보한 모델이다.
- 만리장성 모델(Chinese Wall Model)
- 서로 이해 출돌 관계에 있는 객체 간의 정보 접근을 통제하는 모델이다.
- 역할기반 접근통제(RBAC; Role Based Access Control)
- 역할기반 접근통제는 사용자의 역할에 따라 접근 권한을 부여하는 방식이다.
- 중앙관리자가 접근 통제 권한을 지정한다.
- 임의 접근통제와 강제 접근통제의 단점을 보와하였으며, 다중 프로그래밍 환경에서 최적화된 방식이다.
- 중앙관리자가 역할마다 권한을 부여하면, 책임과 자질에 따라 역할을 할당받은 사용자들은 역할에 해당하는 권한을 사용할 수 있다.
접근통제의 3요소는 접근통제 정책, 접근통제 메커니즘, 접근통제 보안모델이다.
접근통제 정책
접근통제 정책은 어떤 주체(Who)가 언제(When), 어디서(Where), 어떤 객체(What)에게, 어떤 행위(How)에 대한 허용 여부를 정의하는 것으로, 신분 기반 정책, 규칙 기반 정책, 역할 기반 정책이 있다.
- 신분 기반 정책
- 주체나 그룹의 신분에 근거하여 객체의 접근을 제한하는 방법으로, IBP와 GBP가 있다.
- IBP(Individual-Based Policy): 최소 권한 정책으로, 단일 주체에게 하나의 객체에 대한 허가를 부여한다.
- GBP(Group-Based Policy): 복수 주체에 하나의 객체에 대한 허가를 부여한다.
- 규칙 기반 정책
- 주체가 갖는 권한에 근거하여 객체의 접근을 제한하는 방법으로, MLP와 CBP가 있다.
- MLP(Multi-Level Policy): 사용자 및 객체별로 지정된 기밀 분류에 따른 정책
- CBP(Compartment-Based Policy): 집단별로 지정된 기밀 허가에 따른 정책
- 역할 기반 정책
- GBP의 변형된 정책으로, 주체의 신분이 아니라 주체가 맡은 역할에 근거하여 객체의 접근을 제안하는 방법이다.
접근통제 매커니즘
접근통제 메커니즘은 정의된 접근통제 정책을 구현하는 기술적인 방법으로, 접근통제 목록, 능력 테스트, 보안 등급, 패스워드, 암호화 등이 있다.
- 접근통제 목록(Access Control List): 객체를 기준으로 특정 객체에 대해 어떤 주체가 어떤 행위를 할 수 있는지를 기록한 목록이다.
- 능력 리스트(Capability List): 주체를 기준으로 주체에게 허가된 자원 및 권한을 기록한 목록이다.
- 보안 등급(Security Level): 주체나 객체 등에 부여된 보안 속성의 집합으로, 이 등급을 기반으로 접근 승인 여부가 결정된다.
- 패스워드: 주체가 자신임을 증명할 때 사용하는 인증 방법이다.
- 암호화: 데이터를 보낼 때 지정된 수신자 이외에는 내용을 알 수 없도록 평문을 암호문으로 변환하는 것으로, 무단 도용을 방지하기 위해 주로 사용된다.
접근통제 보안모델
접근통제 보안 모델은 보안 정책을 구현하기 위한 정형화된 모델로, 기밀성 모델, 무결성 모델, 접근통제 모델이 있다.
- 기밀성 모델
- 기밀성 모델은 군사적인 목적으로 개발된 최초의 수학적 모델로, 기밀성 보장이 최우선인 모델이다.
- 기밀성 모델은 군대 시스템 등 특수한 환경에서 주로 사용된다.
- 제약 조건
- 단순 보안 규칙: 주체는 자신보다 높은 등급의 객체를 읽을 수 없다.
- ★(스타)-보안 규칙: 주체는 자신보다 낮은 등급의 객체에 정보를 쓸 수 없다.
- 강한 ★(스타) 보안 규칙: 주체는 자신과 등급이 다른 객체를 읽거나 쓸 수 없다.
- 무결성 모델
- 무결성 모델은 기밀성 모델에서 발생하는 불법적인 정보 변경을 방지하기 위해 무결성을 기반으로 개발된 모형이다.
- 무결성 모델은 데이터의 일관성 유지에 중점을 두어 개발되었다.
- 무결성 모델은 기말성 모델과 동일하게 주체 및 객체의 보안 등급을 기반으로 한다.
- 제약 조건
- 단순 무결성 규칙: 주체는 자신보다 낮은 등급의 객체를 읽을 수 없다.
- ★(스타)-무결성 규칙: 주체는 자신보다 높은 등급의 객체에 정보를 쓸 수 없다.
- 접근통제 모델
- 접근통제 모델은 접근통제 메커니즘을 보안 모델로 발전시킨 것으로, 대표적으로 접근통제 행렬(Access Control Matrix)이 있다.
- 접근통제 행렬(Access Control Matrix)
- 임의적인 접근통제를 관리하기 위한 보안 모델로, 행은 주체, 열은 객체 즉, 행과 열로 주체와 객체의 권한 유형을 나타낸다.
- 행: 주체로서 객체에 접근을 시도하는 사용자이다.
- 열: 객체로서 접근통제가 이뤄지는 테이블, 컬럼, 뷰 등과 같은 데이터베이스의 개체이다.
- 규칙: 주체가 객체에 대하여 수행하는 입력, 수정, 삭제 등의 데이터베이스에 대한 조작이다.
접근통제 조건
접근통제 조건은 접근통제 매커니즘의 취약점을 보완하기 위해 접근통제 정책에 부가하여 적용할 수 있는 조건이다.
- 값 종속 통제(Value-Dependent Control): 일반적으로는 객체에 저장된 값에 상관없이 접근통제를 동일하게 허용하지만 객체에 저장된 값에 따라 다르게 접근통제를 허용해야 하는 경우에 사용한다.
- 다중 사용자 통제(Multi-User Control): 지정된 객체에 다수의 사용자가 동시에 접근을 요구하는 경우에 사용된다.
- 컨텍스트 기반 통제(Context-Based Control): 특정 시간, 네트워크 주소, 접근 경로, 인증 수준 등에 근거하여 접근을 제어하는 방법으로, 다른 보안 정책과 결합하여 보안 시스템의 취약점을 보완할 때 사용된다.
감사 추적
감사 추적은 사용자나 애플리케이션이 데이터베이스에 접근하여 수행한 모든 활동을 기록하는 기능이다. 감사 추적은 오류가 발생한 데이터베이스를 복구하거나 부적절한 데이터 조작을 파악하기 위해 사용된다. 감사 추적 시 실행한 프로그램, 사용자, 날짜 및 시간, 접근한 데이터의 이전 값 및 이후 값 등이 저장된다.
데이터베이스 백업
데이터베이스 백업
데이터베이스 백업은 전산 장비에 대비하여 데이터베이스에 저장된 데이터를 보호하고 복구하기 위한 작업으로, 치명적인 데이터 손실을 막기 위해서는 데이터베이스를 정기적으로 백업해야한다. 데이터베이스 관리 시스템(DBMS)은 데이터베이스 파괴 및 실행 중단이 발생하면 이를 복구할 수 있는 기능을 제공한다.
데이터베이스 장애 유형
데이터베이스 장애 유형을 정확히 파악하고 장애에 따른 백업 전략을 세워야 장애 발생 시 복구가 가능하다.
- 사용자 실수: 사용자의 실수로 인해 테이블이 삭제되거나 잘못된 트랜잭션이 처리된 경우
- 미디어 장애: CPU, 메모리, 디스크 등 하드웨어 장애나 데이터가 피손된 경우
- 구문 장애: 프로그램 오류나 사용 공간의 부족으로 인해 발생하는 문제
- 사용자 프로세스 장애: 프로그램이 비정상적으로 종료되거나 네트워크 이상으로 세션이 종료되어 발생하는 오류
- 인스턴스 장애: 하드웨어 장애, 정정, 시스템 파일 파손 등 비정상적인 요인으로 인해 메모리나 데이터베이스 서버의 프로세스가 중단된 경우
로그 파일
로그 파일은 데이터베이스의 처리 내용이나 이용 상황 등 상태 변화를 시간의 흐름에 따라 모두 기록한 파일로, 데이터베이스의 복구를 위해 필요한 가장 기본적인 자료이다. 로그 파일을 기반으로 데이터베이스를 과거 상태로 복귀(UNDO)시키거나 현재 상태로 재생(REDO)시켜 데이터베이스 상태를 일관성 있게 유지할 수 있다. 로그 파일은 트랜잭션 시작 지검, Rollback 시점, 데이터 입력, 수정 삭제 시점 등에서 기록된다. 로그 파일 내용으로 트랜잭션이 작업한 모든 내용, 트랜잭션 식별, 트랜잭션 레코드, 데이터 식별자, 갱신 이전 값(Before Image), 갱신 이후 값(After Image) 등이 있다.
데이터베이스 복구 알고리즘
데이터베이스 복구 알고리즘은 동기적/비동기적 갱신에 따라 다음과 같은 방법으로 분류된다.
- NO-UNDO/REDO
- 데이터베이스 버퍼의 내용을 비동기적으로 갱신한 경우의 복구 알고리즘
- NO-UNDO: 트랜잭션 완료 전에는 변경 내용이 데이터베이스에 기록되지 않았으므로 취소할 필요가 없다.
- REDO: 트랜잭션 완료 후 데이터베이스 버퍼에는 기록되어 있고, 저장매체에는 기록되지 않았으므로 트랜잭션 내용을 다시 실행해야 한다.
- UNDO/NO-REDO
- 데이터베이스 버퍼의 내용을 동기적으로 갱신한 경우의 복구 알고리즘
- UNDO: 트랜잭션 완료 전에 시스템이 파손되었다면 변경된 내용을 취소한다.
- NO-REDO: 트랜잭션 완료 전에 데이터베이스 버퍼 내용을 이미 저장 매체에 기록했으므로 트랜잭션 내용을 가시 실행할 필요가 없다.
- UNDO/REDO
- 데이터베이스 버퍼의 내용을 동기/비동기적으로 갱신한 경우의 복구 알고리즘
- 데이터베이스 기록 전에 트랜잭션이 완료될 수 있으므로 완료된 트랜잭션이 데이터베이스에 기록되지 못했다면 다시 실행해야 한다.
- NO-UNDO/NO-REDO
- 데이터베이스 버퍼의 내용을 동기적으로 저장 매체에 기록하지만 데이터베이스와는 다른 영역에 기록한 경우 복구 알고리즘
- NO-UNDO: 변경 내용은 데이터베이스와 다른 영역에 기록되어 있으므로 취소할 필요가 없다.
- NO-REDO: 다른 영역에 이미 기록되어 있으므로 트랜잭션을 다시 실행할 필요가 없다.
백업 종류
백업 종류는 복구 수준에 따라서 운영체제를 이용하는 물리 백업과 DBMS 유틸리티를 이용하는 논리 백업으로 나뉜다.
- 물리 백업: 데이터베이스 파일을 백업하는 방법으로, 백업 속도가 빠르고 작업이 단순하지만 문제 발생 시 원인 파악 및 문제 해결이 어렵다.
- 논리 백업: DB 내의 논리적 객체들을 백업하는 방법으로, 복원 시 데이터 손상을 막고 문제 발생 시 원인 파악 및 해결이 수월하지만 백업/복원 시 시간이 많이 소요된다.

스토리지
스토리지(Storage)의 개요
스토리지는 단일 디스크로 처리할 수 없는 대용량의 데이터를 저장하기 위해 서버와 저장장치를 연결하는 기술이다. 스토리지의 종류에는 DAS, NAS, SAN이 있다.
DAS(Direct Attached Storage)
DAS는 서버와 저장장치를 전용 케이블로 직접 연결하는 방식으로, 일반 가정에서 컴퓨터에 외장하드를 연결하는 것이 여기에 해당한다.
- 서버에서 저장장치를 관리한다.
- 저장장치를 직접 연결하므로 속도가 빠르고 설치 및 운영이 쉽다.
- 초기 구축 비용 및 유지보수 비용이 저렴하다.
- 직접 연결 방식이므로 다른 서버에서 접근할 수 없고 파일을 공유할 수 없다.
- 화장성 및 유연성이 상대적으로 떨어진다.
- 저정 데이터가 적고 공유가 필요 없는 환경에 적합하다.
NAS(Network Attached Storage)
NAS는 서버와 저장장치를 네트워크를 통해 연결하는 방식이다.
- 별도의 파일 관리 기능이 있는 NAS Storage가 내장된 저장장치를 직접 관리한다.
- Ethernet 스위치를 통해 다른 서버에서도 스토리지에 접근할 수 있어 파일 공유가 가능하고, 장소에 구애받지 않고 저장장치에 쉽게 접근할 수 있다.
- DAS에 비해 확장성 및 유연성이 우수하다.
- 접속 증가 시 성능이 저하될 수 있다.
SAN(Storage Area Network)
SAN은 DAS의 빠른 처리와 NAS의 파일 공유 장점을 혼합한 방식으로, 서버와 저장 장치를 연결하는 전용 네트워크를 별도로 구성하는 방식이다.
- 광 채널(FC) 스위치를 이용하여 네트워크를 구성한다.
- 광 채널 스위치는 서버나 저장장치를 광케이블로 연결하므로 처리 속도가 빠르다.
- 저장장치를 공유함으로써 여러 개의 저장장치나 백업 장비를 단일화시킬 수 있다.
- 확장성, 유연성, 가용성이 뛰어나다.
- 높은 트랜잭션 처리에 효과적이나 기존 시스템의 경우 장비의 업그레이드가 필요하고, 초기 설치 시에는 별도의 네트워크를 구축해야 하므로 비용이 많이 든다.
댓글남기기