3장 케라스와 텐서플로 소개
Updated:
텐서플로란?
텐서플로(TensorFlow)는 구글에서 만든 파이썬 기반의 무료 오픈 소스 머신 러닝 플랫폼이다. 넘파이(Numpy)와 매우 비슷하게 텐서플로의 핵심 목적은 엔지니어와 연구자가 수치 텐서에 대한 수학적 표현을 적용할 수 있도록 하는 것이다. 하지만 텐서플로는 다음과 같이 넘파이의 기능을 넘어선다.
- 미분 가능한 어떤 표현식에 대해서도 자동으로 그레디언트를 계산할수 있으므로 머신 러닝에 매우 적합한다.
- CPU 뿐만 아니라 고도로 병렬화된 하드웨어 가속기인 CPU와 TPU에서도 실행할 수 있다.
- 텐서플로에서 정의한 계산은 여러 머신에 쉽게 분산시킬 수 있다.
- 텐서프로 프로그램은 C++, JS 등과 같은 런타임에 맞게 변환할 수 있다. 따라서 텐서프롤 애플리케이션을 실전 환경에 쉽게 배포할 수 있다.
케라스란?
케라스는 텐서플로 위에 구축된 파이썬용 딥러닝 API로 어떤 종류의 딥러닝 모델도 쉽게 만들고 훈련할 수 있는 방법을 제공한다. 텐서플로를 통해 케라스는 다양한 하드웨어(CPU, TPU, CPU) 위에 실행하고 수천 대의 머신 러닝으로 매끄럽게 확장할 수 있다.

케라스는 개발자 경험을 중요하게 생각한다. 일관되고 간단한 워크플로를 제공하며, 일반적인 사용에 필요한 작업의 횟수를 최소화하고, 사용자 에러에 대해 명확하고 실행 가능한피드백을 제공한다. 케라스의 사용자 층이 크고 다양하기 때문에 모델을 구축하고 훈련하는 데 하나의 표준 방식을 따르도록 강요하지 않는다. 사용자 성향에 따라 고수준에서 저수준까지 다양한 워크플로를 사용할 수 있다.
텐서플로 시작하기
신경망 훈련은 다음과 같은 개념을 중심으로 진행된다.
- 모든 현대적인 머신 러닝의 기초 인프라가 되는 저수준 텐서 연산
- 텐서(신경망의 상태를 저장하는 특별한 텐서(변수)도 포함)
- 덧셈, relu, matmul 같은 텐서 연산
- 역전파
- 고수준 딥러닝 개념
- 모델을 구성하는 층
- 학습에 사용하는 피드백 신호를 정의하는 손실 함수
- 학습 진행 방법을 결정하는 옵티마이저
- 정확도처럼 모델의 성능을 평가하는 측정 지표
- 미니 배치를 확률적 경사 하강법을 수행하는 훈련 루프
상수 텐서와 변수
텐서플로에서 어떤 작업을 하려면 텐서가 필요하다. 텐서를 만들려면 초깃값이 필요하다. 예를 들어 모두 1이거나 0인 텐서를 만들거나, 랜덤한 분포에서 뽑은 값으로 텐서를 만들 수 있다.
넘파이 배열과 텐서플로 텐서 사이의 큰 차이점은 텐서플로 텐서에는 값을 할당할 수 없다는 것이다. 즉, 텐서플로 텐서는 상수이다. 예를 들어 넘파이에서 다음과 같이 할 수 있다.
import numpy as np
x = np.ones(shape=(2, 2))
x[0, 0] =0.
텐서플로에서 같은 작업을 하면 “EagerTensor object does not support item assignment”와 같은 에러가 발생한다.
x = tf.ones(shape=(2, 2))
x[0, 0] = 0. # 텐서에는 값을 할당할 수 없기 때문에 에러가 발생
모델을 훈련하려면 모델의 상태, 즉 일련의 텐서를 업데이트해야 한다. 텐서에 값을 할당할 수 없다면, 변수를 이용해 이 작업을 할 수 있다.tf.Variable은 텐서플로에서 수정 가능한 상태를 관리하기 위한 클래스이다.
- 변수를 만들려면 랜덤 텐서와 같이 초깃값을 제공

- 변수의 상태는 aaign 메서드로 수정할 수 있다.

- 변수의 일부 원소에만 적용할 수도 있다.

- 비슷하게 assign_add()와 assign_sub()는 각각 +=, -=과 동일하다.

텐서 연산: 텐서플로에서 수학 계산하기
넘파이와 마찬가지로 텐서플로는 수학 공식을 표현하기 위해 많은 텐서 연산을 제공한다. 다음은 몇 가지 텐서 연산의 예이다.
a = tf.ones((2, 2))
b = tf.square(a) # 제곱 계산
c = tf.sqrt(a) # 제곱근 계산
d = b + c # 두 텐서를 더함
e = tf.matmul(a, b) # 두 텐서의 점곱을 계산
e *= d # 두 텐서를 곱함
중요한 점은 앞의 연산이 모두 바로 실행된다는 것이다. 넘파이처럼 언제든지 현재 결괏값을 출력할 수 있다. 이를 즉시 실행(eager execution) 모드라고 부른다.
GradientTape API 다시 살펴보기
텐서플로가 넘파이와 비슷해 보이지만, 넘파이가 할 수 없는 것이 있다. 텐서플로는 미분 가능한 표현이라면 어떤 입력에 대해서도 그레디언트를 계산할 수 있고, GradientTape 블록을 시작하고 하나 또는 여러 입력 텐서에 대해 계산을 수행한 후 입력에 대해 결과의 그레디언트를 계산한다.
input_var = tf.Variable(initial_value=3.)
with tf.GradientTape() as tape:
result = tf.square(input_var)
gradient = tape.gradient(result, input_var)
gradient = tape.gradient(loss, weights)와 같이 가중치에 대한 모델 손실의 그레디언트를 계산하는 데 가장 널리 사용되는 방법이다. tape.gradient()의 입력 텐서가 텐서플로 변수말고도 어떤 텐서라도 가능하다. 텐서플로는 기본적인 훈련 가능한 변수만 추적한다. 상수 텐서의 경우 tape.watch()를 호출하여 추적한다는 것을 수동으로 알려 주어야 한다.
input_const = tf.constant(3.)
with tf.GradientTape() as tape:
tape.watch(input_const)
result = tf.square(input_const)
gradient = tape.gradient(result, input_const)
이것이 필요한 이유는 모든 텐서에 대한 모든 그레디언트를 계산하기 위해 필요한 정보를 미리 앞서서 저장하는 것은 비용이 많이 들기 때문이다. 자원 낭비를 막기 위해 테이프는 감시할 대상을 알아야 한다. 훈련 가능한 변수는 기본적으로 감시 대상이다. 훈련 가능한 변수에 대한 손실의 그레디언트를 계산하는 것이 그레디언트 테이브의 주 사용 용도이기 때문이다. 그레디언트 테이프는 강력한 유틸리티이고 이계도(second-order) 그레디언트, 즉 그레디언트의 그레디언트도 계산할 수 있다.
예를 들어 시간에 대한 물체 위치의 그레디언트는 물체의 속도고, 이계도 그레디언트는 가속도로, 수직 방향으로 낙하하는 사과의 위치를 시간에 따라 측정하고 position(time) = 4.9 * time ** 2임을 알았다면 가속도를 구해본다.
time = tf.Variable(0.)
with tf.GradientTape() as outer_tape:
with tf.GradientTape() as inner_tape:
position = 4.9 * time ** 2
speed = inner_tape.gradient(position, time)
acceleration = outer_tape.gradient(speed, time)
바깥 테이프가 안쪽 테이프의 그레디언트를 계산하면, 계산된 가속도는 4.9 * 2 = 9.8이다.
엔드-투-엔트 예제: 텐서플로 선형 분류기
선형 분류기를 구현하기 전에 먼저 선형적으로 잘 구분되는 합성 데이터를 만들어본다. 이는 2D 평면의 포인트로 2개의 클래스를 가진다. 특정한 평균과 공분산 행렬(convariance matrix)을 가진 랜덤한 분포에서 좌표 값을 뽑아 각 클래스의 포인트를 생성한다. 직관적으로 생각하면 공분산 행렬은 포인트 클라우드(cloud)의 형태를 결정하고, 평균은 평면에서의 위치를 나타낸다고 볼 수 있다.
공분산 과 공분산 행렬
- 공분산: 2개 변수가 함께 변하는 정도를 측정하는 척도이다.
- 두 변수가 있을 때, 한 변수값이 커지면서 다른 변수도 값이 증가하는 등 두 변수의 변화 경향성 유사하다면 공분산은 양수(positive)이다.
- 반대로 한 변수값이 커질 때 다른 변수값이 작아지는 반대 경향성을 보인다면 공분산은 음수(negative)이다.
- 공분산 행렬: 변수들 사이의 공분산을 행렬 형태로 나태난 것이다.
- 공분산 행렬은 정방행렬(square matrix)이자 전치(transpose)를 시켰을 때 동일한 행렬이 나타나는 대칭행렬(symmetric matrix)인 특징이 있다.
- 행렬의 대각 항들은 단일 변수의 분산을 의미한다.
두 포인트 클라우드에 동일한 공분산 행렬을 사용하지만 평균은 다른 값을 사용한다. 즉, 두 포인트 클라우드는 같은 모양을 띠지만 다른 위치에 있을 것이다.
import numpy as np
num_samples_per_class = 1000
# 첫 번째 클래스의 포인트를 생성한다.
negative_samples = np.random.multivariate_normal(
mean=[0, 3],
cov=[[1, 0.5],[0.5, 1]], # 왼쪽 아래에서 오른쪽 위로 향하는 타원형의 포인트 클라우드
size=num_samples_per_class # 100개의 랜덤한 2D 포인트
)
# 동일한 공분산 행렬과 다른 평균을 사용하여 다른 클래스의 포인트를 생성
positive_samples = np.random.multivariate_normal(
mean=[3, 0],
cov=[[1, 0.5], [0.5, 1]],
size=num_samples_per_class
)
위 코드에서 negative_samples와 positive_samples는 모두 (1000, 2) 크기의 배열이다. 이를 수직으로 연결하여 (2000, 2) 크기의 배열을 만들어 본다.
inputs = np.vstack((negative_samples, positive_samples)).astype(np.float32)
(2000, 1) 크기의 0배열과 1배열을 합쳐 타깃 레이블을 생성해 본다. Inputs[i]가 클래스 0에 속하면 targets[i, 0]는 0이다.
targets = np.vstack((np.zeros((num_samples_per_class, 1), dtype="float32"),
np.ones((num_samples_per_class, 1), dtype="float32")))
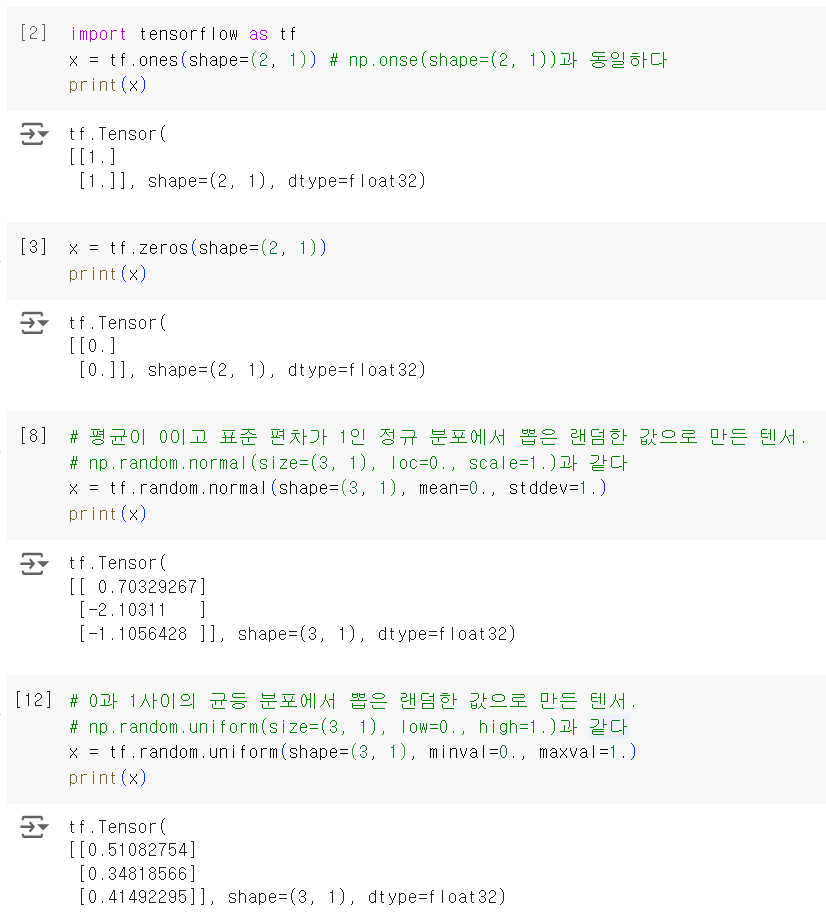
Matplotlib를 이용해서 이 데이터를 그래프로 나타내 본다.
import matplotlib.pyplot as plt
plt.scatter(inputs[:, 0], inputs[:, 1], c=targets[:, 0])
plt.show()
이제 두 포인트 클라우드를 구분할 수 있는 선형 분류기를 만들어 본다. 이 선형 분류기는 하나의 아핀 변환(prediction = W • input + b)이며, 예측과 타깃 사이의 차이를 제곱한 값을 최소화하도록 훈련한다. 각각 랜덤한 값과 0으로 초기화한 변수 W와 b를 만들어 본다.
input_dim = 2 # 입력은 2D 포인트
output_dim = 1 # 출력은 예측 샘플당 하나의 점수
# 0에 가까우면 샘플을 클래스 0으로 예측, 1에 가까우면 1로 예측
W = tf.Variable(initial_value=tf.random.uniform(shape=(input_dim, output_dim)))
b = tf.Variable(initial_value=tf.zeros(shape=(output_dim,)))
다음은 정방향 패스를 위한 함수이다.
def model(inputs):
return tf.matmul(inputs, W) + b
- 이 선형 분류기는 2D 입력을 다루기 때문에 W는 2개의 스칼라 가중치 w1과 w2로 이루어진다. 반면 b는 하나의 스칼라 값이다.
- 어떤 입력 포인트 [x, y]가 주어지면 예측 값은 prediction = [[w1], [w2]] • [x, y] + b = w1 * x + w2 * y + b가 된다.
다음은 손실 함수를 보여준다.
def square_loss(targets, predictions):
per_sample_losses = tf.square(targets - predictions)
# per_sample_losses는 targets나 predictions와 크기가 같은 텐서이며 각 샘플의 손실 값을 담고 있다.
return tf.reduce_mean(per_sample_losses)
# 샘플당 손실 값을 하나의 스칼라 손실 값을 평균한다. reduce_mead 함수가 이런 작업을 수행한다.
다음은 훈련 스텝으로 훈련 데이터를 받아 이 데이터에 대한 손실을 최소화하도록 가중치 W와 b를 업데이트한다.
learning_rate = 0.1
def train_step(inputs, targets):
with tf.GradientTape() as tape: # 그레디언트 테이프 블록 안의 정방향 패스
predictions = model(inputs)
loss = square_loss(predictions, targets)
grad_loss_wrt_W, grad_loss_wrt_b = tape.gradient(loss, [W, b]) # 가중치에 대한 손실의 그레디언트를 구함
# 가중치 업데이트
W.assign_sub(grad_loss_wrt_W * learning_rate)
b.assign_sub(grad_loss_wrt_b * learning_rate)
return loss
구현을 간단하게 하기 위해 미니 배치 훈련 대신 배치 훈련을 사용한다. 즉, 데이터를 작은 배치로 나누어 반복하지 않고 전체 데이터를 사용하여 훈련 스텝(그레디언트 계산과 가중치 업데이트)을 실행한다. 이렇게 하면 한 번에 2,000개의 샘플에 대해 정방향 패스와 그레디언트를 계산해야 하므로 각 훈련 스텝의 실행 시간이 오래 걸린다. 하지만 전체 훈련 샘플로부터 정보를 취합하므로 각각의 그레디언트 업데이트는 훈련 데이터의 손실을 감소하는 데 훨씬 더 효과적이다. 결과적으로 훈련 스텝의 횟수가 많이 필요하지 않고 미니 배치 훈련 때보다 일반적으로 큰 학습률을 사용할 수 있다. 위에서 정의한 learning_rate = 0.1을 사용해본다.
for step in range(40):
loss = train_step(inputs, targets)
print(f"{step}번째 스텝의 손실: {loss:.4f}")
이를 실행하면 40번 에포크 후 훈련 손실이 0.025에서 안정화되는 것 같다. 이 선형 모델이 훈련 데이터 포인트를 어떻게 분류하는지 그려 본다. 타깃이 0 또는 1이기 때문에 입력 포인트의 예측 값이 0.5보다 작으면 ‘0’으로 분류되고 0.5보다 크면 ‘1’로 분류된다.
predictions = model(inputs)
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5)
plt.show()
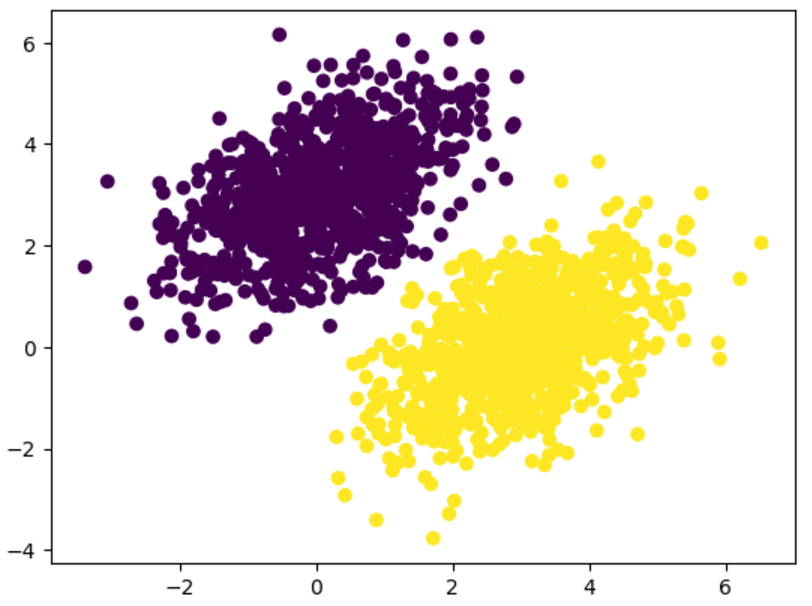
위 그림을 보면 훈련 타깃과 매우 비슷한 것을 확인할 수 있다. 포인트[x, y]에 대한 예측 값은 $\mathtm{prediction} == [[w1], [w2]] \cdot [x, y] + b == w1 * x + w2 * y + b$이다. 따라서 클래스 0은 $w1 * x + w2 * y + b < 0.5$이고 클래스 1은 $w1 * x + w2 * y + b > 0.5$로 정의할 수 있다. 실제로 여기서 찾고자 하는 것은 2D 평면 위의 직선의 방정식 $w1 * x + w2 * y + b = 0.5$가 된다. 이 직선보다 위에 있으면 클래스 1이고 이 직선 아래에 있으면 클래스 0이다. 이 직선을 그려 본다.
x = np.linspace(-1, 4, 100) # 직선을 그리기 위해 -1 ~ 4 사이에 일정한 간격을 가진 100개의 숫자를 생성
y = -W[0] / W[1] * x + (0.5 - b) / W[1] # 사용할 직선의 방정식
plt.plot(x, y, "-r") # 직선을 -r, 빨간색으로 그린다.
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5) # 동일한 그래프에 모델의 예측을 나타낸다.
plt.show()
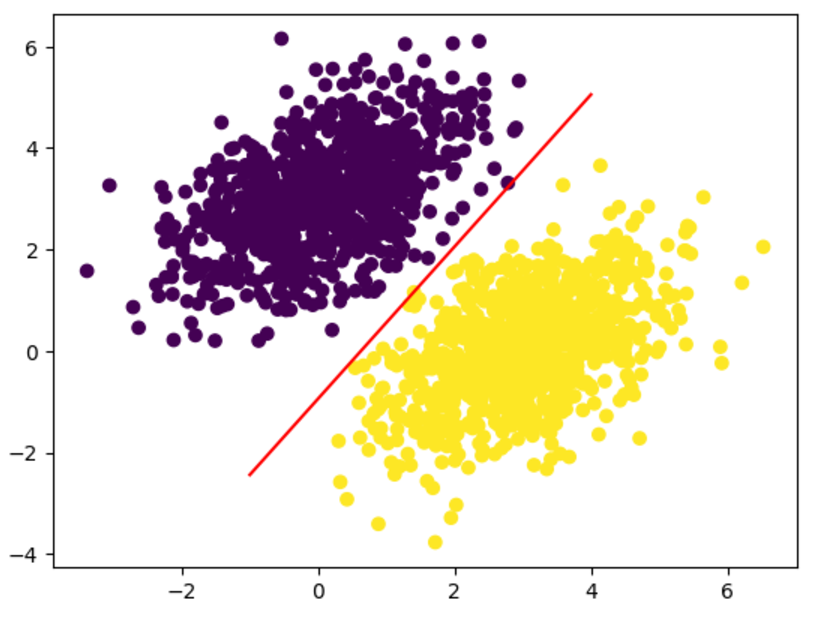
이것이 선형 분류기에 대한 전부이다. 데이터에 있는 두 클래스를 잘 구분하는 직선의 파라미터를 찾는 것이다.
신경망의 구조: 핵심 Keras API 이해하기
층: 딥러닝의 구성 요소
신경망의 기본 데이터 구조는 층(layer)이다. 층은 하나 이상의 텐서를 입력으로 받고 하나 이상의 텐서를 출력하는 데이터 처리 모듈이다. 어떤 종류의 층은 상태가 없지만 대부분의 경우 가중치(weight)라는 층의 상태를 가진다. 가중치는 확률적 경사 하강법으로 학습되는 하나 이상의 텐서이며 여기에 신경망이 학습한 지식이 담겨 있다.
층마다 적절한 텐서 포맷과 데이터 처리 방식이 다르다.
- (sample, feature) 크기의 랭크-2 텐서에 저장된 간단한 벡터
- 밀집 연결 층(densely connected layer)(완전 연결 층(fully connected layer), 밀집 층(dense layer)) 으로 처리
- (sample, timesteps, features) 크기의 랭크-3 텐서에 저장된 간단한 시퀀스 데이터
- LSTM 같은 순환 층(recurrent layer)이나 1D 합성곱 층(convolution layer, Conv1D)으로 처리한다.
- 랭크-4 텐서에 저장된 이미지 데이터
- 2D 합성곱 층(Conv2D)으로 처리한다.
케라스에서 딥러닝 모델을 만드는 것은 호환되는 층을 서로 연결하여 유용한 데이터 변환 파이프라인을 구성하는 것이다. 이 때문에 층을 딥러닝의 레고 블록처럼 생각할 수 있다.
케라스의 Layer 클래스
간단한 API는 모든 것이 중심에 모인 하나의 추상화를 가져야 한다. 케라스에서는 Layer 클래스가 그렇다. 케라스에서는 Layer 또는 Layer와 밀접하게 상호 작용하는 것이 전부다.
Layer는 상태(가중치)와 연산(정방향 패스)을 캡슐화한 객체이다. 가중치는 생성자인 __init__() 메서드에서 만들 수도 있지만 일반적으로 build() 메서드에서 정의하고 연산은 call() 메서드에서 정의한다.
from tensorflow import keras
class SimpleDense(keras.layers.Layer): # 모든 케라스 층은 Layer 클래스를 상속
def __init__(self, units, activation=None):
super().__init__()
self.units = units
self.activation = activation
def build(self, input_shape): # build() 메서드에 가중치를 생성
input_dim = input_shape[-1]
# add_weight()는 가중치를 간편하게 만들 수 있는 메서드
# self.W = tf.Variable(tf.random.uniform(w_shape))와 같이
# 독립적으로 변수를 생성하고 층의 속성으로 할당할 수도 있다.
self.W = self.add_weight(shape=(input_dim, self.units),
initializer="random_normal")
self.b = self.add_weight(shape=(self.units,),
initializer="zeros")
def call(self, inputs): # call() 메서드에서 정방향 패스 계산을 정의
y = tf.matmul(inputs, self.W) + self.b
if self.activation is not None:
y = self.activation(y)
return y
이 클래스의 인스턴스를 성성하면 텐서플로 텐서를 입력으로 받는 함수처럼 사용할 수 있다.
my_dense = SimpleDense(units=32, activation=tf.nn.relu) # 앞서 정의한 층의 인스턴스 생성
input_tensor = tf.ones(shape=(2, 784)) # 테스트 입력 생성
output_tensor = my_dense(input_tensor) # 이 입력으로 층을 함수처럼 호출
print(output_tensor.shape)
# >> (2, 32)
위는 my_dense(input_tensor)처럼 객체를 함수처럼 생성했을 때 keras.layers.Layer를 상속받는 클래스 SimpleDense에서 keras.layers.Layer의 __call__() 메서드를 사용했다. call()과 build() 메서드는 때에 맞추어 가중치를 생성해야 하기 때문에 구현했다.
자동 크기 추론: 동적으로 층 만들기
레고 블록처럼 호환되는 층만 서로 연결할 수 있다. 층 호환(layer compatibility)은 모든 층이 특정 크기의 입력 텐서만 받고, 특정 크기의 출력만 반환한다는 사실을 의미한다.
from tensorflow.keras import layers
layer = layers.Dense(32, activation="relu")
이 층은 첫 번째 차원이 32인 텐서를 반환한다. 입력으로 32차원의 벡터를 기대하는 후속 층만 연결할 수 있다.
케라스를 사용할 때 대부분의 경우 크기 호환성에 대해 걱정할 필요가 없다. 모델에 추가하는 층은 앞선 층의 크기에 맞도록 동적으로 만들어지기 때문이다. 다음 예를 보자.
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential([
layers.Dense(32, activation="relu"),
layers.Dense(32)
])
이 층들은 입력 크기에 대한 어떤 정보도 받지 않는다. 그 대신 입력 크기를 처음 본 입력의 크기로 추론한다.
2장에서 만들었던 간단한 Dense 층인 NaiveDense 클래스의 경우 가중치를 만들기 위해 각 층의 입력 크기를 생성자에게 명시적으로 전달했지만, 이는 이상적이지 않다. 예를 들어 층이 이전 층의 크기를 알도록 하기 위해 다음과 같은 모델이 만들어지기 때문이다.
model = NaiveSequential([
NaiveDense(input_size = 784, output_size = 32, activation="relu"),
NaiveDense(input_size = 32, output_size = 64, activation="relu"),
NaiveDense(input_size = 64, output_size = 32, activation="relu"),
NaiveDense(input_size = 32, output_size = 10, activation="softmax"),
])
츨력을 만드는 층의 규칙이 복잡하면 문제는 더 심각해진다. 크기를 자동으로 추론할 수 있는 케라스 층으로 NaiveDense 클래스를 다시 구현한다면 이전에 보았던 build()와 call() 메서드가 있는 SimpleDense 층과 같을 것이다.
SimpleDense 클래스에서는 NaiveDense처럼 생성자에서 가중치를 만들지 않는다. 그 대신 상태 생성을 위한 전용 메서드인 build()에서 만든다. 이 메서드는 층이 처음 본 입력 크기를 매개변수로 받는다. build() 메서드는 층이 처음 호출될 때 자동으로 호출된다. 이것이 __call__() 메서드가 아니라 별도의 call() 메서드에서 계산을 정의한 이유다. 기본 Layer 클래스의 __call__() 메서드는 다음과 같다.
def __call__(self, inputs):
if not self.built:
self.build(inputs.shape)
self.built = True
return self.call(inputs)
자동으로 크기를 추론하면 이전 예시는 다음과 같이 간단하고 깔끔하게 표현할 수 있다.
model = keras.Sequential([
SimpleDense(32, activation="relu"),
SimpleDense(64, activation="relu"),
SimpleDense(32, activation="relu"),
SimpleDense(10, activation="softmax"),
])
Layer 클래스의 __call__() 메서드가 자동 크기 추론만 처리하는 것은 아니다. 즉시 실행과 그래프 실행(graph execution) 사이를 전환하고 입력 마스킹(masking)을 처리하는 등 더 많은 작업을 관리한다. 지금은 사용자 정의 층을 구현할 때 call() 메서드에 정방향 패스 계산을 넣는것만 기억한다.
층에서 모델로
딥러닝 모델은 층으로 구성된 그래프이다. 케라스에서는 Model 클래스에 해당한다. 지금까지 본 단순히 층을 쌓은 Model의 서브 클래스인 Sequential 모델은 하나의 입력을 하나의 출력에 매핑한다. 하지만 다양한 종류의 네트워크가 있다. 다음은 그중 자주 등장하는 구조이다.
- 2개의 가지(two-branch)를 가진 네트워크
- 멀티헤드(multihead) 네트워크
- 잔차 연결(residual connection)
네트워크 구조(topology)는 꽤 복잡할 수 있다. 예를 들어 다음은 텍스트 데이터를 처리하기 위해 설계되어 널리 사용되는 트랜스포머(Transformer) 층의 구조이다.
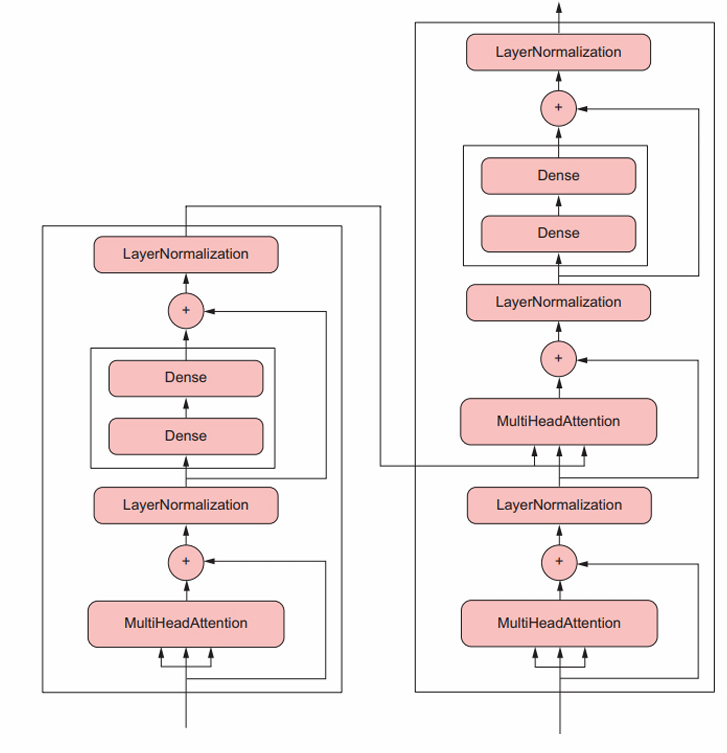
케라스에서 이런 모델을 만드는 방법은 일반적으로 두 가지이다. 직접 Model 클래스의 서브클래스를 만들거나, 더 작은 코드로 많은 일을 수행할 수 있는 함수형 API(functional API)를 사용할 수 있다.
모델의 구조는 가설 공간(hypothesis space)을 정의한다. 머신 러닝은 ‘사전에 정의된 가능성 있는 공간(space of possibility) 안에서 피드백 신호의 도움을 받아 입력 데이터의 유용한 표현을 찾는 것’이다. 네트워크 구조를 선택하면 가능성 있는 공간(가설 공간)이 입력 데이터를 출력 데이터로 매핑하는 일련의 특정한 텐서 연산으로 제한된다. 그다음 찾을 것은 이런 텐서 연산에 관련된 가중치 텐서의 좋은 값이다.
데이터에서 학습하려면 데이터에 대한 가정을 해야하고 이런 가정이 학습할 수 있는 것을 정의한다. 즉, 모델의 구조는 매우 중요하다. 문제에 대한 가정, 즉 시작할 때 모델이 가지게 될 사전 지식을 인코딩한다. 예를 들어 활성화 함수 없이 하나의 Dense 층을 가진 모델로 2개의 클래스를 분류하는 문제를 다룬다면, 두 클래스가 선형적으로 구분될 수 있다고 가정하는 것이다.
‘컴파일’ 단계: 학습 과정 설명
모델 구조를 정의하고 난 후 다음 세 가지를 더 선택해야 한다.
- 손실 함수(loss function)(목적 함수(objective function)): 훈련 과정에서 최소화할 값, 현재 작업에 대한 성공의 척도이다.
- 옵티마이저(optimizer): 손실 함수를 기반으로 네트워크가 어떻게 업데이트될지 결정한다. 특정 종류의 학률적 경사 하강법(SGD)으로 구현된다.
- 측정 지표(metric): 훈련과 검증 과정에서 모니터링할 성공의 척도이다.
- 손실과 달리 훈련은 측정 지표에 직접 최적화되지 않는다.
- 따라서 측정 지표는 미분 가능하지 않아도 된다.
손실, 옵티마이저, 측정 지표를 선택했다면 모델에 내장된 compile()과 fit() 메서드를 사용하여 모델 훈련을 시작할 수 있다. 또는 사용자 정의 루프를 만들 수도 있다.
compile() 메서드는 훈련 과정을 설정한다. 이 메서드의 매개변수는 optimizer, loss, metrics(리스트)이다.
model = keras.Sequential([keras.layers.Dense(1)]) # 선형 분류기를 정의
model.compile(optimizer="rmsprop", # 옵티마이저 이름을 지정
loss="mean_squared_error", # 손실 이름을 평균 제곱 오차로 지정
metrics=["accuracy"]) # 측정 자료를 리스트로 지정, 여기에서는 정확도만 사용
앞의 compile() 메서드에서 옵티마이저, 손실, 측정 지표를 매개변수 값을 문자열로 지정한다. 이런 문자열은 실제로는 편의를 위한 단축어이며 해당 파이썬 객체로 변환된다. 예를 들어 “rmsprop”은 keras.optimizers.RMSprop()이 된다. 중요한 것은 다음과 같이 매개변수를 인스턴스 객체로 지정할 수도 있다.
model.compile(optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.BinaryAccuracy()])
이는 사용자 정의 손실이나 측정 지표를 전달하고 싶을 때 유용하다. 또는 사용할 객체를 상세히 설정하고 싶을 때이다. 예를 들어 다음과 같이 옵티마이저의 learning_rate 매개변수를 바꿀 수 있다.
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate = 1e-4),
loss=my_custom_loss,
metrics=[my_custom_metric_1, my_custom_metric_2])
손실 함수 선택하기
네트워크가 손실을 최소화하기 위해 편법을 사용할 수 있기 때문에 문제에 맞는 올바른 손실 함수를 선택하는 것은 아주 중요하다. 목적 함수가 현재 문제의 성공과 전혀 관련이 없다면 원하지 않는 일을 수행하는 모델이 만들어 질 것이다.
분류, 회귀, 시퀀스 예측가 같은 일반적인 문제의 경우 올바른 손실 함수를 선택하는 간단한 가이드라인이 있다. 완전히 새로운 연구를 할 때만 자신만의 손실 함수를 만들게 될 것이다.
fit() 메서드 이해하기
compile() 다음에는 fit() 메서드를 호출한다. fit() 메서드는 훈련 루프를 구현한다. 다음은 fit() 메서드의 주요 매개변수이다.
- 훈련할 데이터(입력과 타깃): 일반적으로 넘파이 배열이나 텐서플로 Dataset 객체로 전달한다.
- 훈련할 에포크(epoch) 횟수: 전달한 데이터에서 훈련 루프를 몇 번이나 반복할지 알려준다.
- 미니 배치 경사 하강법의 각 에포크에서 사용할 배치 크기: 가중치 업데이트 단계에서 그레디언트를 계산하는 데 사용될 훈련 샘플 개수를 말한다.
history = model.fit(
inputs,
targets,
epochs=5,
batch_size=12
)
fit()을 호출하면 History 객체가 반환된다. 이 객체는 딕셔너리인 history 속성을 가지고 있다. 이 딕셔너리는 “loss” 또는 특정 지표 이름의 키와 각 에포크 값의 리스트를 매핑한다.
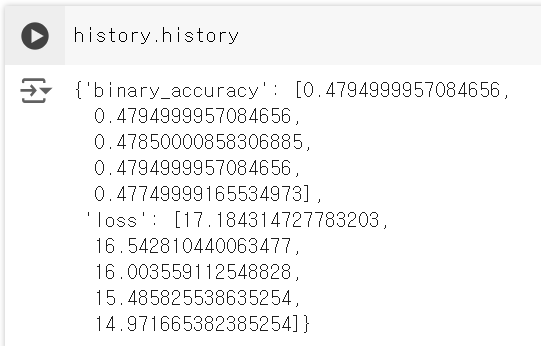
검증 데이터에서 손실과 측정 지표 모니터링하기
머신 러닝의 목표는 훈련 데이터에서 잘 동작하는 모델을 얻는 것이 아니다. 머신 러닝의 목표는 범용적으로 잘 동작하는 모델을 얻는 것이다. 특히 이전에 만난 적 없는 데이터에서 잘 동작하는 모델이다.
새로운 데이터에 모델이 어떻게 동작하는지 예상하기 위해 훈련 데이터의 일부를 검증 데이터(validation date)로 떼어 놓는 것이 표준적인 방법이다. 검증 데이터에서 모델을 훈련하지 않지만 이 데이터를 사용하여 손실과 측정 지표를 계산한다. 이렇게 하려면 fit() 메서드의 validation_data 매개변수를 사용한다. 훈련 데이터처럼 검증 데이터는 넘파이 배열이나 텐서플로 Dataset 객체로 전달할 수 있다.
model = keras.Sequential([keras.layers.Dense(1)])
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=0.1),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.BinaryAccuracy()])
# 검증 데이터에 한 클래스의 샘플만 포함되는 것을 막기 위해
# 랜덤하게 생성한 인덱스를 사용해서 입력과 타깃을 섞는다.
indices_permutation = np.random.permutation(len(inputs))
shuffled_inputs = inputs[indices_permutation]
shuffled_targets = targets[indices_permutation]
# 훈련 입력과 타깃의 30%를 검증용으로 떼어 놓는다.
num_validation_samples = int(0.3 * len(inputs))
val_inputs = shuffled_inputs[:num_validation_samples]
val_targets = shuffled_targets[:num_validation_samples]
training_inputs = shuffled_inputs[num_validation_samples:]
training_targets = shuffled_targets[num_validation_samples:]
model.fit(
# 훈련 데이터는 모델의 가중치를 업데이터하는 데 사용한다.
training_inputs,
training_targets,
epochs=5,
batch_size=16,
# 검증 데이터는 검증 손실과 측정 지표를 모니터링하는 데만 사용한다.
validation_data=(val_inputs, val_targets)
)
검증 데이터의 손실 값을 ‘훈련 손실(training loss)’과 구분하기 위해 ‘검증 손실(validation loss)’이라고 부른다. 훈련 데이터와 검증 데이터를 엄격하게 분리하는 것이 필수이다. 검증 목적은 모델이 학습한 것이 새로운 데이터에 실제로 유용한지 모니터링하는 것이기 때문이다. 검증 데이터의 일부가 훈련 도중 모델에 노출되면 검증 손실과 측정 지표가 오염될 것이다.
훈련이 끝난 후 검증 손실과 측정 지표를 계산하고 싶다면 evaluate() 메서드를 사용할 수 있다.
loss_and_metrics = model.evaluate(val_inputs, val_targets, batch_size=128)
evaluate() 메서드는 전달된 데이터를 batch_size 크기의 배치로 순회하고 스칼라 값의 리스트를 반환한다. 반환된 리스트의 첫 번째 항복은 검증 손실이고 이어지는 항목이 검증 데이터에 대한 측정 지표 값들이다. 모델에 측정 지표를 지정하지 않았다면 검증 손실만 반환된다.
추론: 훈련한 모델 사용하기
모델을 훈련하고 나면 이 모델을 사용하여 새로운 데이터에서 예측을 만들게 된다. 이를 추론(inference)이라고 부른다. 간단한 방법은 모델의 __call__() 메서드를 호출하는 것이다.
# 넘파이 배열이나 텐서플로 텐서를 받고 텐서플로 텐서를 반환
predictions = model(new_inputs)
하지만 이 방법은 new_inputs에 있는 모든 입력을 한 번에 처리한다. 데이터가 많다면 가능하지 않을 수 있다.
추론을 하는 더 나은 방법은 predicti() 메서드를 사용하는 것이다. 이 메서드는 데이터를 작은 배치로 순회하여 넘파이 배열로 예측을 반환한다. __call__() 메서드와 달리 텐서플로 Dataset 객체도 처리할 수 있다.
# 넘파이 배열이나 Dataset 객체를 받고 넘파이 배열을 반환
predictions = model.predic(new_inputs, batch_size=128)
예를 들어 앞서 훈련한 선형 모델의 predict() 메서드의 검증 데이터로 호출하면 각 입력 샘플에 대한 모델의 예측을 나타내는 스칼라 점수를 얻게 된다.
predictions = model.predict(val_inputs, batch_size=128)
print(predictions[:10])
댓글남기기