4장 신경망 시작하기: 분류와 회귀
Updated:
분류와 회귀에는 전문적인 용어가 많다.
- 샘플 또는 입력: 모델에 주입될 하나의 데이터 포인트(data point)
- 예측 또는 출력: 모델로부터 나오는 값
- 타깃: 정답. 외부 데이터 소스에 근거하여 모델이 완벽하게 예측해야 하는 값
- 예측 오차 또는 손실 값: 모델의 예측과 타깃 사이의 거리를 측정한 값
- 클래스: 분류 문제에서 선택할 수 있는 가능한 레이블의 집합
- 고양이와 강아지 사진을 분류할 때 클래스는 ‘고양이’와 ‘강아지’ 2개이다.
- 레이블: 분류 문제에서 클래스 할당의 구체적인 사례
- 사진 #1234에 ‘강아지’ 클래스가 들어 있다고 표시한다면 ‘강아지’는 사진 #1234의 레이블이 된다.
- 참 값(ground-truth) 또는 애터네이션(annotation): 데이터셋에 대한 모든 타깃
- 이진 분류: 각 입력 샘플이 2개의 배타적인 범주로 구분되는 분류 작업
- 다중 분류: 각 입력 샘플이 2개 이상의 범주로 구분되는 분류 작업
- 다중 레이블 분류: 각 입력 샘플이 여러 개의 레이블에 할당될 수 있는 분류 작업
- 하나의 이미지에 고양이와 강아지가 모두 들어 있을 때는 ‘고양이’ 레이블과 ‘강아지’ 레이블을 모두 할당해랴 한다.
- 스칼라 회귀: 타깃이 연속적인 스칼라 값인 작업
- 벡터 회귀: 타깃이 연속적인 값의 집합인 작업
- 미니 배치 또는 배치: 모델에 의해 동시에 처리되는 소량의 샘플 묶음
영화 리뷰 분류: 이진 분류 문제
2종 분류(two-class classification) 또는 이진 분류(binary classification)는 가장 널리 적용된 머신 러닝 문제일 것이다. 이 예제에서 리뷰 텍스트를 기반으로 영화 리뷰를 긍정(positice)과 부정(negative)으로 분류하는 방법을 알아본다.
IMDB 데이터셋
인터넷 영화 데이터베이스(Internet Movie Database)로부터 가져온 양극단의 리뷰 5만 개로 이루어진 IMDB 데이터셋을 사용한다. 이 데이터셋은 훈련 데이터 25,000개와 텍스트 데이터 25,000갸로 나뉘어 있고 각각 50%는 부정, 50%는 긍정 리뷰로 구성되어 있다.
IMDB 데이터셋도 케라스에 포함되어 있고, 이 데이터는 전처리되어 있어 각 리뷰(단어 시퀀스)가 숫자 시퀀스로 변환되어 있다. 여기에서 각 숫자는 사전에 있는 고유한 단어를 나타낸다. 이렇게 전처리된 데이터를 사용하면 모델 구축, 훈련, 평가에 초점을 맞출 수 있다.
다음은 데이터셋을 로드하는 코드이다.
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words = 10000)
- train_data, test_data: 리뷰를 담은 배열, 각 리뷰는 단어 인덱스의 리스트(단어 시퀀스가 인코딩된 것).
- train_labels, test_labels: 부정을 나타내는 0과 긍정을 나타내는 1의 리스트
- num_words = 10000 : 훈련 데이터에서 가장 자주 나타나는 단어 1만 개만 사용하겠다는 의미, 이렇게하면 불필요한 단어를 제외하여 적절한 크기의 벡터 데이터를 얻을 수 있다.

가장 자주 등장하는 단어 1만 개로 제한했기 때문에 단어 인덱스는 9,999를 넘지 않는다. 다음은 리뷰 데이터 하나를 원래 영어 단어로 바꾸는 코드이다.
# word_index는 단어와 정수 인덱스를 매핑한 딕셔너리
word_index = imdb.get_word_index()
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()]) # 정수 인덱스와 단어를 매핑하도록 뒤집는다.
decoded_review = " ".join(
[reverse_word_index.get(i - 3, "?") for i in train_data[0]]) # 리뷰를 디코딩.
# 0, 1, 2는 '패딩', '문서 시작', '사전에 없음'을 위해 예약되어 있으므로 인덱스에서 3을 뺀다.
데이터 준비
신경망에 숫자 리스트를 바로 주입할 수는 없다. 이 숫자 리스트는 모두 길이가 다르지만 신경망은 동일한 크기의 배치를 기대하기 때문이다. 리스트를 텐서로 바꾸는 두 가지 방법이 있다.
- 같은 길이가 되도록 리스트에 패딩(padding)을 추가하고 (samples, max_length) 크기의 정수 텐서로 변환후 정수 텐서를 다룰 수 있는 층(Embedding 층)으로 신경망을 시작.
- 가장 긴 리뷰는 2,494개의 단어로 이루어져 있으므로 훈련 데이터를 변환한 텐서의 크기는 (25000, 2494)가 된다.
- 리스트를 멀티-핫 인코딩(multi-hot encoding)하여 0과 1의 벡터로 변환후 부동 소수점 벡터 데이터를 다룰 수 있는 Dense 층을 신경망의 첫 번째 층으로 사용.
- 시퀀스 [8, 5]를 인덱스 8과 5의 위치는 1이고 그 외는 모두 0과 10,000차원의 벡터로 각각 변환한다.
다음은 정수 시퀀스를 멀티-핫 인코딩으로 인코딩하는 코드이다.
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension)) # 크기가 (len(sequences), dimension)이고 모든 원소가 0인 행렬을 만든다.
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1. # results[i]에서 특정 인덱스의 위치를 1로 만든다.
return results
x_train = vectorize_sequences(train_data) # 훈련 데이터를 벡터로 변환
x_test = vectorize_sequences(test_data) # 테스트 데이터를 벡터로 변환
이제 샘플은 다음과 같이 나타난다.

레이블은 쉽게 벡터로 바꿀 수 있다.
x_train = np.asarray(train_labels).astype(np.float32)
y_test = np.asarray(test_labels).astype(np.float32)
신경망 모델 만들기
입력 데이터가 벡터고 레이블은 스칼라(1또는 0)이다. 이런 문제에 잘 작동하는 모델은 relu 활성화 함수를 사용한 밀집 연결 층을 그냥 쌓은 것이다.
Dense 층을 쌓을 때 ‘얼마나 많은 층을 사용할지’, ‘각 층에 얼마나 많은 유닛을 둘 것인지’ 두 가지 중요한 구조상의 결정이 필요하다. 이번에는 ‘16개의 유닛을 가진 2개의 중간층’, ‘현재 리뷰의 감정을 스칼라 값의 예측으로 출력하는 세 번째 층’ 으로 Dense 층을 쌓는다. 다음은 이 신경망을 보여준다.
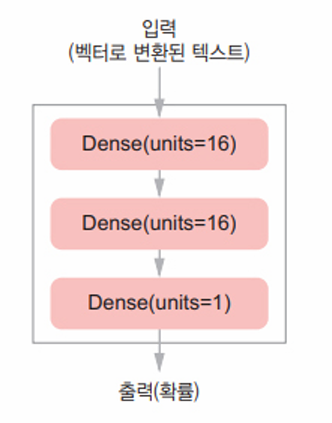
다음 코드는 위 신경망의 케라스 구현이다.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
- Dense 층에 전달한 첫 번째 매개변수는 층의 유닛(unit) 개수이며, 층이 가진 표현 공간(representation space)의 차원이다.
2장과 3장에서 relu 활성화 함수를 사용한 Dense 층은 output = relu(dot(W, input) + b)와 같은 텐서 연산을 연결하여 구현한다. 16개의 유닛이 있다는 것은 가중치 행렬 W의 크기가 (input_dimension, 16)이라는 뜻이다. 입력 데이터와 W를 점곱하면 입력 데이터가 16차원으로 표현된 공간으로 투영된다. 그리고 편향 벡터 b를 더하고 relu 연산을 적용한다. 표현 공간의 차원을 ‘모델이 내재된 표현을 학습할 때 가질 수 있는 자요도’로 이해할 수 있다. 유닛을 늘리면(표현 공간을 더 고차원으로 만들면) 모델이 더욱 복잡한 표현을 학습할 수 있지만 계산 비용이 커지고 원하지 않는 패턴을 학습할 수도 있다.
중간층은 활성화 함수로 relu를 사용하고 마지막 층은 확률을 출력하기 위해 sigmoid 활성화 함수를 사용한다. relu는 음수를 0으로 만드는 함수이고, sigmoid는 임의의 값을 0과 1사이로 압축하므로 출력 값을 확률처럼 해석할 수 있다. 다음은 각각 relu 함수와 sigmoid 함수이다.
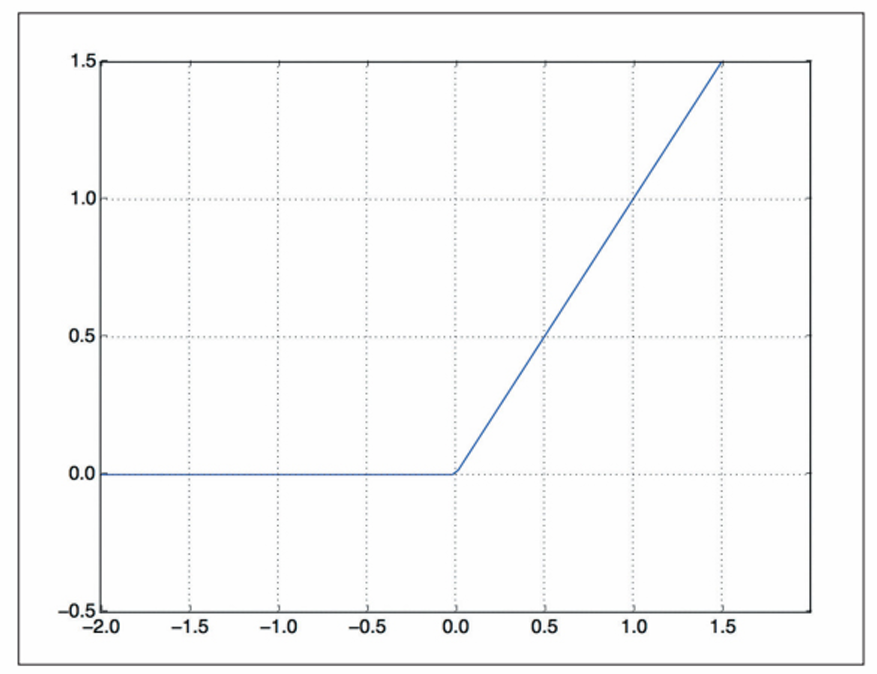
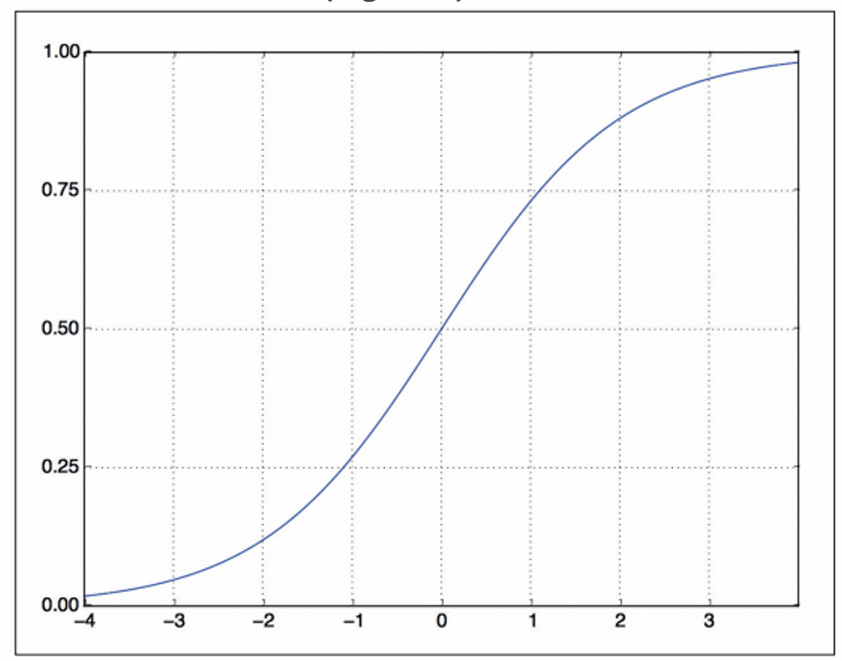
마지막으로 손실 함수와 옵티마이저를 선택해야 한다. 이진 분류 모델이고 모델의 출력이 확률이기 때문에 binary_crossentropy 손실이 적합하다. 이 함수가 유일한 선택은 아니고 mean_squared_error도 사용할 수 있다. 확률을 출력하는 모델을 사용할 때는 크로스엔트로피가 최선의 선택이다. 크로스엔트로피(crossentropy)는 정보 이론 분야에서 온 개념으로 확률 분포 간의 차이를 측정한다. 여기에서는 원본 분포와 예측 분포 사이를 측정한다.
옵티마이저는 rmsprop을 사용한다. 이 옵티마이저는 일반적으로 거의 모든 문제에 기본 선택으로 좋다. 다음은 rmsprop 옵티마이저와 binary_crossentropy 손실 함수로 모델을 설정하는 단계이다. 훈련하는 동안 정확도를 사용하여 모니터링한다.
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
훈련 검증
딥러닝 모델은 훈련 데이터에서 평가해서는 안 된다. 검증 세트를 사용하여 훈련 과정 중에 모델의 정확도를 모니터링하는 것이 표준 관행이다. 여기에서는 다음과 같이 원본 훈련 데이터에서 1만 개의 샘플을 떼어 검증 세트를 만든다.
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
이제 512개의 샘플씩 미니 배치를 만들어 20번의 에포크 동안 모델을 훈련시킨다. 동시에 따로 떼어 놓은 1만 개의 샘플에서 손실과 정확도를 측정한다. 이렇게 하려면 validation_data 매개변수에 검증 데이터를 전달해야한다.
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
model.fit() 메서드는 History 객체를 반환한다. 이 객체는 훈련하는 동안 발생한 모든 정보를 담고 있는 딕셔너리인 history 속성을 가지고 있다.

이 딕셔너리는 훈련과 검증하는 동안 모니터링할 측정 지표당 하나씩 모두 4개의 항목을 담고 있다. 다음은 맷플롯립을 사용하여 훈련과 검증 데이터에 대한 손실과 정확도를 그리는 코드이다.
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict["loss"]
val_loss_values = history_dict["val_loss"]
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, "bo", label="Training loss")
plt.plot(epochs, val_loss_values, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
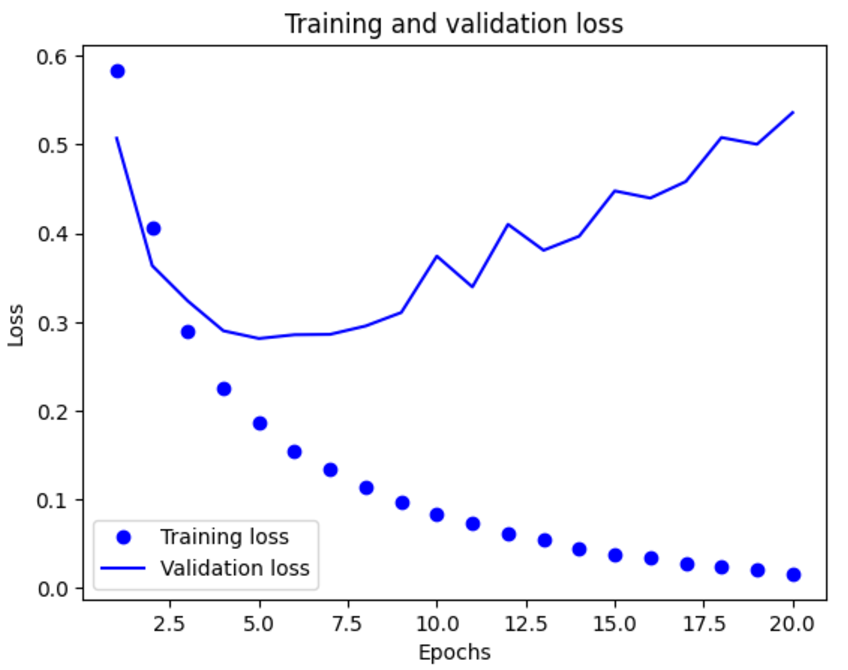
plt.clf()
acc = history_dict["accuracy"]
val_acc = history_dict["val_accuracy"]
plt.plot(epochs, acc, "bo", label="Training acc")
plt.plot(epochs, val_acc, "b", label="Validation acc")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
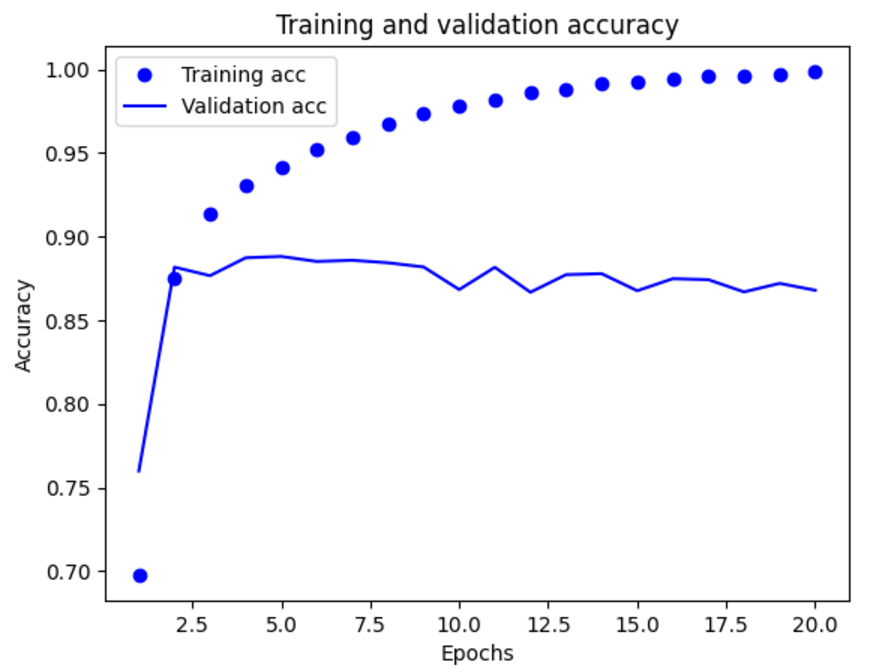
여기서 볼 수 있듯이 훈련 손실이 epoch마다 감소하고 훈련 정확도는 epoch 마다 증가한다. 경사 하강법 최적화를 사용했을 때 반복마다 최소화되는 것이 손실이므로 기대했던 대로다. 하지만 검증 손실과 정확도는 이와 같지 않다. 네 번째 에포그에서 그래프가 역전되는 것 같다. 이것이 훈련 세트에서 잘 작동하는 모델이 처음 보는 데이터에서는 잘 작동하지 않을 수 있다는 사례이다. 이를 과대적합(overfitting)되었다고 한다. 네 번째 epoch 이후부터 훈련 데이터에 과도하게 최적화되어 훈련 데이터에 특화된 표현을 학습하므로 훈련 세트 이외의 데이터에는 일반화되지 못한다.
이런 경우에 과대적합을 방지하기 위해 네 번째 epoch 이후에 훈련을 중지할 수 있다. 처읍부터 다시 새로운 신경망을 네 번의 epoch 동안만 훈련하고 테스트 데이터에서 평가해 본다.
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)

첫 번째 숫자는 테스트 손실이고, 두 번째 숫자는 테스트 정확도이다. 아주 단순한 방시으로도 88%의 정확도를 달성했다.
훈련된 모델로 새로운 데이터에 대해 예측하기
모델을 훈련시킨 후 이를 실전 환경에서 사용해본다. predict 메서드를 사용해서 어떤 리뷰가 긍정일 확률을 예측할 수 있다.

이 모델은 어떤 샘플에 대해 확신을 가지고 있지만(0.99 이상, 0.01 이하) 어떤 샘플에 대해서는 확신이 부족하다.
뉴스 기사 분류: 다중 분류 문제
로이터 뉴스를 46개의 상호 배타적인 토픽으로 분류하는 신경망을 만들어 본다. 클래스가 많기 때문에 이 문제는 다중 분류(multiclass classification)의 예이다. 각 데이터 포인트가 정확히 하나의 범주로 분류되기 때문에 좀 더 정확히 말하면 단일 레이블 다중 분류(single-label, multiclass classification) 문제이다. 각 데이터 포인트가 여러 개의 범주에 속할 수 있다면 이것은 다중 레이블 다중 분류 문제가 된다.
로이터 데이터셋
로이터에서 공개한 짧은 뉴스 기사와 토픽의 집합인 로이터 데이터셋을 사용한다. 이 데이터셋은 텍스트 분류를 위해 널리 사용되는 간단한 데이터셋이다. 46개의 토픽이 있으며 어떤 토픽은 다른 것에 비해 데이터가 많다. 각 토픽은 훈련 세트에 최소한 10개의 샘플을 가지고 있다.
IMDB, MNIST와 마찬가지로 로이터 데이터셋은 케라스에 포함되어 있다.
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
num_words=10000 매개변수는 데이터에서 가장 자주 등장하는 단어 1만 개로 제한한다. 여기에는 8982개의 훈련 샘플과 2246개의 테스트 샘플이 있다.

IMDB 리뷰처럼 각 샘플은 정수 리스트이다(단어 인덱스).

어떻게 단러로 디코딩 하는지 알아본다.
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# 0, 1, 2는 '패딩', '문서 시작', '사전에 없음
decoded_newswire = " ".join([reverse_word_index.get(i - 3, "?") for i in train_data[0]])
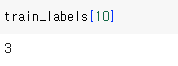
샘플에 연결된 레이블은 토픽의 인덱스로 0과 45 사이의 정수이다.
데이터 준비
데이터를 벡터로 변환한다.
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
레이블을 벡터로 바꾸는 방법은 두 가지이다. 레이블의 리스트를 정수 텐서로 변환하는 원-핫 인코딩(one-hot encoding)을 사용하는 것이다. 원-핫 인코딩이 범주형 데이터에 널리 사용되기 때문에 범주형 인코딩(categorical encoding)이라고도 부른다. 이 경우 레이블의 원-핫 인코딩은 각 레이블의 인덱스 자리는 1이고 나머지는 모두 0인 벡터이다. 예를 들어 다음과 같다.
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
y_train = to_one_hot(train_labels)
y_test = to_one_hot(test_labels)
케라스에는 이를 위한 내장 함수가 있다.

모델 구성
이 토픽 분류 문제는 이전의 영화 리뷰 문제와 비슷해 보인다. 두 경우 모두 짧은 텍스트를 분류하는 것이다. 여기에서는 새로운 제약 사항이 추가되었다. 출력 클래스의 개수가 2에서 46개로 늘어난 점이다. 즉, 출력 공간의 차원이 훨씬 커졌다.
이전에 사용했던 것처럼 Dense 층을 쌓으면 각 층은 이전 층의 출력에서 제공한 정보만 사용할 수 있다. 한 층이 분류 문제에 필요한 일부 정보를 누락하면 그다음 층에서 이를 복원할 방법이 없다. 각 층은 잠재적으로 정보의 병목(information bottleneck)이 될 수 있다. 이전 예제에서 16차원을 가진 중간층을 사용했지만 16차원 공간은 46개의 클래스를 구분하기에 너무 제약이 많을 것 같다. 이렇게 규모가 작은 층은 유용한 정보를 완전히 잃게 되는 정보의 병목 지점처럼 동작할 수 있다.
이런 이유로 좀 더 규모가 큰 층(64개의 유닛)을 사용한다.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(46, activation="softmax")
])
이 구조에서 주목해야 할 점이 두 가지 있다.
- 마지막 Dense 층의 크기가 46이다.
- 각 입력 샘플에 대해 46차원의 벡터를 출력한다는 뜻
- 이 벡터의 각 원소(각 차원)는 각기 다른 출력 클래스가 인코딩된 것
- 마지막 층에 softmax 활성화 함수가 사용되었다.
- 각 입력 샘플마다 46개의 출력 클래스에 대한 확률 분포를 출력한다.
- 즉, 46차원의 출력 벡터를 만들며 output[i]는 어떤 샘플이 클래스 i에 속할 확률이다.
- 46개의 값을 모두 더하면 1이 된다.
이런 문제에 사용할 최선의 손실 함수는 categorical_crossentropy이다. 이 함수는 두 확률 분포 사이의 거리를 측정한다. 여기에서는 모델이 출력한 확률 분포의 진짜 레이블의 분포 사이의 거리이다. 두 분포 사이의 거리를 최소화함으로써 진짜 레이블에 가능한 가까운 출력을 내도록 모델을 훈련하게 된다.
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
훈련 검증
훈련 데이터에서 1000개의 샘플을 따로 떼어서 검증 세트를 사용한다.
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = y_train[:1000]
partial_y_train = y_train[1000:]
이제 20번의 에포크로 모델을 훈련시킨다.
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
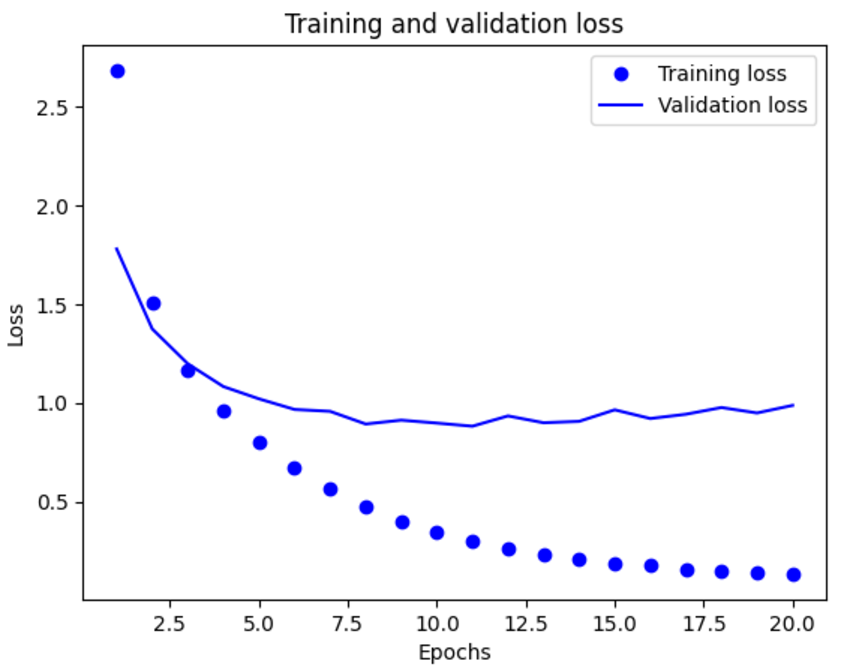
마지막으로 손실과 정확도 곡선을 그린다.
import matplotlib.pyplot as plt
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
plt.clf()
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
plt.plot(epochs, acc, "bo", label="Training accuracy")
plt.plot(epochs, val_acc, "b", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
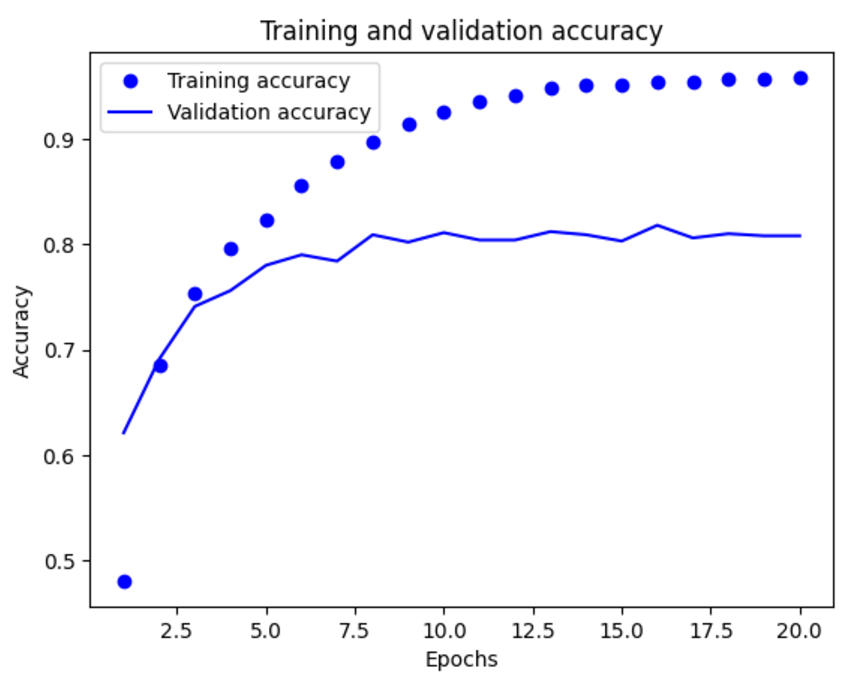
이 모델은 아홉 번째 에포크 이후에 과대적합이 시작된다. 아홉 번의 에포크로 새로운 모델을 훈련하고 테스트 세트에서 평가한다.
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(46, activation="softmax")
])
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
model.fit(x_train,
y_train,
epochs=9,
batch_size=512)
results = model.evaluate(x_test, y_test)
최종 결과는 다음과 같다.
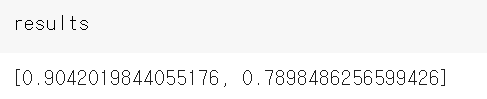
이 모델은 80%애 가까운 정확도를 달성했다. 균형 잡힌 이진 분류 문제에서 완전히 무작위로 분류하면 50%의 정확도를 달성한다. 하지만 이 문제는 46개의 클래스가 있고 클래스 비율이 같지 않다. 랜덤한 분류기를 사용해서 예측하면 정확도가 얼마나 나오는지 봐본다.

여기에서 볼 수 있듯이 랜덤한 분류기는 약 19%의 분류 정확도를 달성한다. 따라서 앞서 확인한 모델의 결과는 꽤 좋은 것 같다.
새로운 데이터에 대해 예측하기
새로운 샘플로 모델의 predict 메서드를 호출하면 각 샘플에 대해 46개의 토픽에 대한 클래스 확률 분포를 반환한다. 텍스트 데이터 전체에 대한 토픽을 예측해 본다.
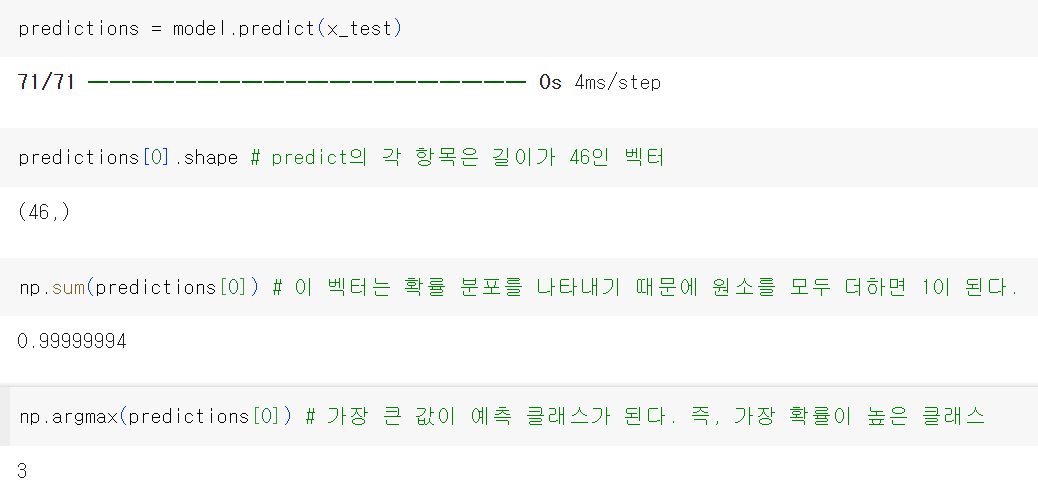
레이블과 손실을 다루는 다른 방법
레이블은 인코딩하는 다른 방법은 다음과 같이 정수 텐서로 변환하는 것이다.
y_train = np.array(train_labels)
y_test = np.array(test_labels)
이 방식을 사용하려면 손실 함수 하나만 sparse_categorical_crossentropy로 바꾸면 된다.
충분히 큰 중간층을 두어야 하는 이유
마지막 출력이 46차원이기 때문에 중간층의 중간 유닛이 46개보다 많이 차이나서는 안된다. 46차원보다 훨씬 작은 중간층을 두면 정보의 병목이 일어난다.
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(4, activation="relu"),
layers.Dense(46, activation="softmax")
])
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=["accuracy"])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
검증 정확도는 감소되었음을 확인할 수 있다. 어떤 손실의 원인 대부분은 많은 정보를 중간층의 저차원 표현 공간으로 압축하려고 했기 때문이다. 이 모델은 필요한 정보 대부분을 4차원 표현 안에 구겨 넣었지만 전부는 넣지 못했다.
댓글남기기