기계학습 기초 팀 프로젝트
Updated:
Embedding
Word2Vec
분산 표현(distributed representation)은 단어의 의미를 다차원 공간에서 벡터화하는 방법을 사용하는 표현이다. 그리고 분산 표현을 이용하여 단어 간 의미적 유사성을 벡터화하는 작업을 임베딩(embedding)이라 부르며 이렇게 표현된 벡터를 임베딩 벡터(embedding vector)라고 한다.
분산 표현 방법은 기본적으로 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법이다. 이 가정은 ‘비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다.’라는 가정이다. 예를 들어, “강아지”란 단어는 “귀엽다”, “예쁘다”, “애교” 등의 단어가 주로 함께 등장하는데 분포 가설에 따라서 해당 내용을 가진 텍스트의 단어들을 벡터화한다면 해당 단어 벡터들은 유사한 벡터값을 가진다. 분산 표현은 분포 가설을 이용하여 텍스트를 학습하고, 단어의 의미를 벡터의 여러 차원에 분산하여 표현한다.
Word2Vec의 학습 방식에는 CBOW(Continuous Bag of Words)와 Skip-Grap 두 방식이 있다.
- CBOW: 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법
- Skip-Gram: 중간에 있는 단어들을 입력을 주변 단어들을 예측하는 방법
CBOW
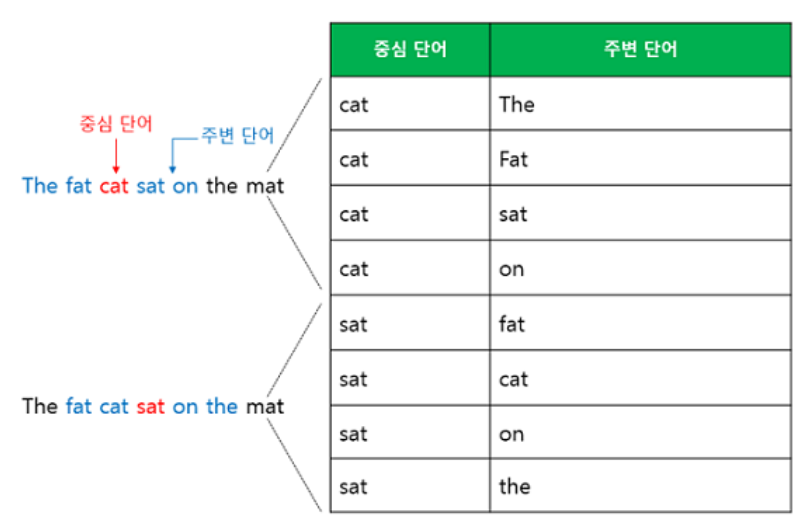
“The fat cat sat on the mat”예문이 있다고 가정하자. [‘The’, ‘fat’, ‘cat’, ‘on’, ‘the’, ‘mat’]으로부터 sat을 예측하는 것은 CBOW가 하는 일이다. 이때 예측해야하는 단어 sat을 중심 단어(center word)라고 하고, 예측에 사용되는 단어들을 주변 단어(context word)라고 한다.
중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정해야 하는데 이 범위를 윈도우(window)라고 한다. 예를 들어 윈도우 크기가 2이고, 예측하고자 하는 중심 단어가 sat이라고 한다면 앞의 두 단어인 fat와 cat, 그리고 뒤의 두 단어인 on, the를 입력으로 사용한다. 윈도우 크기가 n이라고 한다면, 실제 중심 단어를 예측하기 위해 참고하려고 하는 주변 단어의 개수는 2n이다.
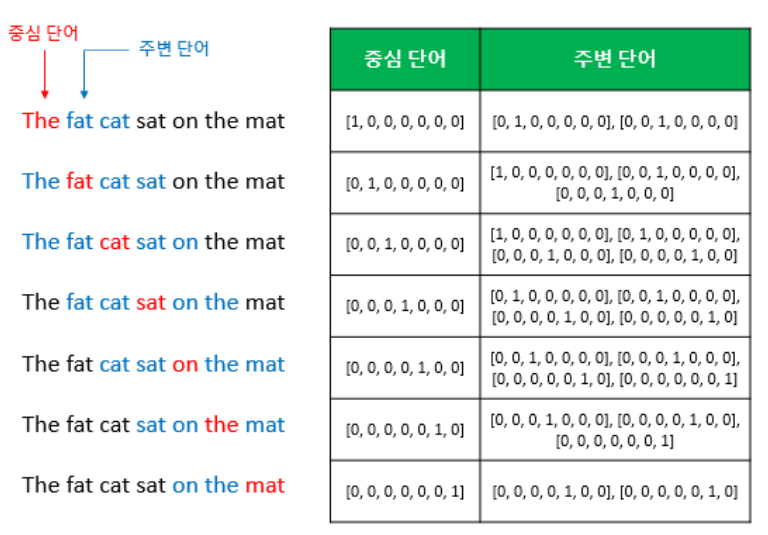
윈도우 크기가 정해지면 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터 셋을 만드는데 이 방법을 슬라이딩 윈도우(slididng window)라고 한다.
위 그림은 중심 단어와 주변 단어의 변화는 윈도우 크기가 2일때, 슬라이딩 원도우가 어떤 식으로 이루어지면서 데이터 셋을 만드는지 보여준다. Word2Vec에서 입력은 모두 원-핫 벡터가 되어야 하는데, 우측 그림은 중심 단어와 주변 단어를 어떻게 선택했을 때에 따라서 각각 어떤 원-핫 벡터가 되는지를 보여준다.
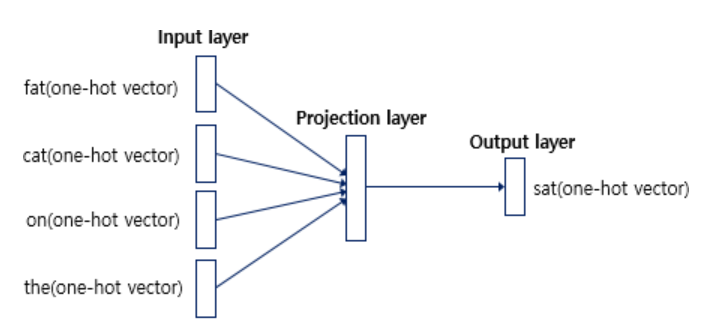
CBOW의 인공 신경망을 간단히 도식화하면 위와 같다. 입력층(Input layer)의 입력으로서 앞, 뒤로 사용자가 정한 윈도우 크기 범위 안에 있는 주변 단어들의 원-핫 벡터가 들어가게 되고, 출력층(Output layer)에서 예측하고자 하는 중간 단어의 원-핫 벡터가 레이블로서 필요한다. 위 그림에서 알 수 있는 사실은 Word2Vec은 은닉층이 다수인 딥 러닝 모델이 아니라 은닉층이 1개인 얕은 신경망(shallow neural network)이라는 점이다. 또한 활성화 함수가 존재하지 않으며 룩업 테이블이라는 연산을 담담하는 층으로 투사층(projection layer)이라고 부른다.
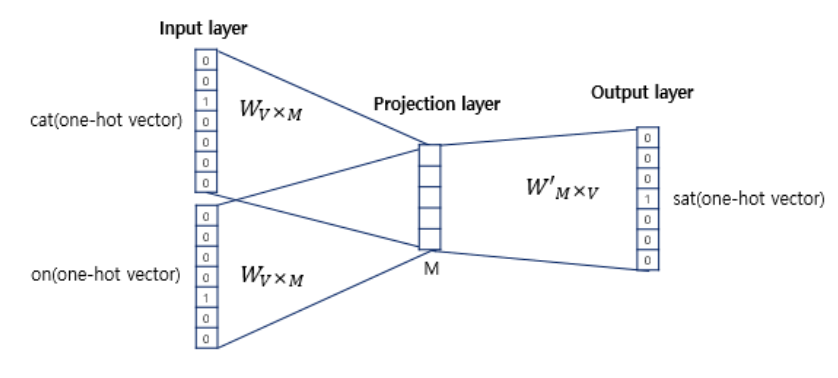
CBOW의 인공 신경망을 좀 더 확대하여, 동작 메커니즘에 대해서 상세하게 알아본다. 위 그림에서 주목해야할 것은 두 가지이다.
- 투사층의 크기가 M이다.
- CBOW에서 투사층의 크기 M은 임베딩하고 난 벡터의 차원이 된다.
- 위 그림에서 투사층의 크기 M=5이므로 CBOW를 수행하고나서 얻는 각 단어의 임베딩 벡터의 차원은 5가된다.
- 입력층과 투사층 사이의 가중치 W는 V $\times$ M 행렬이며, 투사층에서 출력층사이의 가중치 W`는 M $\times$ V 행렬이다.
- 위 그림에서 one-hot 벡터의 차원이 7이고, M이 5라면 가중치 W는 $7 \times 5$ 행렬이고, W`는 $5 \times 7$ 행렬이 될 것이다.
- 두 행렬은 동일한 행렬을 전치한 것이 아니라, 서로 다른 행렬이다.
- 인공 신경망의 훈련 전에 이 가중치 행렬 W와 W`는 랜덤 값을 가지게 된다.
- CBOW는 주변 단어로 중심 단어를 더 정확히 맞추기 위해 계속해서 이 W와 W`를 학습해가는 구조이다.
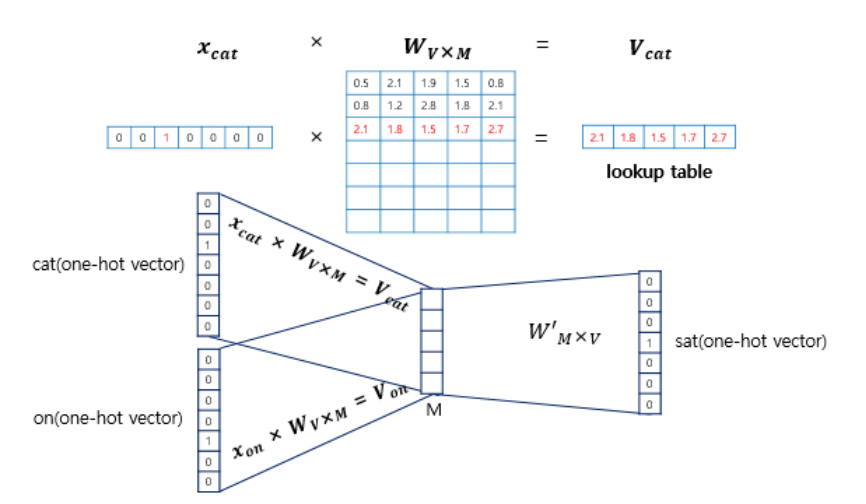
입력으로 들어오는 주변 단어의 one-hot 벡터와 가중치 W행렬의 곱이 어떻게 이루어지는지 본다. 위 그림에서는 각 주변 단어의 one-hot 벡터를 $x$로 표기하였다. 입력 벡터는 one-hot 벡터이다. i번째 인덱스에 1이라는 값을 가지고 그외의 0의 값을 가지는 입력 벡터와 가중치 W행렬의 곱은 사실 W행렬의 i번째 행을 그대로 읽어오는 것과(lookup) 동일하다. 이 작업을 룩업 테이블(loopup table)이라고 한다. CBOW의 목적은 W와 W`를 잘 훈련시키는 것인 이유는 여기서 lookup해온 W의 각 행벡터가 Word2Vec 학습 후에는 가 단어의 M차원의 임베딩 벡터로 간주되기 때문이다.
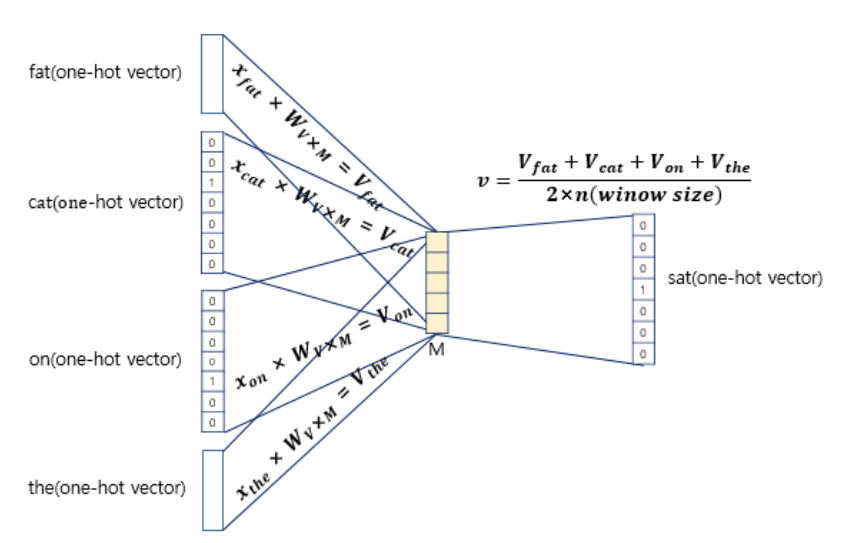
위와같이 주변 단어의 one-hot 벡터에 대해서 가중치 W가 곱해서 생겨진 결과 벡터들은 투사층에서 만나 이 벡터들의 평균인 벡터를 구하게 된다. 만약 n=2라면, 입력 벡터의 총 개수는 2n이므로 중간 단어를 예측하기 위해서는 총 4개가 입력 벡터로 사용된다. 그렇기 때문에 평균을 구하는 부분은 CBOW가 Skip-Gram과 다른 차이점이기도 한다(Skip-gram은 평균을 구하지 않는다).
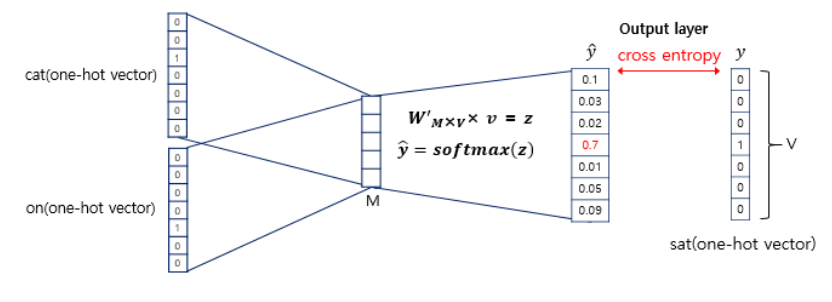
이렇게 구해진 평균 벡터는 두번째 가중치 행렬 W`와 곱해진다. 곱셈의 결과로는 one-hot 벡터들과 차원이 V로 동일한 벡터가 나온다. 만약 입력 벡터의 차원이 7이었다면 여기서 나오는 벡터도 마찬가지이다.
Skip-Gram
CBOW에서는 주변 단어를 통해 중심 단어를 예측했다면, Skip-gram은 중심 단어에서 주변 단어를 예측한다. 윈도우 크기가 2일 때, 데이터셋은 다음과 같이 구성된다.
인공 신경망을 도식화하면 다음과 같다.
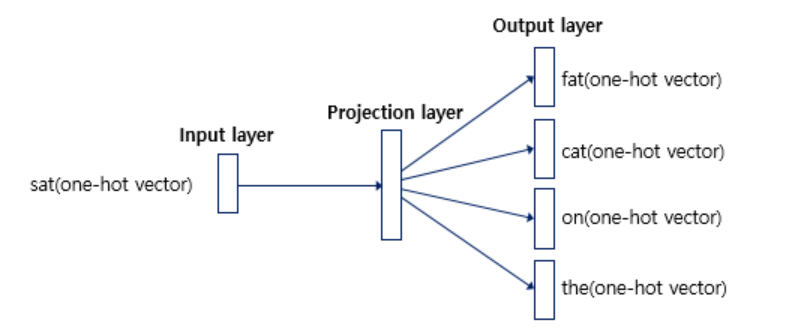
중심 단어에 대해서 주변 단어를 예측하므로 투사층에서 벡터들의 평균을 구하는 과정은 없다. 여러 논문에서 성능 비교를 진행했을 때 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있다.
Google colab
Google colab 환경에서 Word2Vec 임베딩 기법을 사용하였다. 먼저 라이브러리와 환경설정을 해준다.
!pip install gensim
!pip install kaggle
# kaggle.json 파일을 업로드(Kaggle API 토큰)
from google.colab import files
files.upload()
!mkdir /root/.kaggle
!mv kaggle.json /root/.kaggle/ # kaggle.json 파일을 이동합니다.
!chmod 600 /root/.kaggle/kaggle.json # 파일 권한을 설정합니다.
import kagglehub
# Download latest version
path = kagglehub.dataset_download("zeyadkhalid/mbti-personality-types-500-dataset")
print("Path to dataset files:", path)
# 다운로드 확인
!ls /root/.cache/kagglehub/datasets/zeyadkhalid/mbti-personality-types-500-dataset/versions/1
# 'MBTI 500' 출력
이제 데이터 전처리를 진행한다. 이때 텍스트 데이터에서 불필요한 기호나 특수문자를 제거하고 토큰화를 진행한다.
import pandas as pd
import re
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
import nltk
# nltk 다운로드 (처음에만 필요)
nltk.download('punkt')
# 데이터 불러오기
data = pd.read_csv('/root/.cache/kagglehub/datasets/zeyadkhalid/mbti-personality-types-500-dataset/versions/1/MBTI 500.csv')
# 텍스트 데이터 전처리 함수
def preprocess_text(text):
# 특수문자 제거
text = re.sub(r'[^a-zA-Z\s]', '', text)
# 소문자로 변환
text = text.lower()
# 단어 토큰화
tokens = word_tokenize(text)
return tokens
# 전체 데이터셋에 적용
data['processed_posts'] = data['posts'].apply(preprocess_text)
이제 Word2Vec 모델을 생성하고 학습한다. vector_size, window, min_count 파라미터를 조정하여 최적화할 수 있다.
# Word2Vec 모델 학습
sentences = data['processed_posts'].tolist() # 각 문장은 단어 리스트 형태로 되어 있음
model = Word2Vec(sentences, vector_size=100, window=5, min_count=5, workers=4)
위 코드는 임베딩 차원을 100으로 설정하고(vector_size = 100), 주변 단어 범위를 5로 설정하며(window = 5), 최소 등장 횟수가 5번 이상인 단어만 학습(min_count=5)한다.
이제 특정 단어의 벡터를 확인하거나, 두 단어 간 유사도를 계산해볼 수 있다.
# 특정 단어의 벡터 확인
word_vector = model.wv['happy'] # 예: 'happy'라는 단어의 벡터
print("Vector for 'happy':", word_vector)
# 두 단어 간 유사도 확인
similarity = model.wv.similarity('happy', 'sad')
print("Similarity between 'happy' and 'sad':", similarity)
# 가장 유사한 단어들 확인
similar_words = model.wv.most_similar('happy', topn=5)
print("Words similar to 'happy':", similar_words)
위 코드의 출력은 다음과 같다.
Vector for 'happy': [ 1.4255826 -1.5716363 0.71107405 -3.0565484 -1.0278993 1.9680144
1.0528193 -1.0435128 1.0365224 -0.2930649 1.3984013 0.23165604
0.0243955 -1.0992837 -1.4693928 1.7648761 0.02888692 -0.7816044
-1.7657107 2.9703147 2.1535544 -0.1516394 -0.26491222 2.174404
0.36545572 -1.2980185 1.7559011 1.3997724 -0.9306913 1.982815
1.3669397 -1.2858647 -0.40412012 -0.6579812 -1.3302454 -1.6213641
0.41277957 1.5128129 4.259359 -0.18817009 0.8318037 2.050264
0.48027217 1.7636526 0.1589853 1.2742721 1.5448053 -0.19221221
0.5797721 1.7076429 -0.7038099 0.37807024 0.7176324 1.2495503
-0.4687499 -2.1926892 1.6891656 -0.26097897 1.2702137 3.1513324
-1.3593745 1.1759146 -0.01774924 1.3081243 0.04501643 -0.08060618
-0.9311768 -1.7017056 1.0833048 -1.2728391 2.627176 1.2560489
-1.4214243 -1.9473025 -0.9991771 -0.96355957 2.6458352 -0.32180926
0.14940318 0.50062394 2.7165327 -0.97194344 0.08025222 -3.4160893
-2.3274484 1.466514 -1.0903581 0.83885485 -1.0782374 0.859381
-1.395683 -2.5541625 -0.94345 0.6699258 -2.4244027 -1.32647
0.80589586 0.51826155 1.6350162 0.5907336 ]
Similarity between 'happy' and 'sad': 0.65140444
Words similar to 'happy': [('unhappy', 0.7426812052726746), ('miserable', 0.6960904598236084), ('sad', 0.6514044404029846), ('thankful', 0.6046780943870544), ('want', 0.5975086688995361)]
위 출력을 보면 happy와 sad는 의미적으로 반대되는 단어이지만, 단어 벡터로 표현할 때는 단순히 절차가 아닌 맥락 속에서의 사용 빈도와 문맥적 유사성을 바탕으로 유사도를 계산한다. Word2Vec 모델은 단어가 같은 문맥에서 자주 나타나는 경우 벡터 간 유사도가 높아지도록 학습된다.
happy와 sad는 감정 표현으로 자주 사용되기 때문에, 비슷한 문맥에서 함께 등장할 가능성이 높다. 예를 들어, “I feel happy”와 “I feel sad”같은 문장에서처럼 감정 상태를 나타낼 떄 같은 문맥에 쓰이는 경우가 많다. 이처럼 상반된 감정이더라고 같은 맥락에서 자주 쓰이는 경우가 있어 Word2Vec 모델에서는 이러한 단어들이 유사하게 학습될 수 있다.
Overriding
위 데이터셋은 자료가 각각의 MBTI 별로 균일하지 않아 Overring을 적용했다.
import numpy as np
import pandas as pd
from gensim.models import Word2Vec
from imblearn.over_sampling import RandomOverSampler
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import kagglehub
path = kagglehub.dataset_download("zeyadkhalid/mbti-personality-types-500-dataset")
print("Path to dataset files:", path)
data = pd.read_csv(f"{path}/MBTI 500.csv")
texts = data['posts'].values
labels = pd.get_dummies(data['type']).values
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
vocab_size = len(word_index) + 1
max_length = 100
padded_sequences = pad_sequences(sequences, maxlen=max_length)
sentences = [text.split() for text in texts]
word2vec_model = Word2Vec(sentences, vector_size=10, window=2, min_count=4, sg=1, workers=4)
embedding_matrix = np.zeros((vocab_size, 10))
for word, i in word_index.items():
if word in word2vec_model.wv:
embedding_matrix[i] = word2vec_model.wv[word]
X_train, X_test, y_train, y_test = train_test_split(padded_sequences, labels, test_size=0.2, random_state=42)
y_train_labels = np.argmax(y_train, axis=1)
oversampler = RandomOverSampler(random_state=42)
X_train_resampled, y_train_resampled = oversampler.fit_resample(X_train, y_train_labels)
y_train_resampled = pd.get_dummies(y_train_resampled).values
try:
similarity = word2vec_model.wv.similarity("man", "lady")
print("Similarity between 'man' and 'lady':", similarity)
except KeyError:
print("The words 'man' or 'lady' are not in the Word2Vec vocabulary.")
위 코드에서 시도한 Overriding 기법은 RamdomOverSampler로 이미 존재하는 데이터를 무작위로 추출하여 새로운 데이터를 생성하는 것이다. 즉, 중복된 데이터를 기존의 데이터에 추가하여 데이터의 절대적인 양을 늘리는 것이다.
fit_resample 메서드를 통해 소수 클래스의 데이터를 복제하여 학습용 데이터의 클래스 비융을 맞추었다.
LSTM
LSTM(Long Short Term Memory)은 RNN 한 종류로, RNN의 장기 의존성 문제(long-term dependencies)를 해결하기 위해서 나온 모델이다. 따라서 직전 데이터 뿐만 아니라, 좀 더 거시적으로 과거 데이터를 고려하여 미래 데이터를 예측하기 위해 나온 모델이다.
LSTM 네트워크 구조
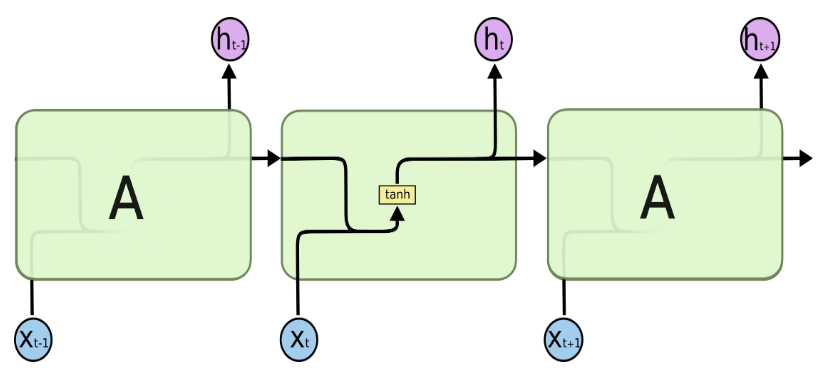
위의 그림과 같이 모든 RNN은 Neural Network 모듈을 반복시키는 체인과 같은 형태를 하고 있다. 기본적으로 RNN에서는 이렇게 반복되는 간단한 구조를 가지고 있다.
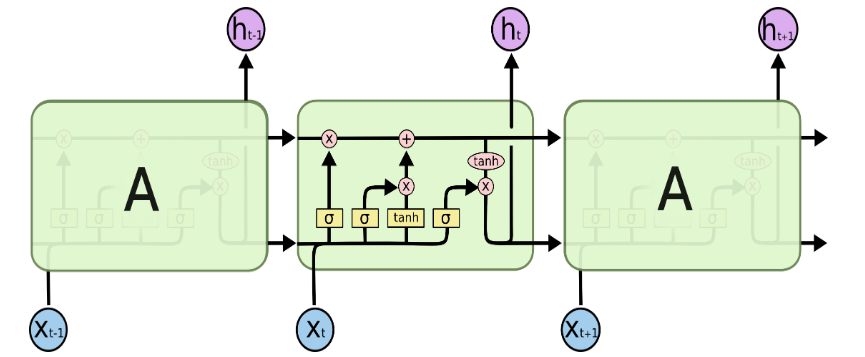
LSTM도 똑같이 체인 구조를 가지고 있지만, 4개의 Layer가 특별한 방식으로 서로 정보를 주고 받도록 되어있다.
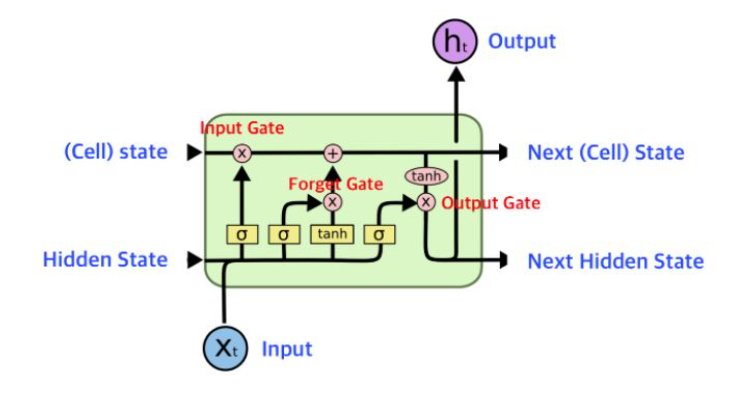
- Cell State
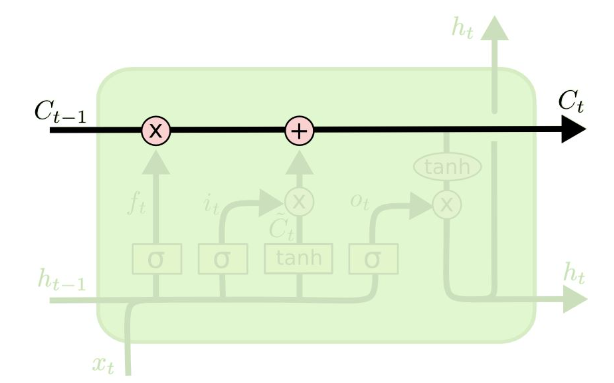
- LSTM의 핵심 부분으로, 컨베이어 벨트와 같아서 작은 linear interaction만을 적용시키면서 전체 체인을 계속 구동 시킨다.
- 정보가 전혀 바뀌지 않고 그대로만 흐르게 하는 부분이다.
- State가 꽤 오래 경과하더라고 Gradient가 잘 전파된다.
- Gate라고 불리는 구조에 의해서 정보가 추가되거나 제거 되며, Gate는 Training을 통해서 어떤 정보를 유지하고 버릴지 학습한다.
- Forget Gate
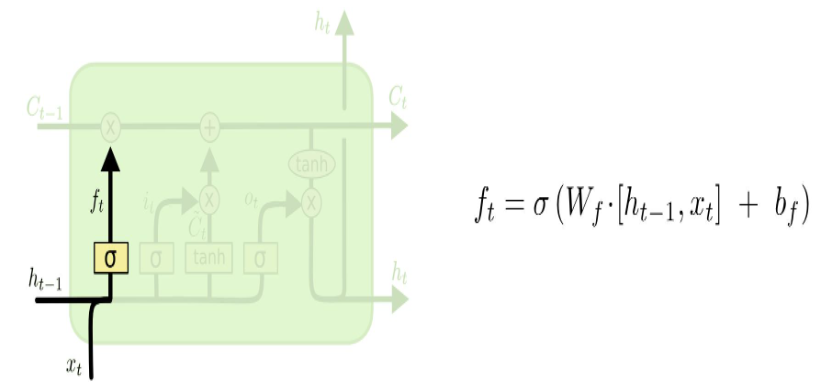
- 과거 정보를 버릴지 말지 결정하는 과정으로, 이 결정은 Sigmoid layer에 의해서 결정된다.
- 이 과정에서는 $h_t - 1$과 $x_t$를 받아서 0과 1 사이의 값을 $C_t - 1$에 보내준다.
- 그 값이 1이면 “모든 정보를 보존해라”가 되고, 0이면 “죄다 갖다 버려라”가 된다.
- Input Gate
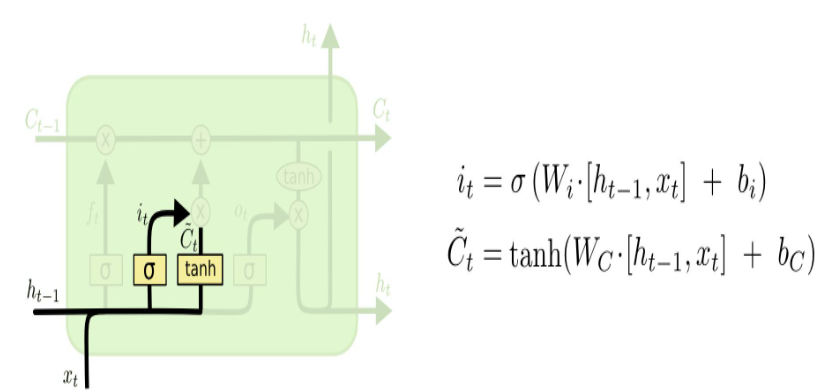
-
현재 정보를 기억하기 위한 게이트로, 현재의 Cell state 값에 얼마나 더할지 말지를 정하는 역할을 한다.
-
Update
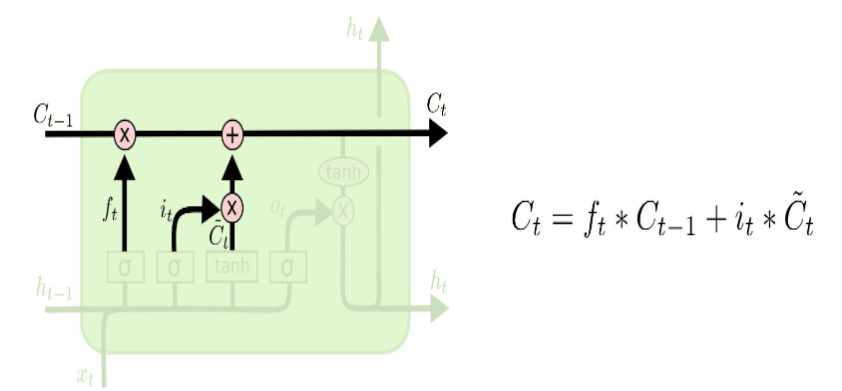
- 과거 Cell State를 새로운 State로 업데이트 하는 과정이다.
-
Forget Gate를 통해서 얼마나 버릴지, Input Gate에서 얼마나 더할지를 정했으므로 이 Update과정에서 계산을 해서 Cell state로 업데이트 해준다.
- Output Gate
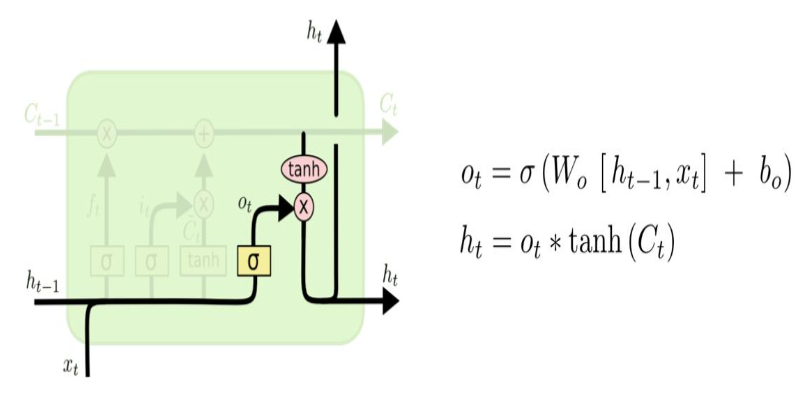
- 어떤 출력값을 출력할지 결정하는 과정으로 최종적으로 얻어진 Cell State 값을 얼마나 빼낼지 결정하는 역할을 해준다.
Embedding 모델에 LSTM 적용
이제 Embedding을 한 모델에 LSTM을 적용해본다.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
# 모델 설정
embedding_dim = 10 # Word2Vec 벡터 크기와 동일
lstm_units = 64 # LSTM의 출력 차원 수
# Sequential 모델 생성
model = Sequential()
# 임베딩 레이어: Word2Vec 임베딩 행렬을 사용
model.add(Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
weights=[embedding_matrix], # embedding에서 생성한 matrix
input_length=max_length,
trainable=False)) # 사전 학습된 임베딩 고정
# LSTM 레이어 추가
model.add(LSTM(units=lstm_units, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=lstm_units))
# 출력 레이어: 16개의 MBTI 유형을 예측하므로 노드 수는 16
model.add(Dense(16, activation='softmax'))
# 모델 컴파일
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 모델 학습
history = model.fit(X_train_resampled, y_train_resampled,
epochs=10,
batch_size=64,
validation_split=0.2)
# 모델 평가
loss, accuracy = model.evaluate(X_test, y_test)
print("Test Loss:", loss)
print("Test Accuracy:", accuracy)
- 모델 설정
- embedding_dim: 임베팅 벡터의 차원으로, Word2Vec 모델에서 학습된 벡터의 크기와 동일하게 설정된다.
- lstm_units: LSTM 레이어의 유닛 수로, LSTM의 출력 크기를 의미한다. 더 높은 값을 사용하면 모델의 표현력이 커진다.
- Sequential 모델 생성
- 모델의 구조를 순차적으로 정의
- 임베딩 레이어 추가
- Embedding 레이어: 단어 인덱스를 해당 임베딩 벡터로 변환
- input_dim: 단어 사전의 크기
- output_dim: 각 단어의 임베딩 벡터 크기
- weights: 사전 학습된 Word2Vec 임베딩 행렬
- input_length: 입력 시퀀스의 최대 길이
- trainable=False: 사전 학습된 임베딩 벡터를 학습 중에 업데이트하지 않고 고정시킴
- LSTM 레이어 추가
- LSTM 레이어
- units: LSTM 레이어의 출력 차원 수이다.
- return_sequence=True: LSTM 레이어의 출력 형태를 제어하는 옵션으로, True로 설정하면 각 타임스템(time step)마다 출력 값을 반환한다. 즉, LSTM 레이어가 입력 시퀀스의 각 시점에 대해 출력 벡터를 생성하여 3D 텐서 형태로 반환한다. 출력 형태는 (batch_size, timesteps, units)로, 입력 시퀀스의 각 시점에 대해 units 차원의 벡터를 반환하는 것이다.
- return_sequence=False: 만약 False로 설정하면, 마지막 타임 스템의 출력 (batch_size, units) 형태의 2D 텐서를 반환하게 된다. 이 설정은 최종 출력만 필요할 때 사용된다.
- Dropout 레이어
- 학습 시 특정 비율의 뉴련을 무작위로 제거하여 과적합을 방지한다.
- 두 번째 LSTM 레이어
- return_sequences=False가 기본값이므로 최종 상태만 출력한다.
- LSTM 레이어
- 출력 레이어 추가
- Dense 레이어
- 노드 수는 16개(MBTI 유형의 수)
- softmax 활성화 함수: 각 클래스의 확률을 출력하도록 설정
- Dense 레이어
- 모델 컴파일
- optimizer: 모델이 학습할 때 가중치(weight)를 업데이트하는 방법을 정의하는 것으로, 네크워크가 손실 함수를 최소화하도록 가중치를 업데이트하여 모델을 최적화한다. Adam은 학습 속도와 안정성이 좋은 옵티마이저이다.
- loss: 모델이 예측한 값과 실제 값 간의 차이를 계산하여 모델의 성능을 평가하는 지표로, 학습 과정에서 옵티마이저는 손실 함수를 최소화하는 방향으로 가중치를 업데이트한다. categorical_crossentropy는 다중 클래스 분류에 적합한 손실함수이다.
- metrics: 모델의 성능을 평가하기 위해 사용하는 지표로, 학습 및 평가 과정에서 출력된다. accuracy는 예측한 클래스가 실제 클래스와 일치하는 비율을 측정하는 지표이다.
- 모델 학습
- fix
- x_train_resampled, y_train_resampled: 오버샘플링된 학습 데이타와 레이블
- epochs: 전체 데이터셋에 대해 반복 학습하는 횟수
- batch_size: 한 번에 학습에 사용하는 데이터의 양
- validation_split: 20%의 데이터를 검증용으로 분리
- fix
- 모델 평가
- evaluate: 테스트 데이터를 사용해 모델의 손실과 정확도를 출력한다.
댓글남기기