데이터 종속성과 정규화
Updated:
정규화의 의미
정규화(normalization)는 자료 저장 공간을 최소화하고 데이터베이스 내의 데이터가 불일치 되는 위험을 최소화하여 좋은 데이터터베이스 스키마를 설계하는 것을 목적으로 하는 것이다. 다음은 데이터베이스 스키마 잘못 설계된 경우를 보여준다.
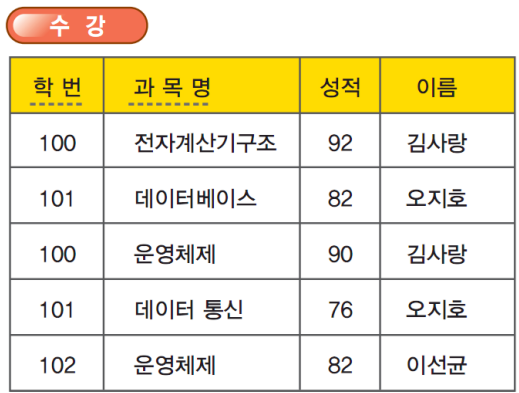
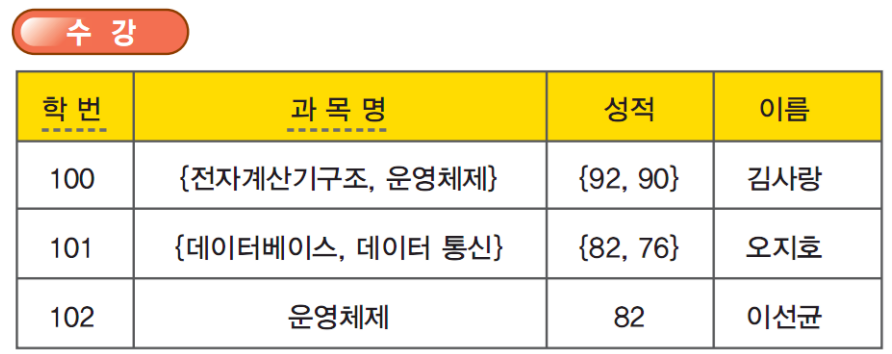
100번 학생이 전자계산기구조와 운영체제라는 두 과목을 신청하였기에 이 학생의 이름은 두번 저장되는 문제점이 발생했다. 중복된 데이터의 저장으로 인해 저장 공간이 낭비된다는 문제점 이외에도 중복되어 저장된 데이터 때문에 릴레이션의 수정, 삽입, 삭제와 같은 조작을 할 때 여러 가지 곤란한 이상(anomaly: 변칙, 이례) 현상이 생긴다. 이상 현상이란 속성 간에 존재하는 여러 종속 관계를 하나의 릴레이션에 표현함으로써 데이터의 중복으로 인해 발생하는 여러 가지 현상이다.
수정 이상
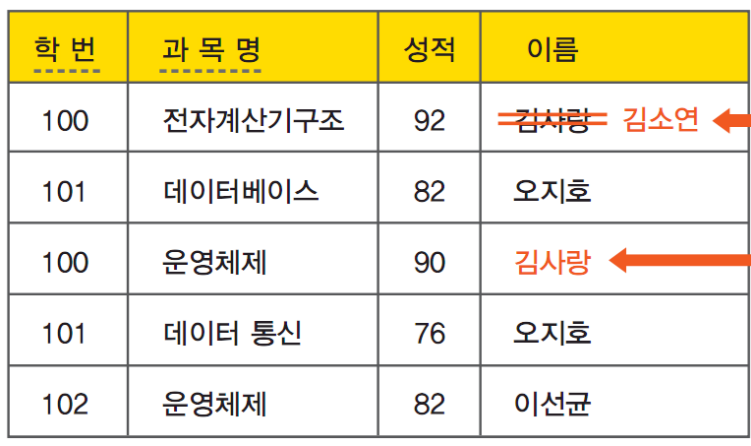
수정 이상이란 중복 데이터 중에서 일부만 갱신되어 정보의 모순이 발생하는 것이다. 다음 예제를 보자.
삽입 이상
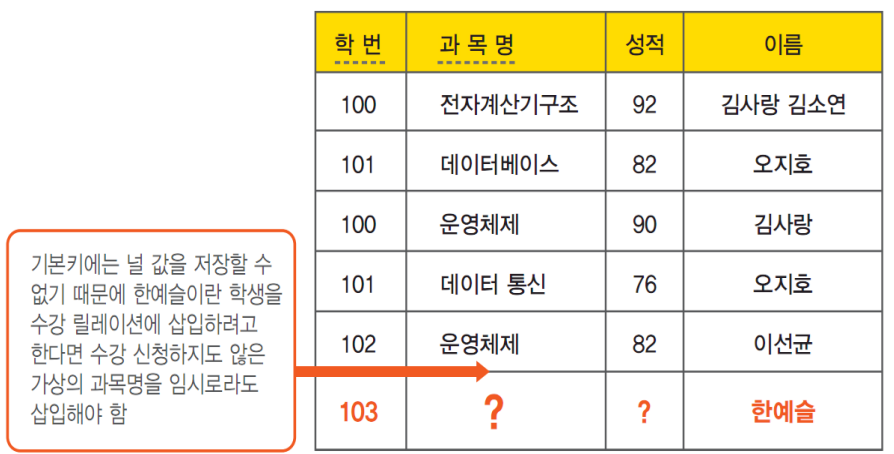
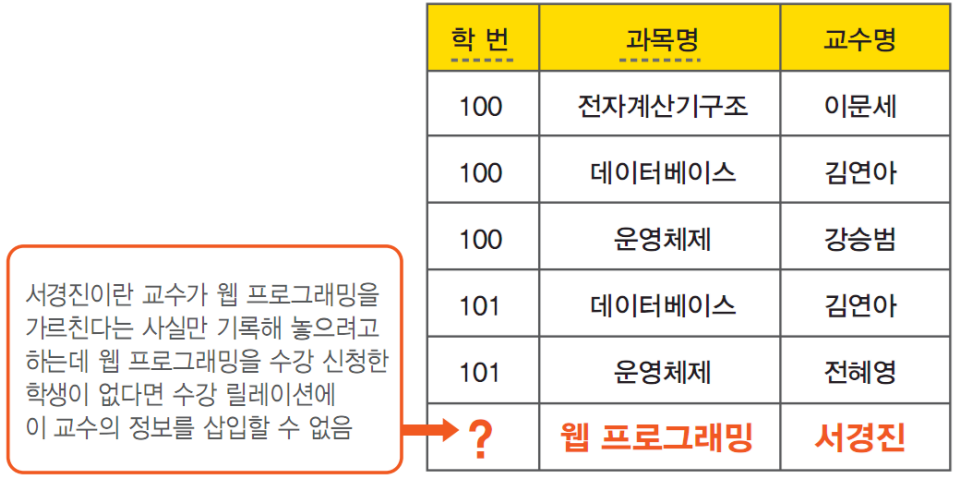
삽입 이상이란 불필요한 정보를 함께 저장하지 않는것으로 어떤 정보를 저장하는 것이 불가능하기에 원하지 않는 정보를 강제로 삽입해야하는 것이다.
삭제 이상
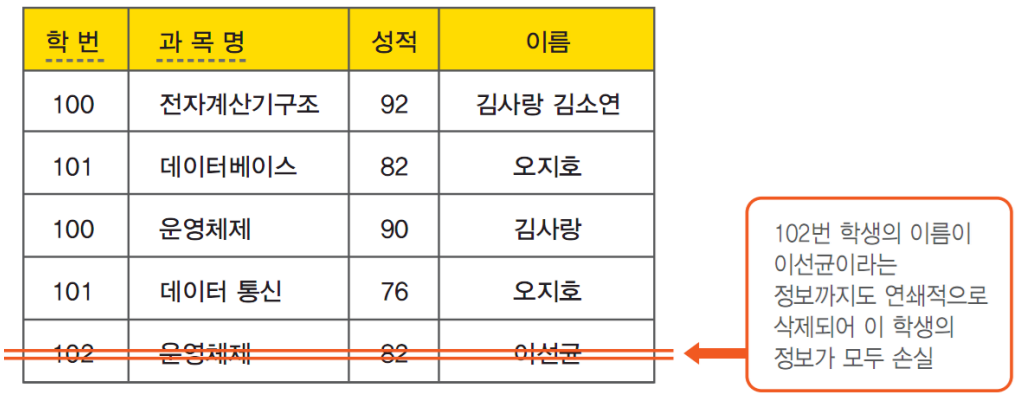
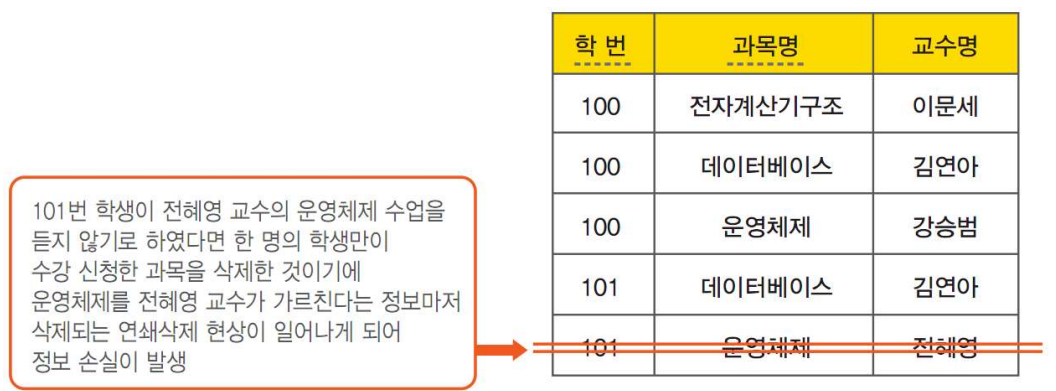
삭제 이상이란 유용한 정보를 함께 삭제하지 않고는 어떤 정보를 삭제하는 것이 불가능한 것이다.
정규화란 갱신 이상이 생기지 않도록 불필요한 데이터가 중복되어 저장되지 않게 방지하여 바람직한 릴레이션 스키마로 만들어 가는 과정이다. 정규화의 목적은 반복적인 자료를 제거하여 다음과 같은 상태를 만들기 위한 것이다.
- 어떤 관계라도 데이터베이스 내에서 표현이 가능하도록 만드는 것
- 관계에서 바람직하지 않은 삽입, 삭제, 갱신 이상이 발생하지 않도록 함
- 새로운 형태의 데이터가 삽입될 때 관계를 재구성할 필요성을 줄일 수 있음
- 보다 간간하게 관계 연산에 기초하여 검색을 보다 효율적으로 할 수 있음
함수 종속
함수적 종속의 정의는 어떤 릴레이션에서 속성들의 부분 집합을 X, Y라 할 때, 임의 튜플에서 X의 값이 Y의 값을 함수적으로 결정한다면, Y가 X에 함수적으로 종속되었다고 하고 기호로는 다음과 같이 표기한다. X$\rightarrow$Y, “X determines Y, Y is functionally dependent on X”로서 X는 결정자를 의미한다.
결정자(determinant)란 주어진 릴레이션에서 다른 속성(또는 속성들의 집합)을 고유하게 결정하는 하나 이상의 속성이다. 다음과 같은 과정으로 함수적 종속을 이용하여 key를 결정할 수 있다.
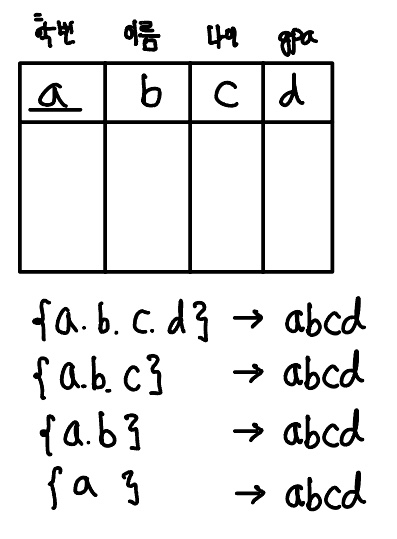
다음을 보자.
위는 학번이 이름을 결정하고(학번 $\rightarrow$ 이름), {학번, 과목명}을 key로 하여 학번, 과목명, 성적, 이름을 결정한다({학번, 과목명} $\rightarrow$ 학번, 과목명, 성적, 이름).
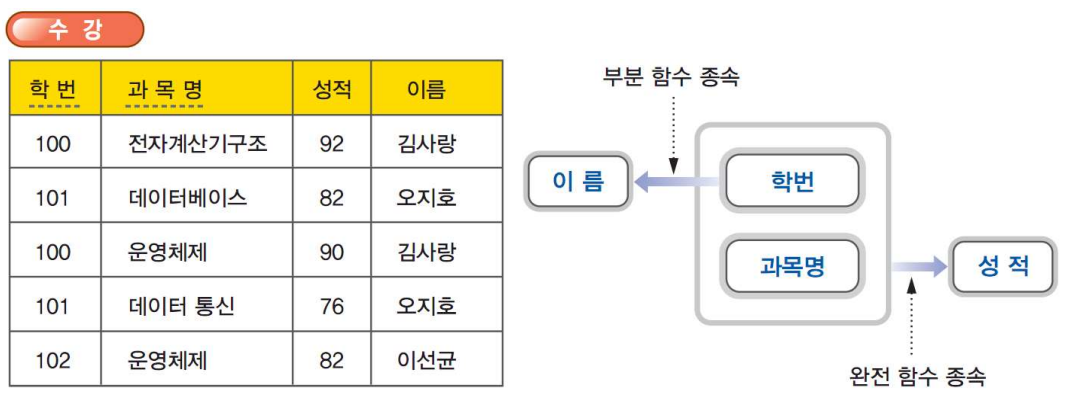
함수적 종속의 성질은 완전 함수 종속(FFD, Full Functional Dependency)와 부분 함수 종속(PFD, Partial Functional Dependency)가 있다. 다음은 릴레이션 내의 속성들의 종속 관계를 보다 쉽게 이해하기 위해서 이를 도식적으로 표현한 함수 종속 다이어그램의 예를 보여준다.
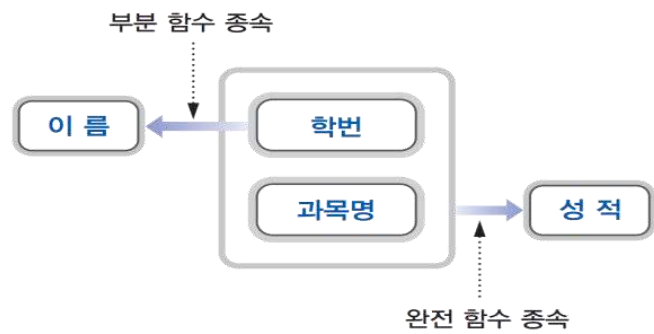
위에서 “학번 $\rightarrow$ 이름”은 부분 함수 종속(partial key)을 보여주고 “{학번, 과목명} $\rightarrow$ 성적”은 완전 함수 종속(prime key)을 나타낸다.
정규화 과정
정규화란 주어진 릴레이션 스키마를 함수적으로 종속성 등의 종속 이론을 이용하여 잘못된 릴레이션 스키마를 보다 더 작은 속성의 세트로 나누어서 갱신 이상이 발생하지 않는 바람직한 릴레이션 스키마로 만들어 가는 과정이다. 정규형(Normal Form)은 테이블의 정규화된 정도를 나타낸다.
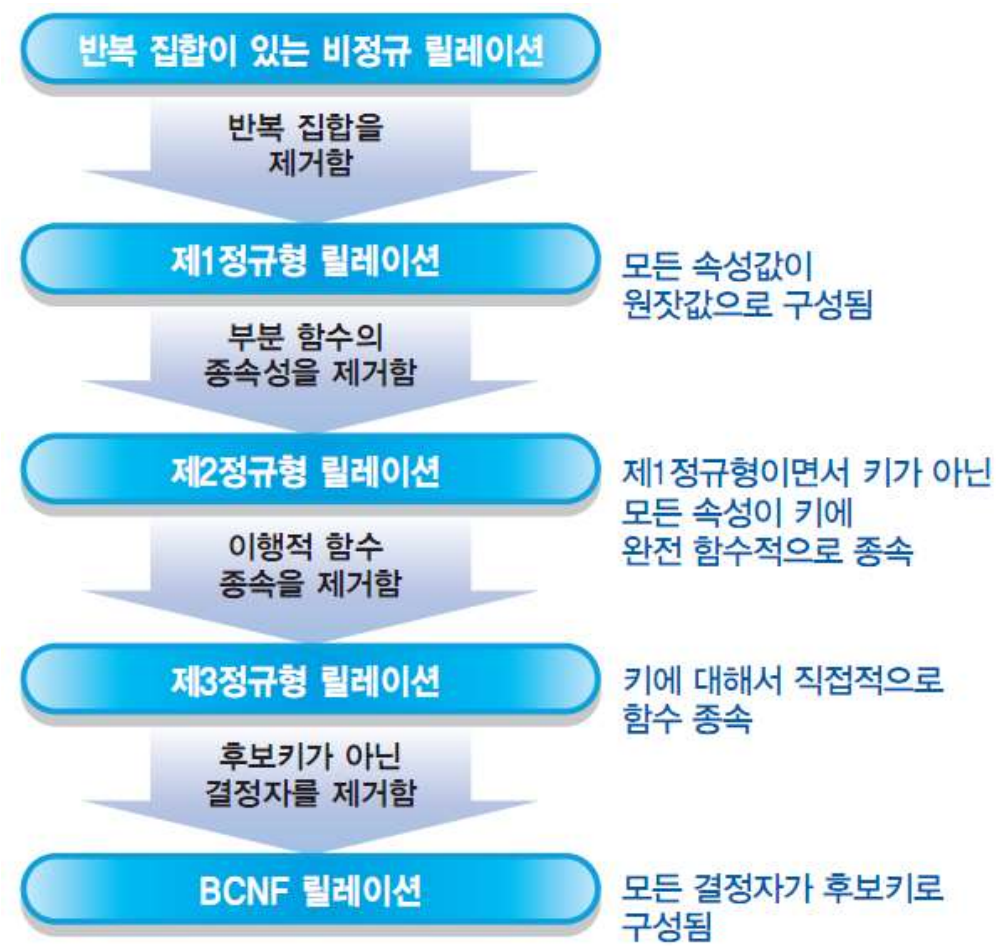
정규형들 간의 관계는 다음과 같이 표현한다.
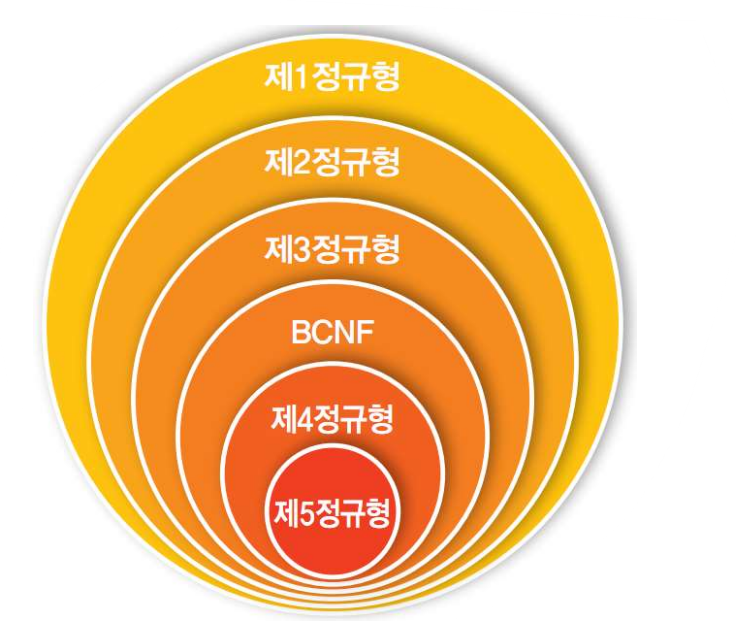
제1정규형(1NF)
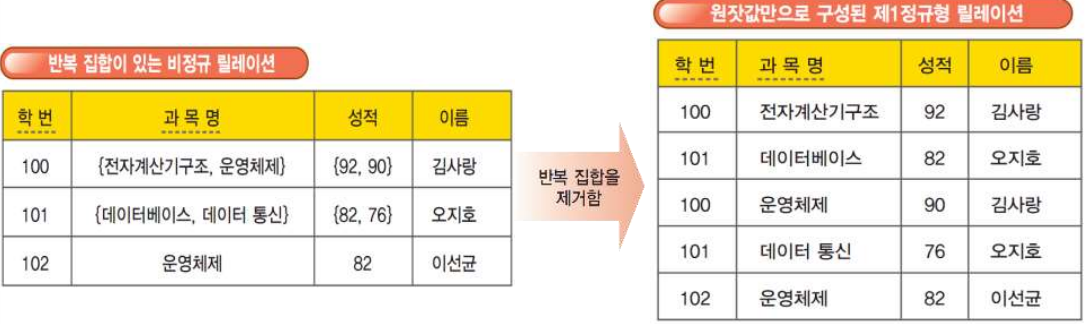
제1정규형을 만족하는 릴레이션은 어떤 릴레이션 R에 속한 모든 도메인이 원잣값(atomic value)이고 릴레이션의 속성값이 반복 집단이 없는 즉, 더 이상 분해될 수 없는 원잣값으로만 구성된 것이다. 반복 집합은 한 개의 기본키 값에 대해서 두 개 이상의 값을 가질 수 있는 속성으로 다음은 반복 집합이 있는 비정규 릴레이션을 보여준다.
제1정규화 과정은 “반복 집합이 있는 비정규 릴레이션”을 반복 집합을 제거함으로써 “모든 속성값이 원잣값으로 구성된 제1정규형 릴레이션”으로 만드는 것이다. 다음은 제1정규화 과정의 예를 보여준다.
제2정규형(2NF)
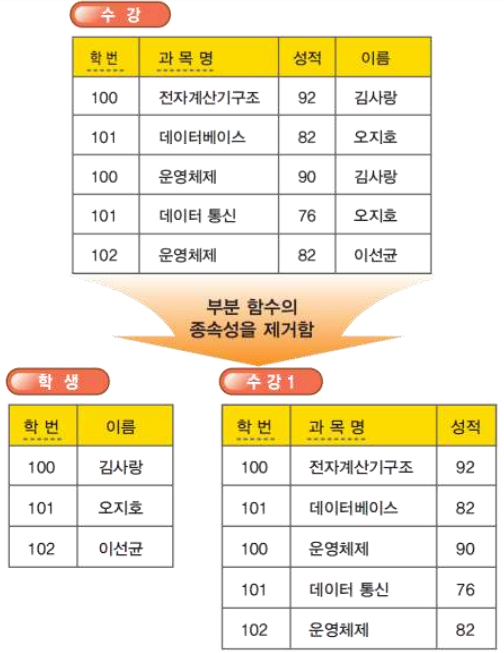
제2정규형은 어떤 릴레이션 R이 제1정규형이고, 키에 속하지 않는 속성 모두가 키에 완전 함수 종속이다. 제2정규화 과정은 “모든 속성값이 원잣값으로 구성된 제1정규형 릴레이션”을 부분 함수의 종속성을 제거함으로써 “모든 속성이 키에 완전 함수 종속인 제2정규형 릴레이션”으로 만드는 것이다. 다음은 제1정규형을 제2정규형으로 바꾸는 과정을 보여준다.
위 2개의 functional dependency(부분 함수 종속, 완전 함수 종속)가 있고 테이블을 2개로 쪼개서 완전 함수 종속으로 바꿀수 있다.
위 과정은 제1정규형을 무손실로 제2정규형으로 테이블을 나누어 두 테이블 모두 완전 함수 종속성을 만족한다. 위 과정을 함수 종속 다이어그램으로 나타내면 다음과 같다.
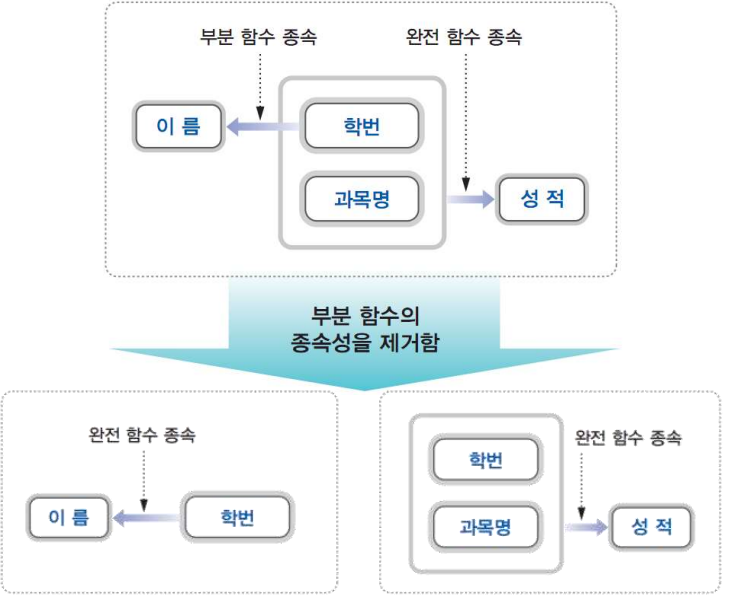
무손실 분해(nonloss decomposition)는 자연 조인하였을 때 아무런 정보 손실 없이 다시 원래의 릴레이션으로 복귀된다면 2NF로 두개의 릴레이션으로 분해하는 것이다.
제3정규형(3NF)
제3정규형은 어떤 릴레이션 R이 2NF이고, 모든 속성들이 기본키에 이행적 함수 종속(transitive FD)을 제외하는 것이다. 이행적 함수 종속성은 3개의 속성에 존재하는 함수의 종속성을 의미한다.
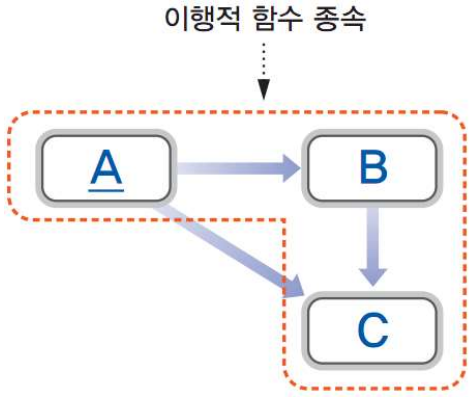
다음은 이행적 함수 종속의 한 예이다.
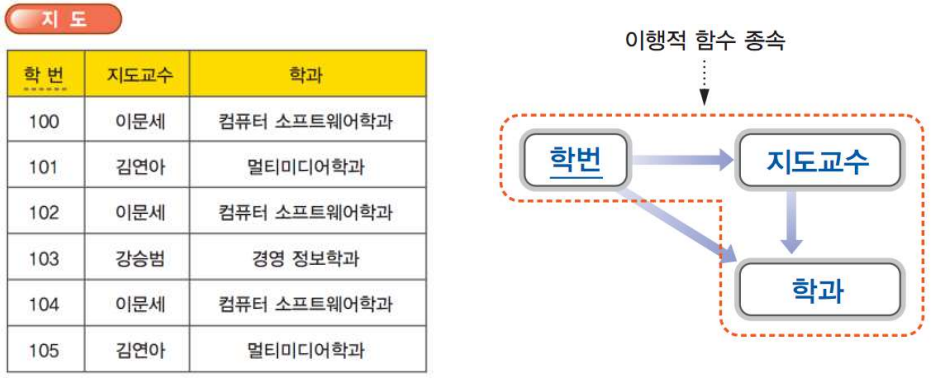
위에서 “학번$\rightarrow$지도교수” $\cap$ “지도교수$\rightarrow$학과” $\Rightarrow$ “학번$\rightarrow$학과”로 표현할 수 있다. 이행적 함수 종속으로 인한 갱신 이상이 발생할 수 있는데 다음은 이때 발생하는 수정 이상, 삽입 이상, 삭제 이상을 보여준다.
수정 이상
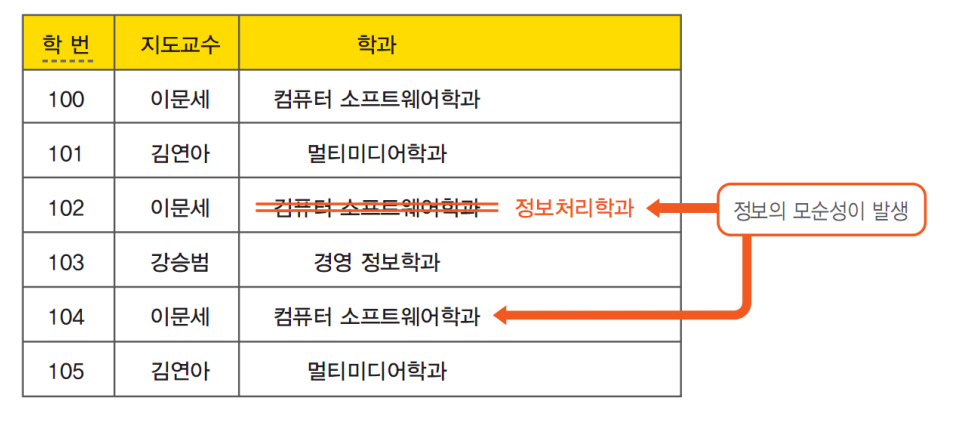
삽입 이상
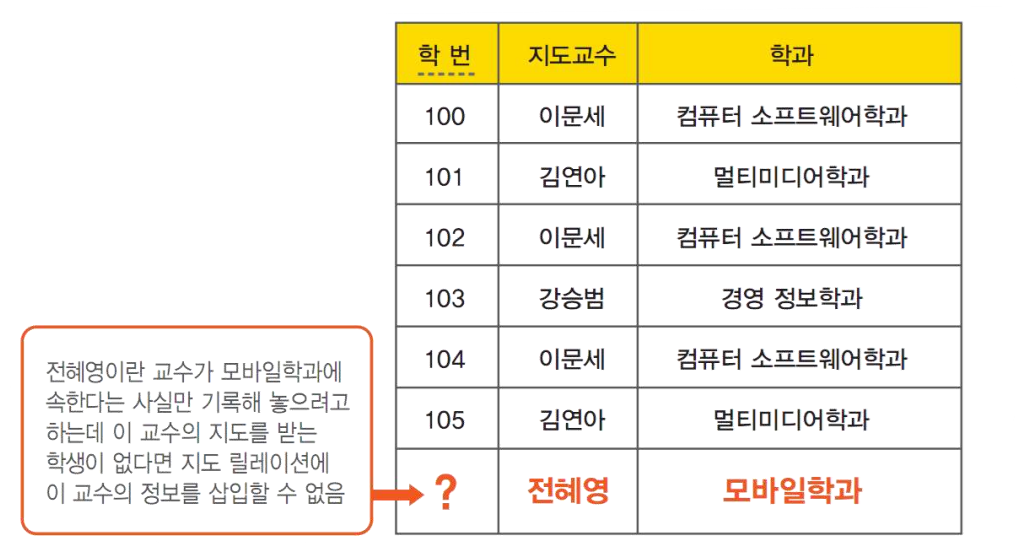
삭제 이상
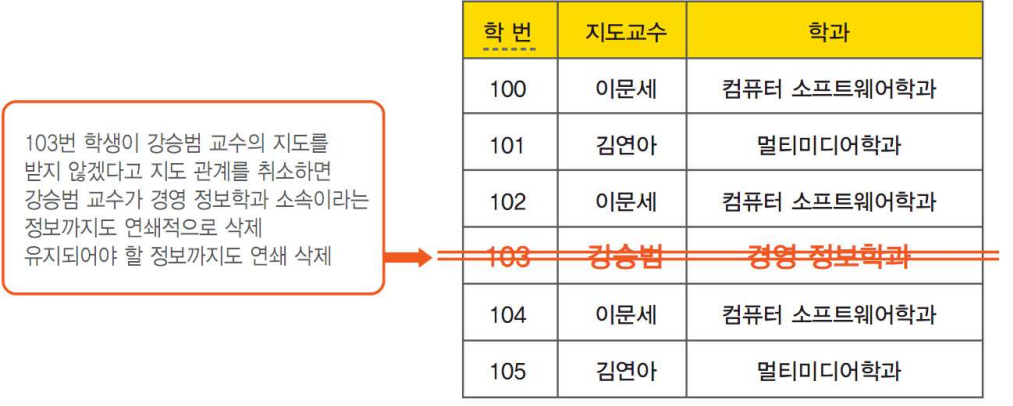
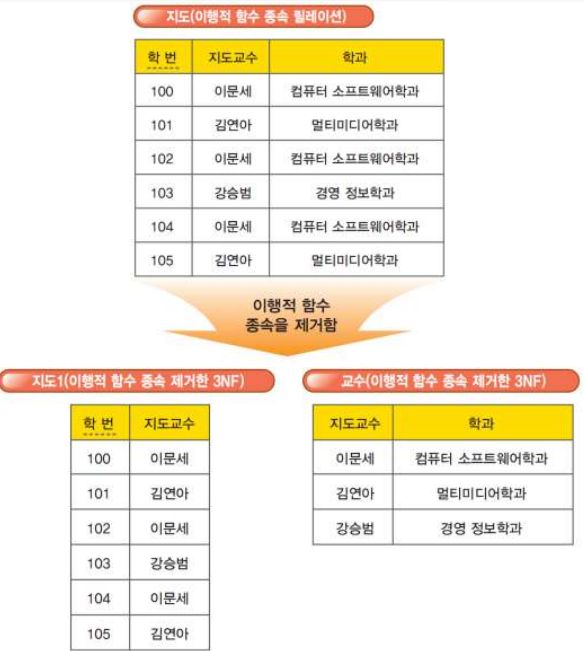
제3정규화 과정은 “모든 속성값이 원잣값으로 종속된 제2정규형 릴레이션”을 이행적 함수 종속을 제거함으로써 “키에 대해서 직접적으로 함수 종속하는 제3정규형 릴레이션”으로 만드는 것이다. 다음은 제3정규화과정의 한 예를 보여준다.
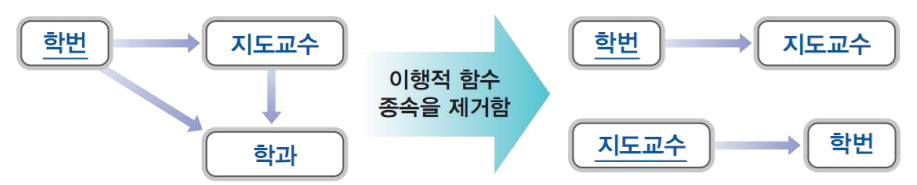
다음은 위 과정을 다이어그램으로 표현한 것이다.
보이스/코드 정규형(BCNF)
보이스/코드 정규형은 복잡한 식별자 관계에 의해 발생하는 문제를 해결하기 위해서 제3정규형을 보완한 것으로 릴레이션 R이 제3정규형을 만족하고, 모든 결정자가 후보키이다. 다음 예를 보자.
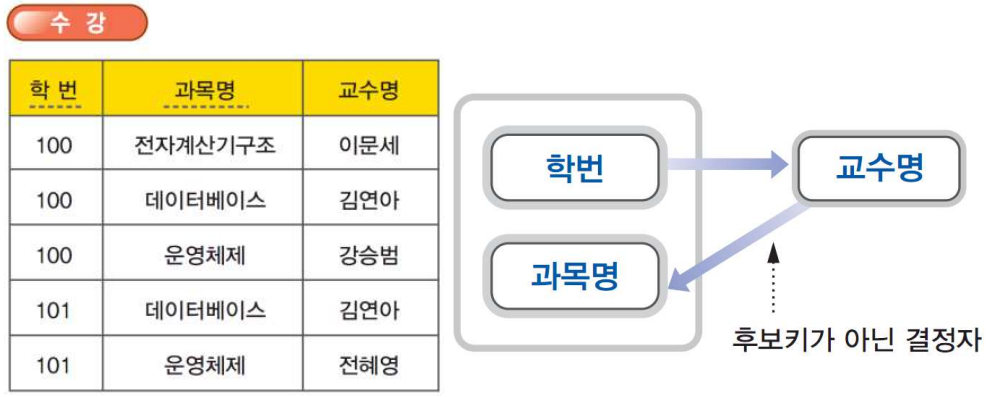
다음은 결정자가 후보키가 아닌 릴레이션에서의 갱신 이상을 보여준다.
수정 이상
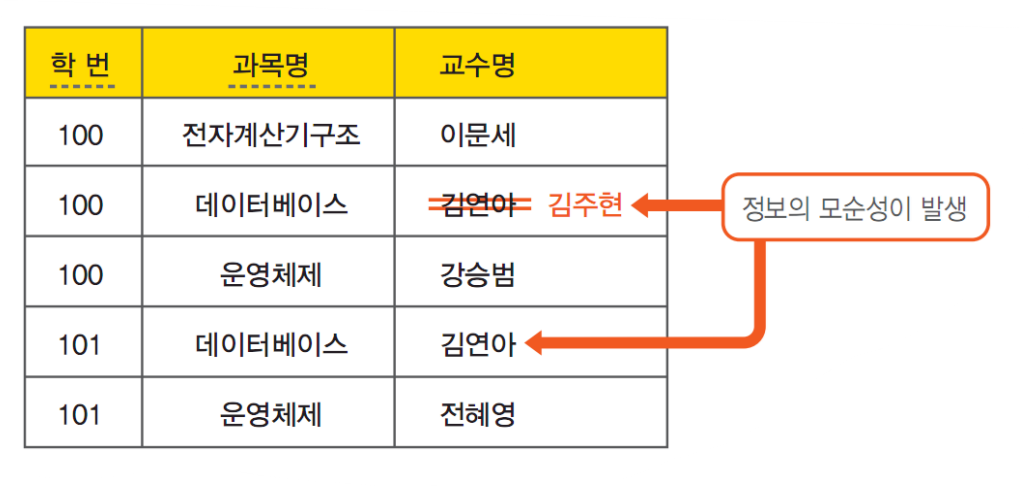
삽입 이상
삭제 이상
보이스/코드 정규화 과정은 “키에 대해서 직접적으로 함수 종속하는 제3정규형 릴레이션”을 후보키가 아닌 결정자를 제거함으로써 “모든 결정자가 후보키인 BCNF 릴레이션”으로 만드는 것이다. 다음은 보이스/코드 정규화 과정의 예를 보여준다.
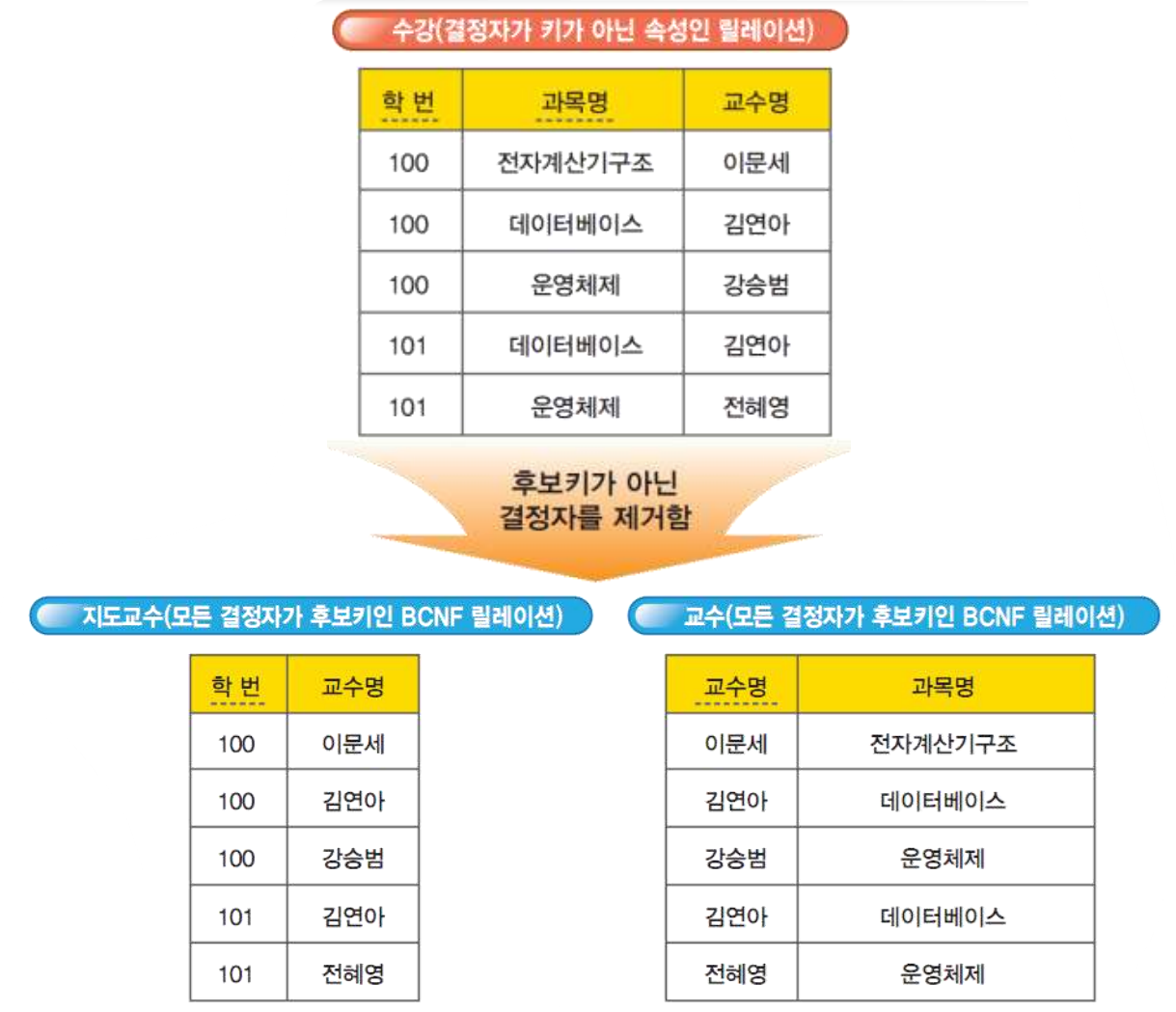
다음은 위 과정을 다이어그램으로 표현한 것이다.

다음은 지금까지 본 정규형의 특징과 정규화 과정을 보여준다.
댓글남기기