2장 데이터베이스 설계의 개요
Updated:
개체-관계(entity-relationship:ER) 데이터 모델은 실세계 조직체에 관한 데이터를 객체들과 그들간의 관계에 의하여 묘사하는 것으로, 초기 단계의 데이터베이스 설게를 개발하기 위해 널리 사용되고 있다. ER 모델은 사용자들이 데이터베이스로부터 필요로 하는 것에 대한 간단한 기술에서부터 DBMS내에 구현될 수 있는 더 상세하고 정확한 기술까지 표현할 수 있는 광범위한 데이터를 충실히 설계하는지에 대하여 논의한다.
데이터베이스 설계와 ER 다이어그램
데이터베이스 설계는 더 큰 규모의 소프트웨어 시스템 설계의 단지 일부분이라는 것을 인식하면서 데이터베이스 설계에 대한 논의를 시작한다. 데이터베이스 설계과정은 여섯 단계로 나눌 수 있는데 다음 세 단계에 가장 많이 관련된다.
요구 분석(requirement analysis)
데이터베이스 응용을 설계할 떄 가장 첫 단계는 데이터베이스에 무슨 정보를 저장할 것인가, 그 위에 어떤 응용을 구축할 것인가, 어떤 연산들이 가장 자주 수행되며 성능 요건은 무엇인가를 파악하는 일이다. 다시 말하면, 사용자들이 데이터베이스로부터 필요로 하는 바를 찾아내야 한다는 것이다.
개념적 데이터베이스 설계(conceptual database design)
요구분석 단계에서 모은 정보들은 데이터베이스에 저장될 데이터와 이 데이터가 준수해야하는 제약조건들을 고수준으로 기술하기 위해 사용된다. 이 단계는 주로 ER 모델을 이용하여 수행된다.
논리적 데이터베이스 설계(logical database design)
데이터베이스 설계를 구현하기 위해 DBMS를 선정하고, 개념적 데이터베이스 설계를 선정한 DBMS의 데이터 모델에 따른 데이터베이스 스키마로 변환해야한다.
ER 설계 이후의 단계들
스키마 정제(schema refinement)
관계 데이터베이스 스키마에 있는 릴레이션들을 분석하여 잠재적인 문제점들을 파악하고 정제하는 것이다. 요구분석 단계와 개념적 데이터베이스 설계 단계는 본질적으로 주관적이지만, 스키마 정제는 상당히 훌륭하고 강력한 이론에 의해 수행될 수 있다.
물리적 데이터베이스 설계(physical database design)
데이터베이스가 지원해야 할 일반적인 예상 작업량을 고려하여 데이터베이스 설계를 원하는 성늘기준에 맞도록 더 정제한다. 이 단계는 단순히 몇 개의 테이블에 인덱스를 구축하고 몇 개의 테이블을 클러스터링하는 것을 필요로 할 수 있다. 혹은 이전의 설계 단계에서 구축된 데이터베이스 스키마의 부분들에 대한 상당한 재설계를 수반할 수 있다.
응용 및 보안 설계
어떤 응용 업무를 반영하는 모든 프로세스에서 각 개체의 역할을 그 업무를 위한 전체 작업 흐름의 일부로써 기술해야 한다. 각 역할별로, 접근될 수 있어야만 하는 데이터베이스 영역과 접근되어서는 안 되는 영역을 파악해야 한다. 그 다음으로 이러한 접근 규칙들이 집행되는 것을 보장하기 위한 조치들을 취해야 한다.
개체, 애트리뷰트, 개체집합
개체(entity)는 실세계에서 다른 객체들로부터 구분될 수 있는 객체이다. 하나의 개체는 애트리뷰트들(attributes)의 집합을 사용하여 기술된다. 개체집합(entity set)는 같은 종류의 개체들을 하나의 집합으로 모은 것이다. 개체집합과 관련한 각 애트리뷰트에 대해서, 가능한 값들의 도메인(domain)을 지정해야한다. 예를 들어, Employees의 애트리뷰트 name에 대한 도메인은 20개의 문자들로 이루어지는 문자열들의 집합이 될 수 있다. 그리고 각 개체집합에 대해서 키를 선택한다. 키(key)는 주어진 집합에 속하는 한 개체를 유일하게 식별하는 값을 갖는 최소개의 애트리뷰트들로 이루어진 집합니다. 후보(candidate)키는 하나보다 더 많을 수 있는데, 그럴 경우에는 그들 중의 하나를 기본(primary)키로 지정한다. 애트리뷰트들의 집합은 키를 포함한다.
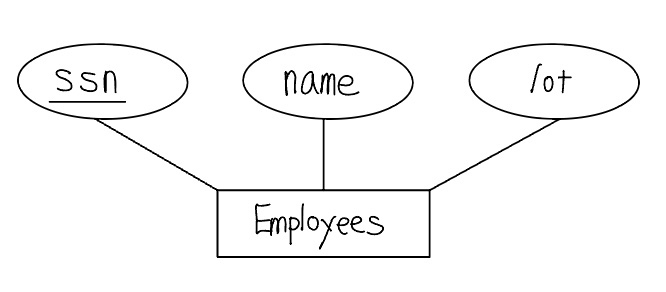
다음 그림은 snn, name, lot 을 애트리뷰트로 가진 Employees 개체집합이다. 개체집합은 사각형으로 표현되고, 애트리뷰트는 타원형으로 표현된다. 기본키에 속하는 각 애트리뷰트에는 밑줄을 긋는다.
관계와 관계집합
관계(relationship)는 둘 이상의 개체들 사이의 관련성이다. 예를 들어, Attishoo라는 직원이 제약 부서에 근무하는 관계를 가질 수 있다. 개체들처럼, 같은 종류의 관계들을 하나의 관계집합(relationship set)으로 모을 수 있다.
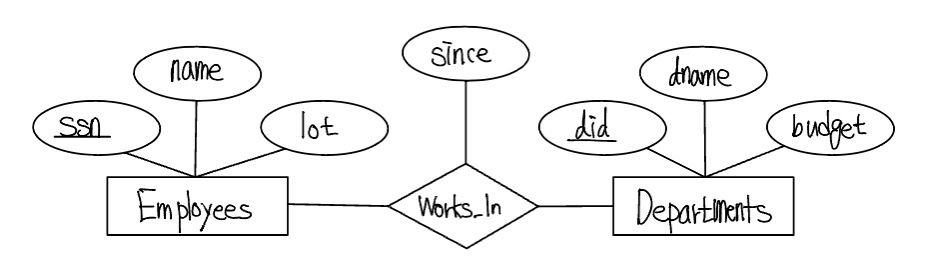
다음 그림은 Works_In 관계집합을 나타내는데, 각 관계는 한 직원이 근무하는 부서을 나타낸다. 여러 관계집합이 동일한 개체집합을 포함할 수 있다.
한 관계집합에 참여하는 개체집합들이 서로 다를 필요한 없다. 가끔 관계는 동일한 개체집합에 속하는 두 개체를 포함할 수 있다. 예를 들어, 다음 그림과 같은 Report_To 관계집합을 살펴보자.
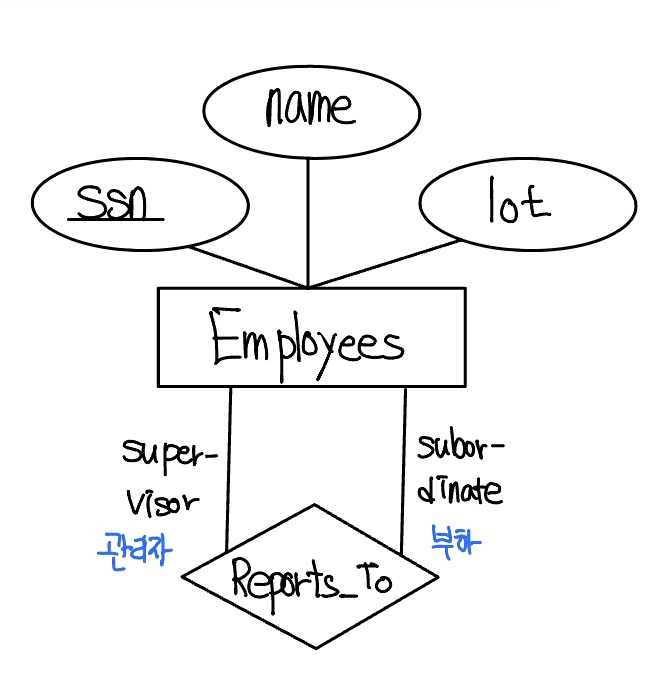
한 직원이 다른 직원에게 보고하므로, Reports_To에 있는 관계는 ( emp1 , emp2 )의 형식이 되는데, 이때 emp1과 emp2는 모두 Employees에 속한 개체들이다. 그렇지만, 이들은 서로 다른 역할(role)을 한다. emp1은 관리 직원인 emp2에게 보고한다. 이 사실이 역할 지시자(role indicator) supervisor, subordinate 로 반영되어있다.
ER 모델의 특별 기능
데이터의 세부적인 특징들을 표현할 수 있는 ER 모델의 구성자들에 대해서 살펴보자.
키 제약조건
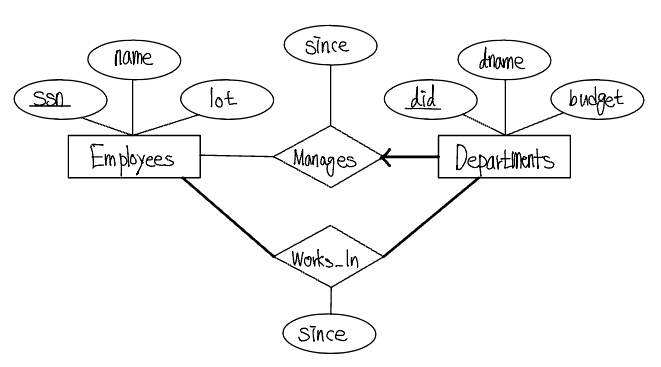
이전 Works_In 관계에서 한 직원은 여러 부서에서 근무할 수 있으며 한 부서에는 여러 직원이 근무할 수 있다. 이제 Employees 개체집합과 Departments 개체집합 사이의 또다른 관계집합인 Manages를 생각해보자. 이 관계집합에서 각 부서에는 많아야 한 명의 관리자가 있지만 한 직원은 여러 부서를 관리할 수 있다. 각 부서에는 많아야 한 명의 관리자가 있다는 제약은 키 제약조건(key constraints)의 예가 되며, 이 제약조건은 Manages가 허용할 수 있는 인스턴스에서 각 Departments 개체는 많아야 하나의 Manages 관계에 나타난다는 것을 의미한다. 이 제약이 다음 그림의 ER 다이어그램에서 Departments로부터 Manages로 가는 화살표를 사용하여 표시한다.
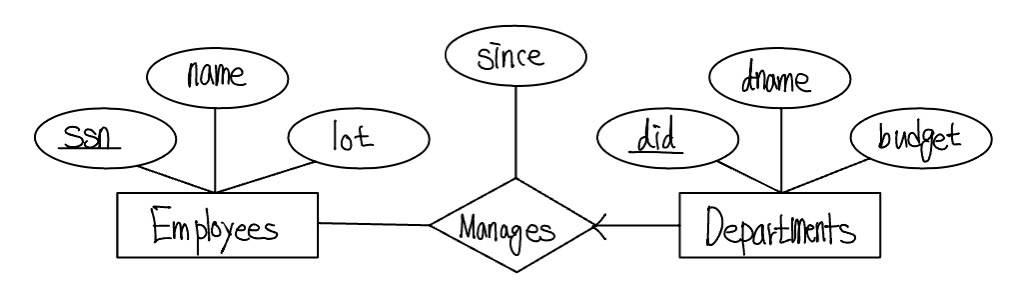
Manages와 같은 관계집합을 일-대-다(one-to-many)라고한다. 이와 반대로, Works_In 관계집합에서는 한 명의 직원이 여러 부서에 근무하는 것이 허용되고 한 부서에는 여러 직원들이 근무하는 것이 허용된다. 이러한 관계집합을 다-대-다(many-to-many)라고 한다. 만일 한 직원이 많아야 하나의 부서만 관리할 수 있다는 제약을 Manages 관계집합에 추가하다면, 이 제약은 위 그림에서 Employees로 부터 Manages로 가는 화살표를 추가함으로써 표시될 수 있고, 이러한 관계집합을 일-대-일(one-to-one)이라고 한다.
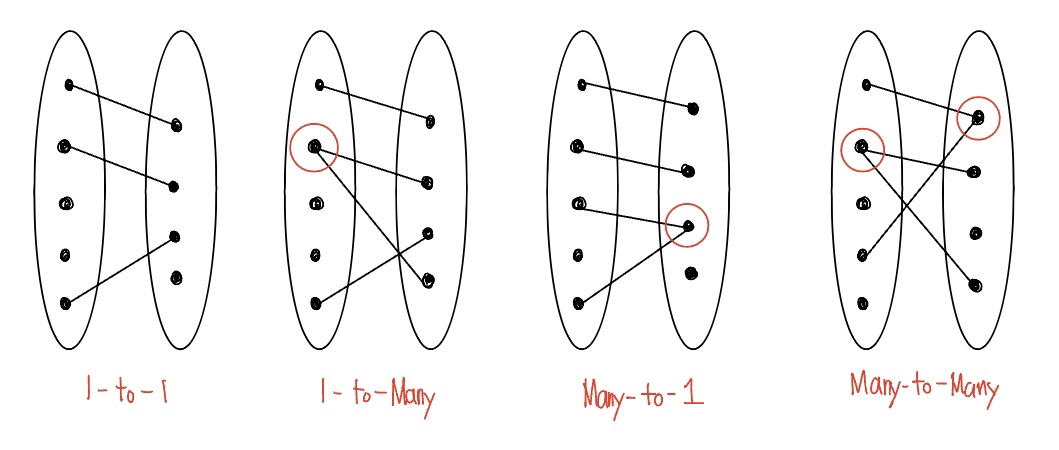
참여 제약조건
Manages에 대한 키 제약조건은 한 부서는 최대 한 명의 관리자를 두고 있다는 것을 말한다. 그렇다면 모든 부서는 관리자를 두는 것이 필수적이라고 가정하면 이 요건이 참여 제약조건(participation constraints)의 한 예이다. 관계집합 Manages에 개체집합 Departments의 참여는 전체적(완전)(totla)이라고 한다. 전체적이 아닌 참여도를 부분적(partial)이라고 한다. 예를 들면, Manages에서 각 직원이 모두 하나의 부서를 관리하는 것은 아니므로 개체집합 Employees의 참여는 부분적이다.
Works_In 관계집합에서 각 직원은 적어도 한 부서에서 근무하고 각 부서에는 적어도 한 명의 직원이 근무하고 있다고 생각하는 것은 당연하다. 이것은 Works_In에 있는 Employees와 Departments의 참여가 모두 전체적이라는 것을 의미한다. 다음 그림은 Manages 및 Works_In 관계집합과 제약조건들을 나타낸다. 어떤 관계집합에서 한 개체집합의 참여가 전체적이면, 그 둘은 굵은 선으로 연결된다. 이와는 별도로 화살표가 있으면 키 제약을 나타낸다.
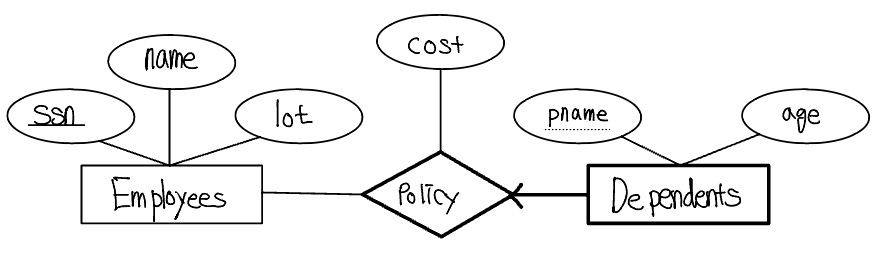
약개체
직원들이 그들의 부양자들을 위해 보험증권을 구매할 수 있다고 가정하자. 각 보험증권에 이해 누가 보호되는가를 포함하여 보험증권에 관한 정보를 기록하고자 한다. 만약 한 직원이 회사를 그만두면, 그 직원이 소유한 어떠한 증권도 종료되고 모든 관련된 증권정보와 피부양자 정보를 데이터베이스로부터 삭제하는 것이 필요하다. 특정 직원의 피부양자들은 서로 다른 이름을 가진다고 생각할 수 있으므로, 이런 경우에는 각 피부양자를 식별하기 위해 이름을 선택할 수 있다. 따라서 Dependents 개체집합의 애트리뷰트들은 pname 과 age 가 될 수 있다. 애트리뷰트 pname은 피부양자들을 유일하게 식별하지 않는다. Employees의 키는 snn 이므로 Smethrust라는 이름을 가진 두 직원은 각기 Joe라는 아들을 둘 수도 있다.
Dependents는 약개체집합(weak entity set)의 예이다. 약개체는 그것의 애트리뷰트 일부와 식별 소유자(identifying owner)에 해당하는 개체의 기본키를 결합하여야만 유일하게 식별된다.
약개체집합은 다음의 제한사항들이 만족되어야 한다.
- 소유자 개체집합과 약개체집합은 일-대-다 관계집합으로 참여해야 한다. 하나의 소유자 개체는 여러 약개체와 연관되지만, 각 약개체는 오직 하나의 소유자를 갖는다. 이러한 관계집합을 해당 약개체집합의 식별 관계집합(identifying relationship set)이라고 한다.
- 약개체집합은 식별 관계집합에 전체적으로 참여해야한다.
예를 들어, 하나의 Dependents 개체는 소유하는 Employees 개체의 키와 Dependents 개체의 pname을 취하는 경우에만 유일하게 식별될 수 있다. 주어진 소유자 개체에 대하여 하나의 약개체를 유일하게 식별하는 약개체집합의 애트리뷰트들의 부분집합은 그 약개체집합의 부분키(partial key)라고 부른다. 이 예에서, pname은 Dependents의 부분키이다.
다음 그림은 약개체집합 Dependents와 Employees의 관계이다. Policy에서 Dependents의 전체참여는 그들을 굵고 진한 선으로 연결함으로써 표시된다. Dependents로 부터 Policy로 가는 화살표는 각 Dependents 개체가 Policy 관계에 한번 나타나는 것을 표시한다. Dependents가 약개체집합이며 Policy가 그것의 식별 관계집합이라는 사실을 강조하기 위해, 둘 다 굵고 진한 선으로 그린다. pname이 Dependents의 부분키임을 나타내기 위해, 점선으로 pname에 밑줄을 긋는다.
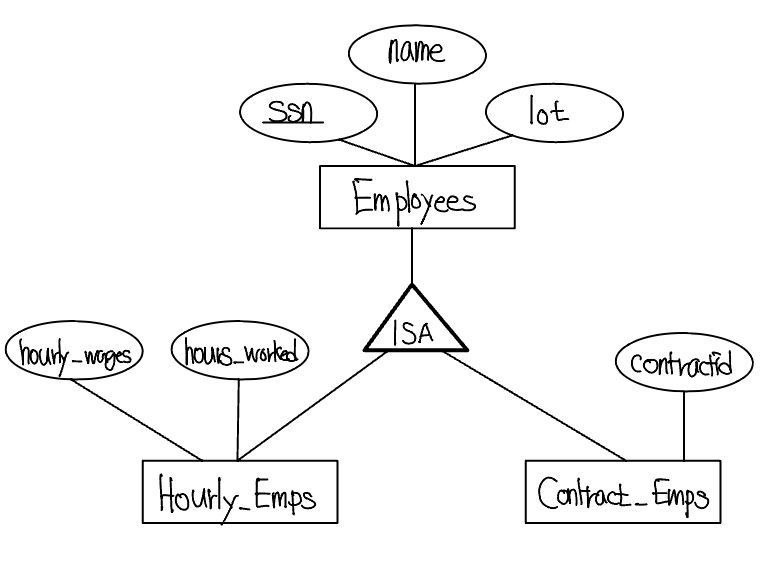
클래스 계층
직원들이 봉급을 받는 방식을 구별하기 위해 Hourly_Emps 개체집합과 Contract_Emps 개체집합을 예로 들자. Hourly_Emps에 대해서는 애트리뷰트 hours _ worked 와 hourly _ wage
가 정의될 수 있고 Contract_Emps에 대해서는 contractid 가 정의될 수 있다. 각 개체집합에 속하는 모든 개체는 Employees 개체들이므로 Hourly_Emps에 정의된 애트리뷰트들은 Employees의 애트리뷰트들과 Hourly_Emps의 애트리뷰트들을 합한것이다. 이때 개체집합 Employees의 애트리뷰트들은 개체집합 Hourly_Emps에 의해서 상속된다(inherited)고 하며 Hourly_Emps ISA Employee라고 한다. 다음 그림은 이러한 클래스 계층의 예를 보여준다.
개체집합 Employees는 또다른 기준에 따라 분류될 수 있다. 예를 들어, 직원들 중 일부를 Senior_Emps로 식별할 수 있다. 이러한 변경을 반영하기 위해 Employees의 자식으로 두 번째 ISA노드를 추가하고 Senior_Emps를 이 노드의 자식 노드로 만들 수 있다. 이 개체집합들은 각각 더 분류되어, 다단계 ISA 계층을 생성할 수 있다.
ISA 계층과 관련하여 중첩 제약조건과 포괄 제약조건을 명시할 수 있다. 중첩 제약조건(overlap constraints)은 두 서브클래스가 같은 개체를 포함하는 것이 허락되는가를 결정한다. 예들들어, Attishoo라는 사람이 Hourly_Emps 개체이면서 동시에 Contract_Emps 개체가 될 수는 없다. 그런데 그 사람이 Constract_Emps 개체이면서 동시에 Senior_Emps 개체일 수는 있다. 이것을 ‘Contract_Emps OVERLAPS Senior_Emps’라고 표시한다. 이러한 언급이 없으면, 개체집합들은 중첩하지 않는다고 간주한다. 포괄 제약조건(covering constraints)은 모든 서브클래스에 속해 있는 개체들이 집합적으로 슈퍼클래스의 모든 개체들을 포함하는가를 결정한다. 예들 들어, 모든 Employees 개체들은 그것의 서브클래스들 중 하나에 반드시 속해야하지는 않다. 직관적으로 모든 Moter_vehicle 개체는 Motorboats 개체이거나 Cars개체이어야 한다. 일반화된 계층의 특징은 슈퍼클래스의 모든 인스턴스는 한 서브클래스의 인스턴스라는 것이다. 이것을 ‘Moterboats AND Cars COVER Motor_vehicle’라고 표시한다. 이러한 언급이 없으면, 모터보트도 아니고 자동차도 아닌 차량이 있다고 간주한다.
특성화나 일반화에 의하여 서브클래스들을 찾아내는 데는 두 가지의 기본적인 이유가 있다.
- 어떤 서브클래스의 개체들에 대해서만 의미가 있는 기술적인 애트리뷰트들을 추가할 필요가 있다. 예들 들어, hourly _ wages 는 봉급이 개별적인 계약에 의해 결정되는 Contract_Emps 개체에는 해당되지 않는 것이다.
- 어떤 관계에 참여하는 개체들의 집합을 식별할 필요가 있다. 예를 들어, 선임 직원만 관리자가 될 수 있다는 것을 보장하기 위해, 참여하는 개체집합들이 Senior_Emps와 Departments가 되도록 Manages 관계를 정의할 수 있다.
집단화
개체들의 모임과 관계들의 모임간에 관계를 설정해 주어야 할 때도 있다. 예를 들어, Projects라는 개체집합이 있고 각 Projects 개체는 하나 이상의 부서로부터 자금지원을 받는다고 하자. Sponsors 관계집합은 이 정보를 표현한다. 어떤 프로젝트의 자금을 지원하는 부서에서는 그 프로젝트를 감독할 직원을 지정할 수 있다. 이때 Monitor는 Sponsors 관계와 Employees 개체를 연관 짓는 관계집합이어야 한다. 이와 같은 관계집합을 정의하기 위해, 집단화(aggregation)라는 ER 모델의 새로운 특징이 있다. 집단화는 어떤 관계집합이 다른 관계집합에 참여하는 것을 나타낼 수 있게 한다. 이는 다음과 같은데, Sponsors와 주위를 둘러싼 점선 사각형이 집단화를 나타낸다. 이것은 Monitors 관계집합을 정의하기 위한 목적으로 실질적으로 Sponsors를 하나의 개체집합을 간주할 수 있게 한다.
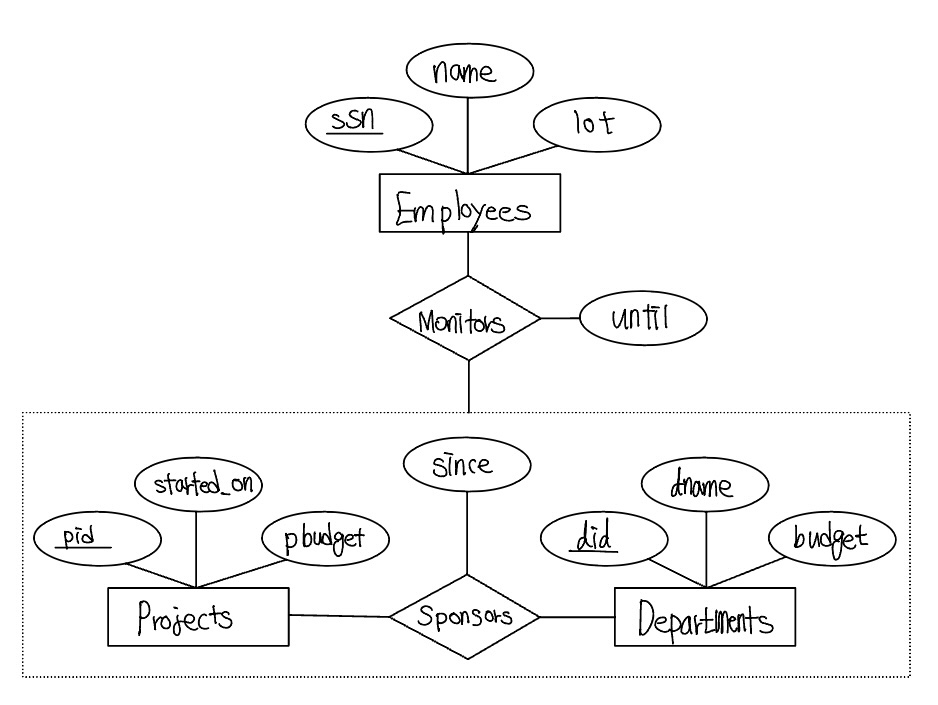
ER 모델을 이용한 개념적 설계
ER 다이어그램을 개발하기 위해 어떤 구성자를 선택할 것인가를 주의 깊게 검토할 필요가 있다.
개체와 애트리뷰트 간의 선택
하나의 개체집합의 애트리뷰트들을 식별하는 과정에서, 하나의 특징이 애트리뷰트로 모델링되어야 할지 혹은 새로운 개체집합으로 모델링되어야 할지 불분명할 때가 있다. 에를 들어, Employees 개체집합에 주소 정보를 추가한다고 하자. 한 가지 옵션은 애트리뷰트 address 를 사용하는 것이다. 이 옵션은 직원마다 하나의 주소만 기록하는 것이 필요한 경우에 적절하며, 주소를 일종의 문자열로 생각하면 충분하다. 또다른 방법은 Address라는 개체집합을 생성하고 직원들과 주소들간의 연관성을 관계를 이용하여 기록하는 것이다. 이처럼 더 복잡한 대안은 다음의 두 경우에 필요하다.
- 한 직원에 대해 여러 주소를 기록해야 한다.
- ER 다이어그램에서 주소의 구조를 표현하는 것이 필요하다. 예를 들어, 주소를 시, 도, 나라, 우편번호로 구분한다.
다음 그림의 관계집합 Works_In4를 살펴보자.
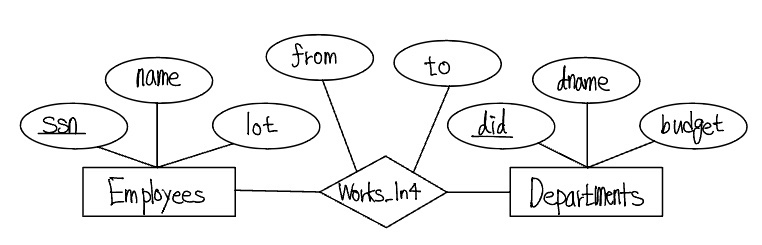
관계집합 Wokes_In4는 애트리뷰트 from 과 to 를 가지고 있는 반면, 관계집합 Works_In은 애트리뷰트 since 를 가지고 있다는 점에서 서로 다르다. 직과적으로, Works_In4는 한 직원이 어떤 부서에 근무하는 동안의 기간을 기록한다. 이제 한 직원이 어떤 부서에 여러 기간에 걸쳐 근무하는 것이 가능하다고 가정하자. 이는 다음 그림과 같이 from 과 to 애트리뷰트를 가진 개체집합 Duration을 도입함으로서 해결할 수 있다.
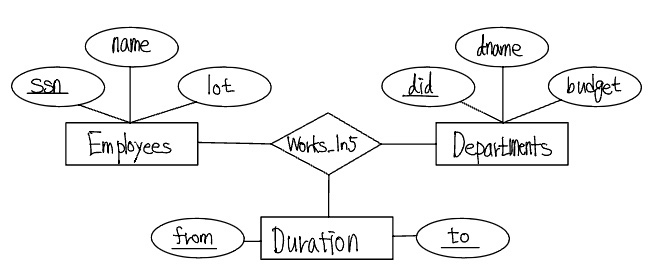
각 Works_In5 관계와 관련하여, 기간들의 집합을 가지게 된다. 이 방식이 Duration을 별도의 개체집합으로 모델링하는 것보다 더 직관적이다.
개체와 관계간의 선택
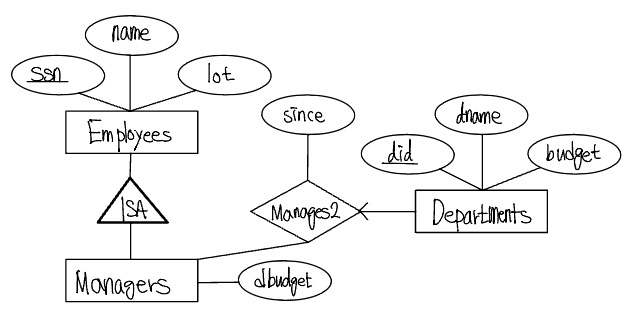
각 부서의 관리자가 임의로 집행할 수 있는 재량례산( dbudget )이 있다고 가정하자. 다음 그림은 관계집합을 Manages2로 다시 이름을 정하고 그 관계의 애트리부트로 dbudget이 추가되었다.
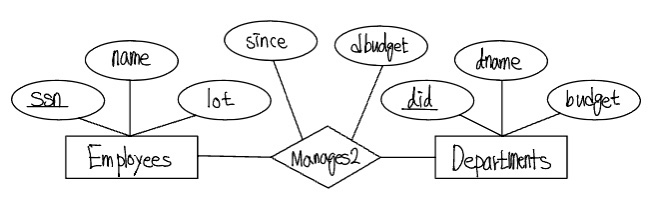
위 그림에서는 특정 부서에 대해, 그 부서의 관리자, 그 관리자의 시작날짜, 재량예산을 알 수 있다.
재량예산액이 그 직원에 의하여 관리되는 모든 부서들의 총 재량예산액이라면 어떻게 될까? 이런 경우에는, 이 직원을 포함하는 Manages2의 각 관계는 dbudget 필드에서 같은 값을 가지게 되고 같은 정보에 대한 중복 저장을 초래한다. 이런 문제들은 Managers라고 하는 새로운 개체집합을 도입함으로써 해결할 수 있다.
이진관계와 삼진관계간의 선택
다음 ER 다이어그램을 살펴보자.
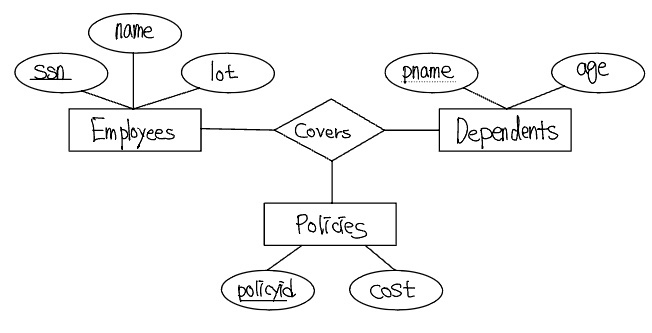
이 다이어그램은 한 직원은 여러 보험증권을 소유할 수 있고, 각 증권은 여러 직원에 의해 소유될 수 있으며, 각 부양가족은 여러 증권에 의해 보호될 수 있는 상황을 모델링하고 있다. 다음과 같은 추가 요구사항들이 있다고 가정하자.
- 하나의 보험증권은 두 명 이상의 직원에 의해 함께 소유될 수 없다.
- 각 보험증권은 반드시 어떤 직원에 의해 소유되어야 한다.
- 부양가족은 약개체집합이며, 각 부양가족 개체는 pname 과 그 부양가족을 보장하는 보험증권 개체의 policyid 와 조합하여 유일하게 식별된다.
첫 번째 요구사항의 Covers에 관하여 Policies 에 키 제약조건을 부여하도록 제안하지만, 이 제약조건은 한 증권이 단 한 명의 부양가족만 보장할 수 있다는 의도하지 아니한 부작용을 야기한다. 두 번째 요구사항은 Policise에 전채참여 제약조건을 부여하도록 한다. 이러한 해법은 각 증권이 적어도 한 명의 부양가족을 보장하는 경우에만 가능하다. 세 번째 요구사항은 이진 식별관계를 도입하도록 한다.
세 번째 요구사항을 무시한다 하더라도, 이러한 상황을 모델링하기 위해 가장 좋은 방법은 다음과 같이 두 개의 이진관계를 사용하는 것이다.
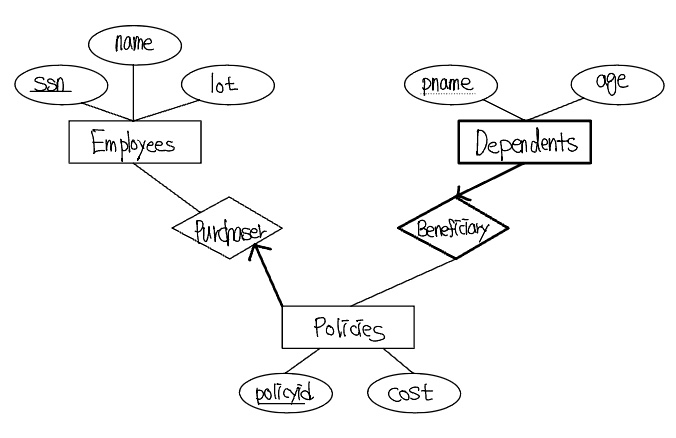
삼진관계의 대표적인 예로써, 개체집합 Parts, Suppliers, Departments와 이들간의 계약관계를 기술하는 애트리뷰트 qty 를 가지고 있는 관계집합 Contracts를 고려해보자. 하나의 계약은 한 공급자가 특정 부서로 특정 부품을 얼마만큼 공급할 것이라는 것을 명시한다. 이 관계는 이진관계들에 의해 적절히 표현될 수 없다. 이진관계를 이용하면, 어떤 공급자가 특정 부품을 ‘공급할 수 있다’라든가, 어떤 부서가 특정 부품을 ‘필요로한다’, 또는 어떤 부서가 특정 공급자와 ‘거래한다’는 사실을 표기할 수 있을 따름이다.
- 공급자 S가 부품 P를 공급할 수 있고 부서 D가 부품 P를 필요로 하며 부서 D가 공급자 S로부터 구매할 것이라는 사실이, 부서 D가 실제로 공급자 S로부터 부품 P를 구매한다는 것을 반드시 의미하지는 않는다.
- 계약의 애트리뷰트 qrt 를 분명히 표현할 수 없다.
댓글남기기