3장 관계모델
Updated:
관계모델은 매우 단순하며 정밀하다. 데이터베이스는 하나 이상의 릴레이션(relations)의 집합이며, 각 릴레이션은 행(row), 열(column)을 가진 일종의 테이블이다. 이렇게 간단한 테이블 형태의 표현이 초보 사용자들까지도 데이터베이스의 내용을 이해할 수 있게 하며, 데이터를 질의하기 위해 단순하고 고수준의 언어를 사용할 수 있게 한다. 관계모델은 그 이전의 데이터 모델들보다 더 좋은 주된 장점은 데이터 표현법이 단순하고 복잡한 질의도 쉽게 표현할 수 있다는 점이다.
관계모델의 소개
관계모델에서 데이터를 표현하는 주된 구성자는 릴레이션이다. 한 릴레이션은 릴레이션 스키마(relation schema)와 릴레이션 인스턴스(relation instance)로 이루어진다. 릴레이션 인스턴스는 테이블이며, 릴레이션 스키마는 그 테이블의 열(필드)들을 구성한다. 릴레이션 스키마는 그 릴레이션의 이름, 각 필드(열 혹은 애트리뷰트)의 이름과 도메인(domain)을 명시한다. 도메인은 릴레이션 스키마에서 도메인 이름(domain name)으로 언급되며 관련되는 값들의 집합이다.
Students(sid: string, name: string, login: string, age: integer, gpa: real)
위 예에서 sid라는 이름을 가진 필드는 string이라는 도메인을 가지고 있다는 것을 나타낸다.
한 릴레이션의 인스턴스(instance)는 레코드(record)라고 하는 투플(tuple)들의 집합이다. 각 투플들은 그 릴레이션 스키마와 동일한 수의 필드를 가지고 있다.
다음과 같이 Students 릴레이션의 한 인스턴스가 있다.
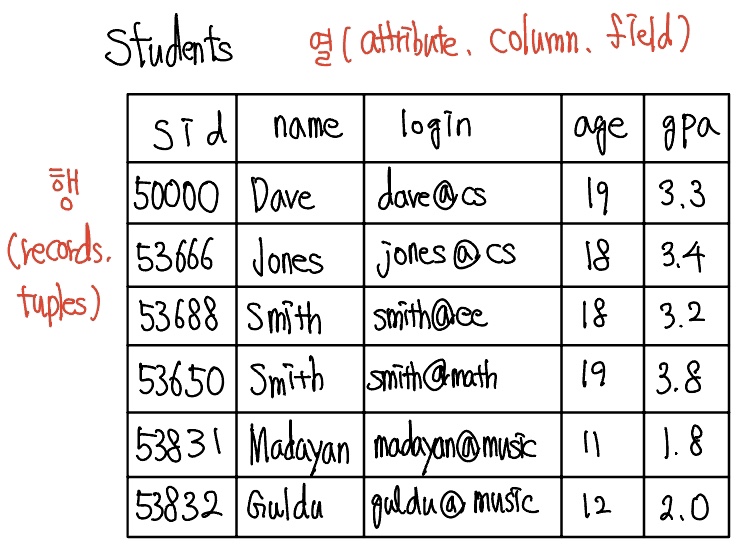
위 인스턴스는 여섯개의 투플과 다섯 개의 필드를 가지고 있다. 여기서 어떠한 두 행도 동일하지 않다. 만일 필드들의 이름이 명시되어 있다면 필드들의 순서는 중요하지 않다. 그러나 예를들어, sid는 Students의 필드 1이고 login은 필드 3인 것처럼 특정 순서로 팔드들을 열거하고 각 필드를 그 위치로 언급하면 필드의 순서는 중요하다.
릴레이션 스키마는 릴레이션 인스턴스에 있는 각 필드(열)의 도메인을 명시한다. 스키마에서 이러한 도메인 제약조건(domain constraints)은 그 릴레이션의 각 인스턴스가 만족해야하는 중요한 조건을 명시한다. 릴레이션의 차수(degree, arity)는 필드들의 수이다. 어떤 릴레이션 인스턴스의 카디날리티(cardinality)는 그 릴레이션에 원소로 있는 투플들의 수이다. 앞의 그림에서, 릴레이션의 차수는 5이고, 이 인스턴스의 카디날리티는 6이다.
SQL을 사용한 릴리이션의 생성 및 수정
SQL 언어 표준에서는 릴레이션을 표기하기 위해 테이블이라는 용어를 사용한다. SQL 중에서 테이블의 생성, 삭제, 수정하는 부분을 데이터 정의어(Data Definition Language, DDL)라고 한다. 다음 예제를 보자.


CREATE TABLE 문은 새로운 테이블을 정의하기 위해 사용한다.
CREATE TABLE Students (
sid CHAR(20),
name CHAR(30),
login CHAR(20),
age INTEGER,
gpa REAL
);
투플들은 INSERT 명령을 사용하여 삽입된다.
INSERT INTO Studnets (sid, name, login, age, gpa)
VALUES
(53688, 'Smith', 'smith@ee', 18, 3.2)
INTO 절에 있는 열 이름들을 옵션으로 생략하고 적절한 순서로 값들을 열거할 수 있으나, 열 이름들은 분명히 명시하는 것이 좋다.
DELETE 명령을 사용하여 투플들을 삭제할 수 있다. 다음과 같은 명령을 사용하여 이름이 Smith인 모든 Students 투플들을 삭제할 수 있다.
DELETE FROM Students S
WHERE S.name = 'Smith';
UPDATE 명령을 사용하여 이미 있는 행의 열 값을 수정할 수 있다. 예를 들어, sid가 53688인 학생의 나이를 증가시키고 평점평균울 감소시킬 수 있다.
UPDATE Student S SET S.age = S.age + 1, S.gpa = S.gpa - 1
WHERE S.sid = 53688
무결성 제약조건
무결성 제약조건(integrity constraint, IC)은 데이터베이스 스키마에 명시되는 조건으로서, 데이터베이스의 인스턴스에 저장될 수 있는 데이터를 제한한다. 데이터베이스 인스턴스가 그 데이터베이스 스키마에 명시되어 있는 모든 무결성 제약조건들을 만족하면, 그 데이터베이스 인터페이스는 적법한(legal) 인스턴스이다. DBMS는 무결성 제약조건들을 집행하여 적법한 인스턴스들만 데이터베이스에 저장되도록 허용한다.
키 제약조건
키 제약조건((Primary)key constraint)은 릴레이션에 속한 필드들의 어떤 최소 부분집합이 각 투플에 대한 고유한 식별자라는 선언이다. 이 키 제약조건에 의하여 투플들을 유일하게 식별하는 필드 집합을 그 릴레이션에 대한 후보키(candidate key)라고 하며, 이것을 줄여서 키라고 한다. (후보)키에 대한 정의를 좀 더 자세히 살펴보자
- 적법한 인스턴스에서 서로 다른 두 투플들은 키에 속하는 모든 필드 전체를 통하여 동일한 값을 가질 수 있다.
- 어떤 적법한 인스턴스에서든지, 키 필드에 있는 값들은 그 인스턴스의 투플들을 유일하게 식별한다.
- 키를 구성하는 필드들의 집합의 어떠한 부분집합도 투플에 대한 유일한 식별자가 될 수 없다.
- 예를들어, {sid, name}이라는 필드 집합은 키 {sid}를 진부분집합으로 포함하고 있기 때문에, Student에 대한 키가 아니라는 것을 의미한다. 집합 {sid, name}은 수퍼키(super key)의 예이고, 수퍼키는 키를 포함하는 필드들의 집합이다.
- 한 릴레이션은 여러 개의 후보키를 가질 수 있다. 예를 들어, Student 릴레이션의 login 필드와 age 필드가 함께 모여 학생들을 유일하게 식별할 수도 있다. 즉, {login, age} 역시 키이다.
- 키는 해당 릴레이션의 있을 수 있는 모든 적법한 인스턴스에서 투플들을 유일하게 식별하여야 한다. {login, age}를 키라고 명시함으로써, 두 학생은 같은 로그인 값이나 같은 나이 값을 가질 수 있지만 둘 다 동일한 값을 가질 수는 없다고 선언하는 것이 된다.
모든 가능한 후보키들(candidate key) 중에서, 데이터베이스 설계자는 기본키(primary key)를 하나 지정할 수 있다. 원칙적으로, 한 투플을 언급하기 위해 기본키 뿐만 아니라 어떠한 키도 사용할 수 있다. 그렇지만, DBMS가 예상하고 최적화를 하는 것이 기본키이기 때문에 기본키를 사용하는 것이 더 좋다.
SQL에서 키 제약조건 명시
SQL에서, UNIQUE 제약조건을 사용함으로써 한 테이블에 속한 필드들의 부분집합이 키임을 선언할 수 있다. 이 후보키들 중에서 최대로 하나만 PRIMARY KEY 제약조건을 사용함으로써 기본키로 선언될 수 있다.(이와 같은 제약조건들이 필수적으로 선언되도록 요구하지는 않는다.)
CREATE TABLE Students (
sid CHAR(20),
name CHAR(30),
login CHAR(20),
age INTEGER,
gpa REAL,
UNIQUE (name, age),
CONSTRAINT StudentsKey PRIMARY KEY (sid)
);
이 정의는 sid가 기본키이며 name, age의 조합 역시 하나의 키임을 말한다.
외래키 제약조건
가끔 한 릴레이션에 저장된 정보가 다른 릴레이션에 저장된 정보로 링크될 수 있다. 이 릴레이션들 중의 하나가 수정되면, 데이터의 일관성을 유지하기 위해 다른 릴레이션도 점검되어야 하고, 경우에 따라 수정되어야 한다. DBMS가 이러한 점검을 수행하려면, 두 릴레이션을 모두 포함하는 하나의 IC가 명시되어야 한다. 두 개의 릴레이션을 포함하는 가장 일반적인 IC는 외래키 제약조건(foreign key constraint)이다.
Students 릴레이션에 추가하여, 다음과 같은 두 번째 릴레이션이 있다고 하자.
Enrolled(studid: string, cid: string, grade: string)
실제로 존재하는 학생들만 과목을 등록할 수 있다는 것을 보장하기 위해, Enrolled 릴레이션의 인스턴스의 studid 필드에 나타나는 값은 반드시 Students 릴레이션에 있는 어떤 투플의 sid 필드에 나타나야 된다. 이 경우 Enrolled 릴레이션의 studid 필드는 외래키(foreign key)라고 하며, Students를 참조한다(refer). 다음 예제를 보자.
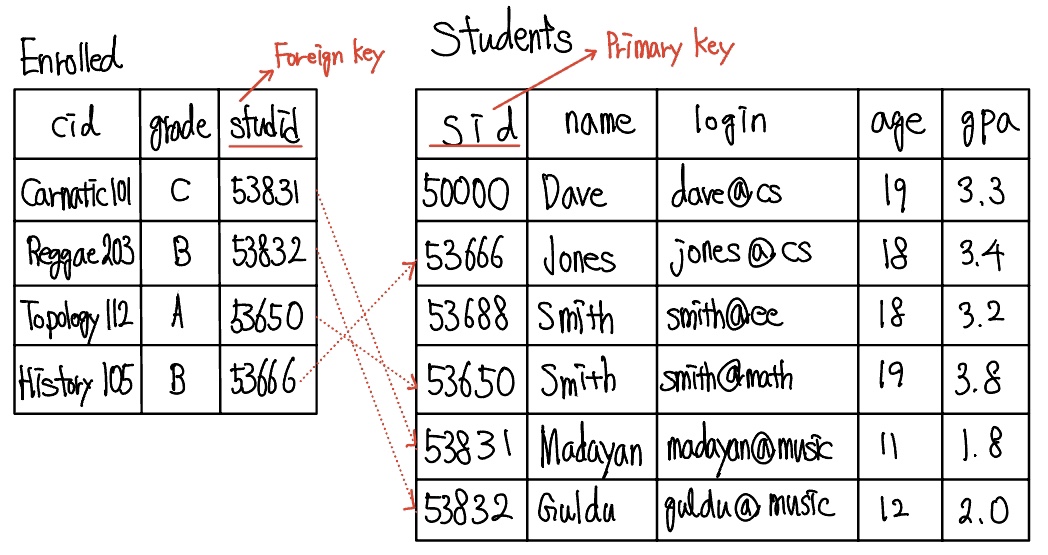
Enrolled 테이블의 인스턴스에 투플 <55555, Art104, A>를 삽입하려고 하면, Students 테이블의 인스턴스에 sid 55555를 가진 투플이 없으므로 IC에 위배된다. 따라서 데이터베이스 시스템은 이러한 삽입 연산을 거부해야 한다. 이와 유사하게, S1으로부터 투플 <53666, Joned, jones@cs, 18, 3.4>를 삭제한다면, Enrolled에 있는 투플 <53666, History105, B>가 studid 값 53666, 즉 삭제된 투플의 sid값을 포함하기 때문에, 외래키 제약조건을 위배한다. DBMS는 이 삭제연산을 불허하거나 삭제된 Student 투플을 참조하고 있는 Enrolled 투플들을 역시 삭제하여야 한다.
외래키는 동일한 릴레이션을 참조할 수도 있다는 점을 유의하자. 예를들어, Student 릴레이션을 확장하여 partner라는 열을 추가하고 이 열이 Students를 참조하는 외래키라고 선언할 수 있다. 어느 학생이나 단짝이 있을 수 있고, partner 필드는 그 단짝의 sid값을 포함한다. 만약 단짝이 없는 학생이 있을 경우 SQL에서 널(null)이라는 특수한 값을 사용함으로써 처리된다. 한 투플의 어떤 필드에 null 값을 사용하는 것은 그 필드의 값을 모르거나 적용할 수 었다는 것을 의미한다. 외래키 필드에 null 값이 나타나는 것은 외래키 제약조건을 위배하지 않는다. 그렇지만, null 값은 기본키 필드에는 허용되지 않는다. 기본키는 한 투플을 유일하게 식별하기 위해 사용되기 때문이다.
SQL에서 외래키 제약조건 명시
다음과 같이 Enrolled를 SQL로 정의하자.
CREATE TABLE Enrolled (
studid CHAR(20),
cid CHAR(20),
grade CHAR(10),
PRIMARY KEY (studid, cid),
FOREIGN KEY (studid) REFERENCES Students
);
외래키 제약조건은 Enrolled 릴레이션에 있는 모든 studid 값이 Students 릴레이션에 반드시 나타나야 한다는 것을 선언한다. 즉, Enrolled에 있는 studid 값이 Students 릴레이션에 반드시 나타나야 한다는 것을 선언한다. 즉, Enrolled에 있는 studid는 Students를 참조하는 외래키이다.
일반적인 제약조건
도메인, 기본키, 외래키 제약조건들은 관계 데이터 모델의 기초적인 부분으로 취급된다. 대부분의 사용 시스템은 이 제약조건들에 대하여 각별한 주의를 기울이고 있다. 그러나, 때는 이들보다 좀 거 일반적인 제약조건들을 명시할 필요가 있다.
예를들어, 학생들의 나이가 일정한 범위의 값 이내에 있어야 한다고 요구할 수 있다. 이러한 IC 명세서가 주어지면, DBMS는 이 제약조건을 위배하는 삽입이나 갱신을 거부한다. 이 방법은 데이터 입력 오류를 방지하는 데에 매우 유용하다.
현재의 관계 데이터베이스 시스템은 테이블 제약조건(table constraint)과 단언(assertion)의 형식으로 이러한 일반적인 제약조건들을 지원한다. 테이블 제약조건은 단일 테이블에 관한것으로서, 해당 테이블이 수정될 때마다 검사된다. 반면에, 단언은 여러 테일블을 포함하며, 이들 중 한 테이블이 수정될 때마다 검사된다.
무결성 제약조건의 집행
제약조건들은 릴레이션이 생성될 때 명시되고 릴레이션이 수정될 때 집행된다. 도메인, PRIMARY KEY, UNIQUE 제약조건의 효과는 직접적이다. 위배를 야기하는 삽입, 삭제, 생신 명령은 거부된다. 제약조건의 위배 여부는 일반적으로 각 SQL문의 실행의 마지막에 검사되는데, 그 문장을 실행하는 트랜잭션의 마지막까지 연기(defer)될 수 있다. 다음 예제를 보자.
앞의 Students 인스턴스를 생각해보자. 다음의 삽입은 sid 53688을 가진 투플이 이미 있기 때문에 기본키 제약조건을 위배하므로, DBMS에 의해 거부될 것이다.
INSERT INTO Studnets (sid, name, login, age, gpa)
VALUES
(53688, 'Mike', 'mike@ee', 17, 3.4);
다음의 삽입은 기본키가 널 값을 포함할 수 없다는 제약조건을 위배한다.
INSERT INTO Students (sid, name, login, age, gpa)
VALUES
(null, 'Mike', 'mike@ee', 17, 3.4);
어떤 필드에서 해당 도메인에 속하지 않는 값을 가진 투플을 삽입하려고 할 때마다 유사한 문제가 야기된다. 삭제는 도메인, 기본키, 유일성 제약조건을 위배하는 원인이 되지 않는다. 그러나, 갱신의 경우에는 삽입과 유사한 위배를 초래할 수 있다.
UPDATE Students S SET S.sid = 50000
WHERE S.sid = 53688;
이 갱신은 sid 50000인 투플이 이미 있기 때문에 기본키 제약조건을 위배한다. Enrolled와 Students 테이블과, Enrolled.sid는 Student의 기본키를 참조한다는 외래키 제약조건이 있다는 점에 의거하여, DBMS에 의해 취해지는 참조 무경성 집행 단계(referential integrity enforcement step)들을 논의한다. Students 인스턴스뿐만 아니라, Enrolled 인스턴스를 고려해보자. Enrolled 투플들의 삭제는 참조 무결성을 위배하지 않지만, Enrolled 투플들의 삽입은 참조 무결성을 위해할 수 있다. 다음과 같은 삽입은 sid 51111을 가진 Students 투플이 없기 때문에 부당하다.
INSERT INTO Enrolled (cid, grade, studid)
VALUES
('Hindi101', 'B', 51111)
이외는 반대로, Students 투플의 삽입은 참조 무결성을 위배지 않으나, Students 투플의 삭제는 위배를 야기할 수 있다. 더구나 studid(sid) 값을 변경하는 Enrolled(Students)에 대한 갱신은 잠정적으로 참조 무결성을 위배할 가능성이 있다. SQL은 외래키 제약조건의 위배를 처리하기 위한 몇 가지 대안을 제공한다. 다음 예시를 보자.
- Enrolled에 한 행이 삽입될 때, 만약 그 행의 studid 열의 값이 Students 테이블의 어떠한 행에도 나타나지 않을 경우에는 어떻게 할 것인가?
- 이 경우에는, INSERT 명령이 단순히 거부된다.
- Students 행이 삭제되면 어떻게 할 것인가? 옵션들은 다음과 같다.
- 삭제된 Students 행을 참조하는 모든 Enrolled 행들을 삭제한다.
- 어떤 Enrolled 행이 그 Students 행을 참조하고 있으면 그 행의 삭제를 금지한다.
- 삭제된 Students 행을 참조하고 있는 모든 Enrolled 행들에 대해서 studid 열을 어떤 (존재하는) ‘디폴트’ 학생의 sid 값으로 설정한다.
- 삭제된 Students 행을 참조하고 있는 모든 Enrolled 행들에 대해서, studid 열의 값을 null로 설정한다.
SQL은 DELETE와 UPDATE에 대해서 이 네가지 옵션 중 어느 하나를 선택할 수 있게 한다.
CREATE TABLE Enrolled (
studid CHAR(20),
cid CHAR(20),
grade CHAR(10),
PRIMARY KEY (studid, cid),
FOREIGN KEY (studid) REFERENCES Students
ON DELETE CASCADE
ON UPDATE NO ACTION
);
이러한 옵션들은 외래키 선언의 일부로 명시된다. 디폴트 옵션은 NO ACRION인데, 이것은 실행(DELETE나 UPDATE)이 거부되어야 한다는 의미이다. 따라서, 이 예에서 ON UPDATE절은 생략해도 똑같은 효과를 나타낸다. CASCADE라는 키워드는 만약 한 Students 행이 삭제되면, 이를 참조하는 모든 Enrolled 행들을 역시 삭제되어야 함을 말한다. ON UPDATE절에 CASCADE를 명시하였을 경우, 어떤 Students 행의 sid 열이 갱신되면, 이 갱신된 Students행을 참조하고 있는 각 Enrolled 행에서도 갱신이 수행된다. 어떤 Students 행이 삭제되면, 이를 참조하는 모든 Enrolled 행들이 ON DELETE SET DEFAULT를 사용하여 ‘디폴트’ 학생을 참조하도록 전환할 수 있다. 이떼 디폴트 학생은 Enrolled의 studid 필드를 정의할 때 그 일부로 명시된다. (예, sid CHAR(20) DEFAULT ‘53666’) 디폴트 값의 명세가 어떤 상황에서는 적정하지만, 수강 내용을 디폴트 학생으로 바꾸는 것은 사실 적절하지 못하다. 이 예에서 알맞는 해결책은 삭제된 학생이 수강하던 과목에 대한 모든 행들을 삭제하거나(CASCADE) 그 갱신 자체를 거부하는 것이다. SQL은 ON DELETE SET NULL이라고 명시함으로써 디폴트 값으로 널의 사용을 역시 허용한다.
논리적 데이터베이스 설계: ER을 관계모델로
ER 모델은 초기의 고수준 데이터베이스 설계를 표현하기에 편리하다. 어떤 데이터베이스를 기술하는 ER 다이어그램이 있을 때, 이에 매우 근사하게 관계 데이터베이스 스키마를 생각하는 표준적인 접근방식이 있다.
개체집합을 테이블로
하나의 개체집합은 간단하게 하나의 릴레이션으로 사상된다. 즉, 개체집합의 각 애트리뷰트가 테이블의 애트리뷰트가 된다. 개체집합의 각 애트리뷰트의 도메인과 (기본)키를 알고 있다는 점을 유의하자. 다음과 같이 snn, name, lot 애트리뷰트들을 가지고 있는 Employees 개체집합을 생각해보자.
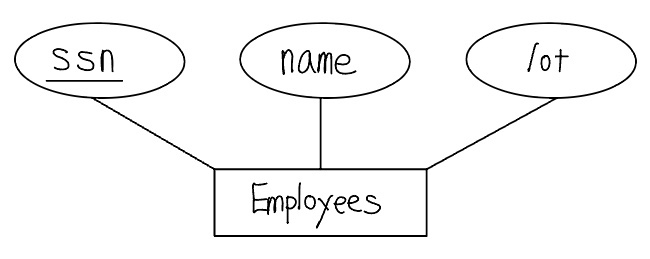
세 명의 Employees 개체를 포함하는 Employees 개체집합의 한 인스턴스를 테이블로 나타내면 다음과 같다.
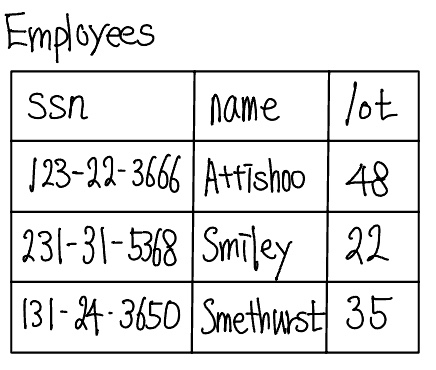
다음 SQL 문장은 도메인 제약조건과 키 정보를 포함하여 지금까지 기술한 정보를 표현한다.
CREATE TABLE Employees (
ssn CHAR(11),
name CHAR(30),
lot INTEGER,
PRIMARY KEY (ssn)
);
(제약조건이 없는) 관계집합을 테이블로
개체집합처럼 관계집합도 관계모델의 한 릴레이션으로 사상된다. 먼저 키 제약 조건과 참여 제약조건이 없는 관계집합을 살펴보자. 하나의 관계를 표현하기 위해, 참여하는 각 개체를 식별하고 관계을 기술하는 애트리뷰트에 값을 부여할 수 있어야 한다. 따라서, 그러한 릴레이션의 애트리뷰트들은 다음을 포함한다.
- 참여하는 각 개체집합의 기본키에 속하는 애트리뷰트들(외래키 역할)
- 관계집합을 서술하는 애트리뷰트들
기술용이 아닌 애트리뷰트들의 집합이 릴레이션의 수퍼키가 된다. 만약 키 제약조건이 없다면, 이 애트리뷰트들의 집합이 후보키가 된다. 다음 Works_In2 관계집합을 보자. 각 부서는 여러 장소에 사무실을 두고 있으며 우리는 각 직원이 근무하는 장소를 기록하고 싶다.
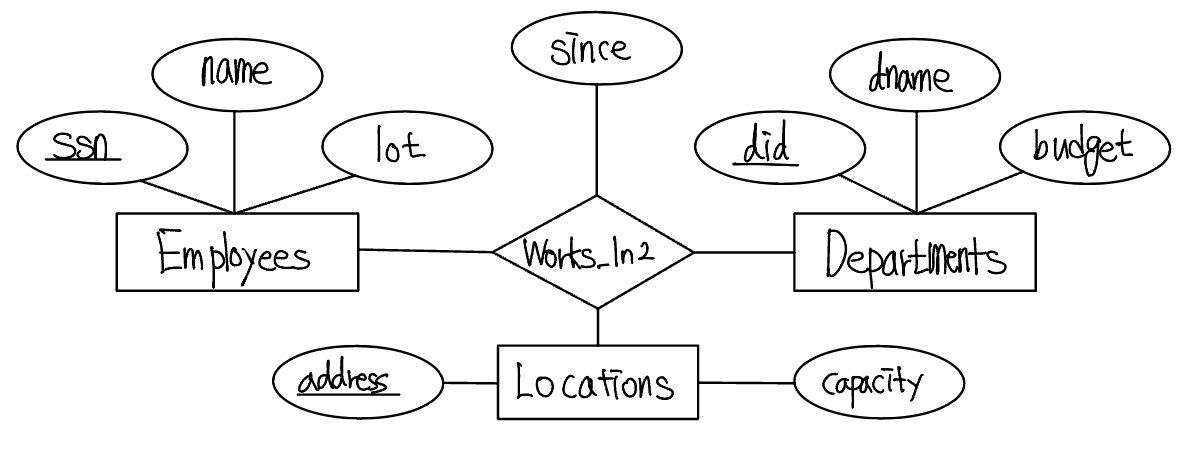
Works_In2 테이블에 관하여 이용 가능한 정보는 다음의 SQL 정의에 의해 표현된다.
CREATE TABLE Works_In2 (
ssn CHAR(11),
did INTEGER,
address CHAR(20),
since DATE,
PRIMARY KEY (ssn, did, address),
FOREIGN KEY (ssn) REFERENCES Employees,
FOREIGN KEY (address) REFERENCES Locations,
FOREIGN KEY (did) REFERENCES Departments
);
address, did, snn 필드는 null값을 가질 수 없다는 점을 유념하라. 이 기본키 제약조건은 이 필드들이 Works_In2의 각 투플에 있는 부서, 직원, 장소를 유일하게 식별하는 것을 보장한다.
다음의 Reprots_To 관계집합을 생각해보자. 역할 지시자 supervisor(감독자)와 subordinate(부하)가 Reports_To 테이블의 CREATE문에 의미가 있는 필드 이름을 생성하기 위해 사용될 수 있다.
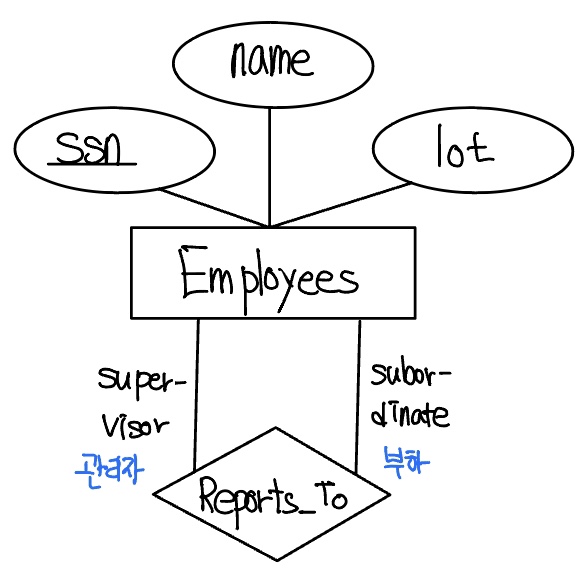
CREATE TABLE Reports_To (
supervisor_ssn CHAR(11),
subordinate_ssn CHAR(11),
PRIMARY KEY (supervisor_ssn, subordinate_ssn),
FOREIGN KEY (supervisor_ssn) REFERENCES Employess(ssn),
FOREIGN KEY (subordinate_ssn) REFERENCES Employees(ssn)
);
키 제약조건이 있는 관계집합의 변환
어떤 관계집합은 n개의 개체집합을 포함하고 그들 중 m개가 ER 다이어그램의 화살표로 연결되어 있다면, 이 m개의 개체집합 중 어느 집합의 키이든지 이 관계집합이 사상되는 릴레이션의 키가 될 수 있다. 따라서 m개의 후보키가 존재하게 되는데, 이들 중 하나가 기본키로 지정되어야 한다. 다음 Manages 관계집합을 살펴보자.
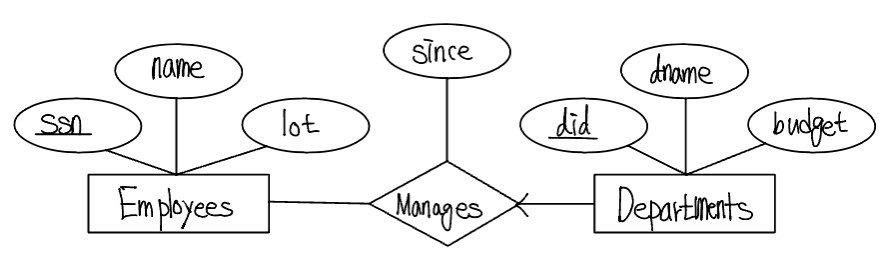
Manages에 대응하는 테이블은 ssn, did, since 애트리뷰트를 가지고 있다. 그러나, 각 부서가 많아야 한 명의 관리자를 두므로, 어떠한 두 투플도 did 값이 같으면서 ssn 값이 다른 경우가 없다. 그러므로 did가 Manages의 키가 될 수 있다. did와 snn으로 이루어진 집합은 키가 아니다(최소의 집합이 아니므로). Manages 릴레이션은 다음과 같은 SQL문으로 정의될 수 있다.
CREATE TABLE Manages (
ssn CHAR(11),
did INTEGER,
since DATE,
PRIMARY KEY (did),
FOREIGN KEY (ssn) REFERENCES Employees,
FOREIGN KEY (did) REFERENCES Departments
);
이 방식의 유일한 단점은 여러 부서에서 관리자가 없는 경우에 공간이 낭비될 수 있다는 점이다. 이 경우에, 추가된 필드들이 null 값으로 채워져야 할 것이다. ssn이 null 값을 취할 수 있게 하기위해 Departments와 Manages의 정보를 모두 표현하는 Dept_Mgr 릴레이션을 정의하는 SQL문을 보자.
CREATE TABLE Dept_Mgr (
did INTEGER,
dname CHAR(20),
budget REAL,
ssn CHAR(11),
since DATE,
PRIMARY KEY (did),
FOREIGN KEY (ssn) REFERENCES Employess
);
참여 제약조건이 있는 관계집합의 변환
두 관계집합 Managers와 Works_In을 나타내고 있는 다음 ER 다이어그램을 살펴보자.
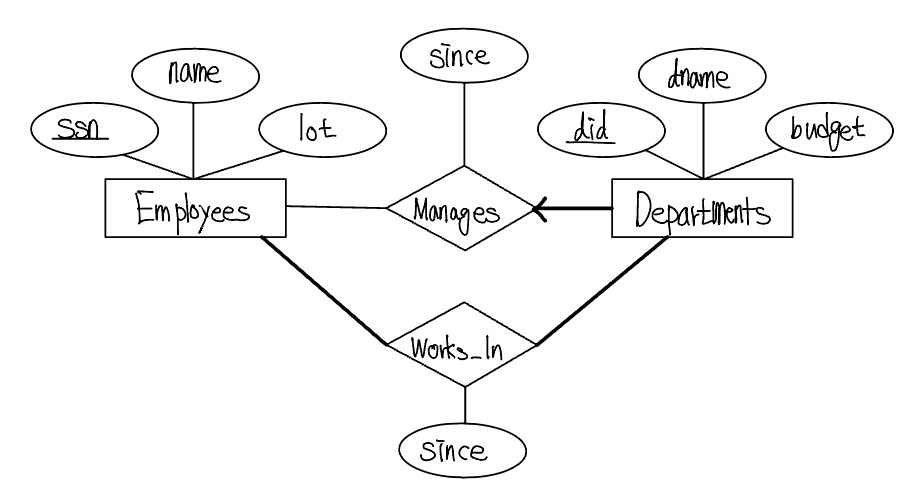
참여 제약조건에 의하여 각 부서마다 관리자가 있어야 하며, 키 제약조건에 의하여 각 부서는 최대 한 명의 관리자를 둘 수 있다. 다음 SQL문을 보자.
CREATE TABLE Dept_Mgr (
did INTEGER,
dname CHAR(20),
budget REAL,
ssn CHAR(11) NOT NULL,
since DATE,
PRIMARY KEY (did),
FOREIGN KEY (ssn) REFERENCES Employess
ON DELETE NO ACTION
);
이 SQL문은 각 부서는 반드시 관리자가 있어야 한다는 참여 제약조건을 표현한다. ssn이 null값을 취할 수 없으므로 Dept_Mgr의 각 투플은 Employees에 있는 투플을 식별한다. NO ACTION은 디폴트이므로 반드시 명시될 필요는 없지만, 이를 명시함으로써 한 Employee 투플이 Dept_Mgr 투플에 의해 참조되고 있는 한 그 Employee 투플은 삭제될 수 없음을 보장한다. 만약 그러한 Employees 투플을 삭제하기를 원하면, Dept_Mgr 투플을 먼저 변경하여 새로운 직원이 관리자가 되도록 해야 한다.
약개체집합의 변환
약개체집합은 항상 일-대-다의 이진관계에 참여하며, 키 제약조건과 전체 참여를 수반한다. 약개체는 부분키만 가지고 있다는 것을 고려하고 한 소유자 개체가 삭제되면, 이 소유자에게 소속된 모든 약개체들도 삭제되어야 한다. 다음 약개체집합 Dependents를 살펴보자.
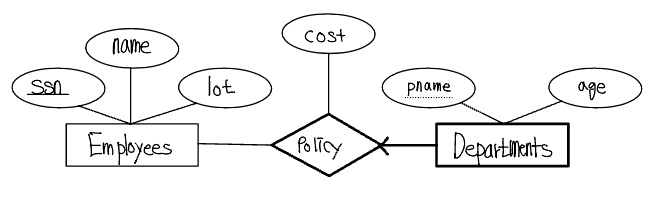
Dependents는 부분키 pname을 가지고 있다. Dependents 개체는 소유하는 Employees 개체의 키와 그 Dependents 개체의 pname을 취하는 경우에만 유일하게 식별된다. 그리고 소유하는 Employees 개체가 삭제되면 해당하는 Dependents 개체들도 삭제되어야 한다. 다음과 같은 Dept_Policy 릴레이션의 정의로 우리가 원하는 의미를 표현할 수 있다.
CREATE TABLE Dept_Policy (
pname CHAR(20),
age INTEGER,
cost REAL,
ssn CHAR(11),
PRIMARY KEY (pname, ssn),
FOREIGN KEY (ssn) REFERENCES Employees
ON DELETE CASCADE
);
Dependents는 약개체이므로 기본키는 <pname, ssn>임을 유의하자. Dependents의 전체참여 제약조건에 의하여 각 Dependents 개체는 하나의 Employees 개체(소유자)와 연결되어 있다는 것을 확실히 해야한다. 즉, ssn은 null이 될 수 없다. ssn이 기본키의 일부이므로 이 점은 보장된다. CASCADE 옵션은 한 Employees 투플이 삭제되면 그 직원에 대한 보험증권과 피부양자에 관한 정보도 삭제되는 것을 보장한다.
클래스 계층구조의 변환
ISA 계층을 처리하는 두 가지 기본적인 방식은 다음 ER 다이어그램에 적용해본다.
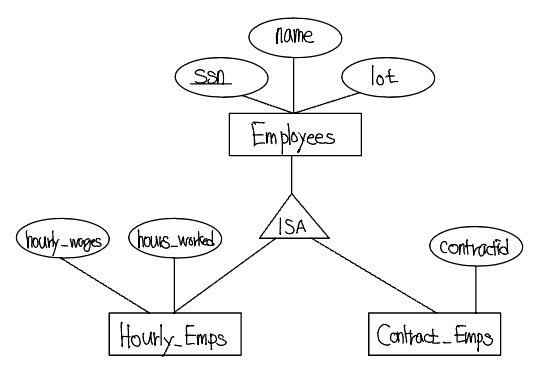
- 개체집합 Employees, Hourly_Emps, Contract_Emps의 각각을 각기 다른 릴레이션으로 사상할 수 있다. Hourly_Emps에 대한 릴레이션은 Hourly_Emps의 hourly_wages와 hours_woeked 애트리뷰트들을 포함한다. 또한 슈퍼클래스의 키 애트리뷰트(ssn)를 포함하는데, 이 애트리뷰트는 Hourly_Emps 릴레이션의 기본키이며, 또한 슈퍼클래스(Employess)를 참조하는 외래키이다.각 Hourly_Emps 개체에 대한 name과 lot 애트리뷰트들의 값은 슈퍼클래스(Employees)의 대응하는 행에 저장된다. 이 슈퍼클래스 투플이 삭제되면, 그 삭제가 Hourly_Emps에 연쇄적으로 적용되어야 한다.
- Hourly_Emps와 Contrac_Emps에 대응하는 두 릴레이션만 생성할 수 있다. Hourly_Emps에 대한 릴레이션은 Employees의 모든 애트리뷰트뿐만 아니라 Hourly_Emps의 모든 애트리뷰트를 포함한다.(ssn, name, lot, hourly_wages, hourly_worked)
첫 번째 방식은 일반적이고 항상 적용 가능하다. 모든 직원들을 조사하는 것이 필요하나 서브클래스에 국한된 애트리뷰트들과는 관련이 없는 질의는 Employees 릴레이션을 이용하여 쉽게 처리된다. 그렇지만, 시간제 직원에 대해 조사하는 것이 필요한 질의들은 Hourly_Emps(혹은 Contract_Emps)와 name과 lot을 검색하기 위해 Employees를 결합하는 것을 필요로할 수 있다. 만일 시간제 직원도 아니고 계약제 직원도 아닌 직원이 있다면 두 번째 방식은 이러한 직원을 저장할 방법이 없으므로 적용할 수 없다. 또한, 한 직원이 Hourly_Emps 개체이면서 동시에 Contract_Emps 개체라면, name과 lot은 두 번 저장되게 된다.
집단화가 있는 ER 다이어그램의 변환
다음 ER 다이어그램을 보자.
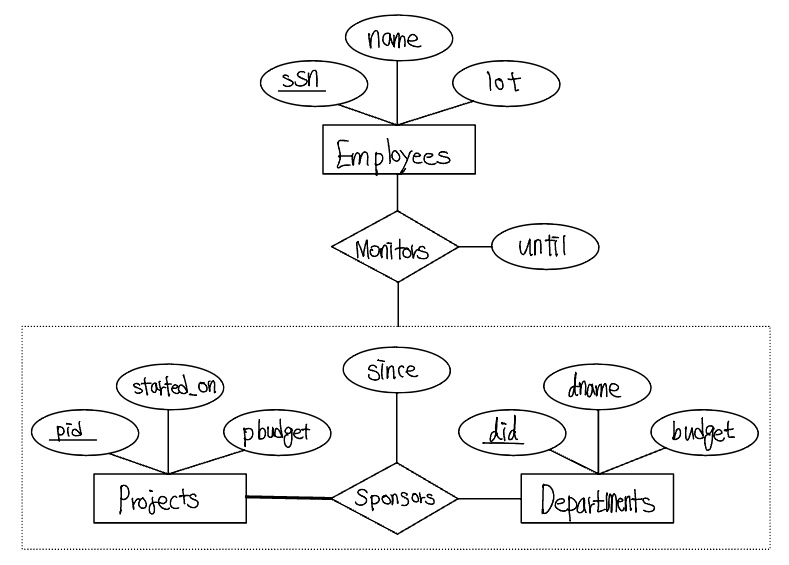
Monitors 관계집합을 위해서 Employees의 키 애트리뷰트(ssn), Sponsors의 키 애트리뷰트(did, pid), Monitors이 기술용 애트리뷰트(until)를 가진 릴레이션을 생성한다. 이 방식은 Sponsors 릴레이션을 제거함으로써 정제될 수 있는 특수한 경우가 있다. Sponsors 릴레이션을 생각해보면, pid, did, since 애트리뷰트를 가지고 있다. 일반적으로 다음 두 가지 이유로 릴레이션이 필요하다.
- Sponsors 관계의 기술용 애트리뷰트(since)를 기록해 두어야한다.
- 각 자금지원을 모두 감독하는 것은 아니므로, Sponsors 릴레이션에 있는 어떤 (did, pid) 쌍들은 Monitors 릴레이션에 나타나지 않을 수 있다.
그렇지만, Sponsors가 기술적인 애트리뷰트를 가지고 있지 않고 Monitors 관계에 전체적으로 참여한다면, Sponsors 릴레이션의 모든 가능한 인스턴스는 Monitors 릴레이션의 <pid, did> 필드들로부터 얻어질 수 있다. 이 경우 Sponsors 릴레이션은 제거될 수 있다.
ER에서 관계모델로: 추가 예제
다음 ER 다이어그램을 보자.
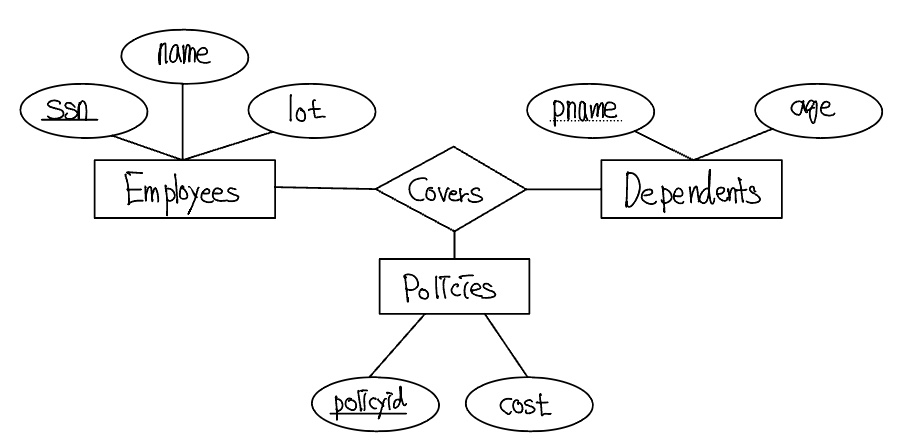
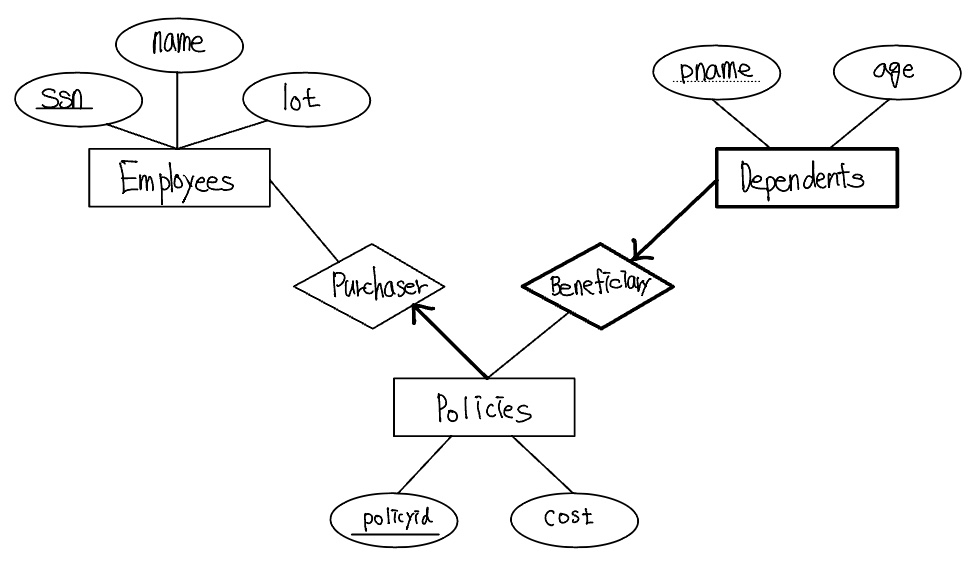
위 두 ER 다이어그램에서 아래의 설계가 더 좋은 모델이다. 아래 ER 다이어그램은 Purchaser 정보와 Policies, Beneficiary 정보와 Dependents 를 결합하기 위해 키 제약조건을 사용할 수 있으며, 이를 다음과 같이 관계모델로 변환할 수 있다.
CREATE TABLE Policies (
policyid INTEGER,
cost REAL,
ssn CHAR(11) NOT NULL,
PRIMARY KEY (policyid),
FOREIGN KEY (ssn) REFERENCES Employees
ON DELETE CASCADE
);
CREATE TABLE Dependents (
pname CHAR(20),
age INTEGER,
policyid INTEGER,
PRIMARY KEY (pname, policyid),
FOREIGN KEY (policyid) REFERENCES Policies
ON DELETE CASCADE
);
한 직원의 삭제가 어떻게 그 직원에 의하여 소유된 모든 보험증권들의 삭제와 이 보험증권들의 수혜자인 모든 피부양자들의 삭제를 유도하는가를 주목하자. 각 피부양자는 하나의 보험 증권을 가져야 한다. 이 모델은 ER 다이어그램에 있는 참여 제약조건과 한 직원 개체가 삭제될 때 의도하는 조치들을 정확하게 반영하고 있다.
일반적으로, 약개체집합애 대해 관계들을 식별하는 체인이 존재할 수 있다. 예를 들어, 지금까지는 policyid가 보험증권을 유일하게 식별한다고 가정하였다. 그런데 policyid가 주어진 직원에 소유된 증권들만을 구별한다고 가정하자. 즉, policyid는 단지 부분키이고 Policies는 약개체집합으로 모델링 되어야 한다. policyid에 대한 이러한 새로운 가정은 이전의 논의에서 많은 부분을 변경하도록 하지는 않는다. 실제로, 유일하게 새로운 가정은 이전의 논의에서 많은 부분을 변경하도록 하지는 않는다. 실제로, 유일하게 변경할 부분은 Policied의 기본키를 <policyid, ssn>으로 하는 것이며, 결과적으로 Dependents의 정보도 변경된다.
CREATE TABLE Dependents (
pname CHAR(20),
ssn CHAR(11),
age INTEGER,
policyid INTEGER NOT NULL,
PRIMARY KEY (pname, policyid, ssn),
FOREIGN KEY (policyid, ssn) REFERENCES Policies
ON DELETE CASCADE
);
뷰의 개요
뷰(view)는 일종의 테이블로서 이에 속해있는 행들이 실제로 데이터베이스에 저장되지 않고 뷰 정의(view definition)를 이용하여 필요한 대로 계산된다. Students 릴리이션과 Enrolled 릴레이션을 생각해보자. 어느 과목에서 B학점을 받은 학생들의 이름, 학번, 그 과목번호를 검색하기를 원한다고 가정하면, 이 목적을 위해 다음과 같이 뷰를 정의할 수 있다.
CREATE VIEW B-Student (name, sid, course)
AS SELECT S.name, S.sid, S.cid
FROM Student S, Enrolled E
WHERE S.sid = E.studid AND E.grade = 'B'
뷰 B-Stuents는 name, sid, course라는 세 개의 애트리뷰트를 가지고 있는데 각각은 Students에 있는 필드 sname과 sid, Enrolled에 있는 cid와 그 도메인이 같다. 어떤 기본 테이블이 더 이상 필요하지 않아 제거할 때에는 DROP TABLE 명령을 사용할 수 있다. 예를 들어 DROP TABLE Students RESTRICT 명령은 어떤 뷰나 무결성 제약조건이 Students를 참조하지 않으면 Students 테이블은 제거한다. 만약 어떤 뷰나 무결성 제약조건이 Students를 참조하면, 이 명령은 실패한다. 키워트 RESTRICT 대신 CASCADE를 사용하면, Students는 제거되고 이를 참조하는 뷰나 무결성 제약조건도 연쇄적으로 제거된다. 이 두 키워드 중의 하나는 반드시 명시되어야 한다. 뷰는 DROP VIEW 명령을 사용하여 제거될 수 있고, 이 명령은 DROP TABLE과 비슷하다.
뷰, 보안
뷰는 보안(security)의 관점에서도 가치가 있다. 어떤 그룹의 사용자들에게 그들이 볼 수 있도록 허락된 정보에만 접근하도록 하는 뷰를 정의할 수 있다. 예를 들어, 학생들로 하여금 다른 학생들의 정보에만 접근하도록 하는 뷰를 정의할 수 있다. 예를들어, 학생들로 하여금 다른 학생들의 이름과 나이는 볼 수 있으나 평점평균을 볼 수 없도록 하는 뷰를 정의할 수 있으며, 모든 학생들이 이 뷰를 접근할 수 있지만 기반이 되는 테이블 Students를 접근할 수 없도록 할 수 있다.
댓글남기기