6장 데이터베이스 응용 개발
Updated:
응용에서 데이터베이스 접근
SQL 명령들이 C나 JAVA와 같은 호스트 언어의 프로그램 내부로부터 어떻게 실행될 수 있는지를 알아보자. 호스트 언어 프로그램 내에서 SQL 명령들을 사용하는 것을 내장형(Embedded) SQL이라고 한다. 내장형 SQL의 세부 항복들은 물론 호스트 언어에 종속된다.
내장형 SQL
SQL 문은 호스트 언어에서 문장이 허용된 어디서든지 사용될 수 있다. SQL 문은 전처리기가 호스트 언어에 대한 컴파일러를 수행하기 전에 그들을 취급할 수 있도록 분명히 표시되어야 한다. 또한 SQL 명령으로 인수들을 전달하기 위해 사용되는 어떤 호스트 언어 변수들도 SQL에서 선언되어야 한다.
내장형 SQL의 논의에서 호스트 언어는 C로 가정한다.
변수 선언과 예외
SQL 문은 호스트 프로그램에서 정의된 변수들을 참조할 수 있다. 이러한 호스트 언어 변수들은 SQL 문에서 변수 이름 앞에 클론(:)을 붙여야 하며 EXEC SQL BEGIN DECLARE SECTION과 EXEC SQL END DECLARE SECTION 명령 사이에 선언되어야 한다. 예를 들어 다음과 같이 선언할 수 있다.
EXEC SQL BEGIN DECLARE SECTION
char c_sname[20];
long c_sid;
short c_rating;
float c_age;
EXEC SQL END DECLARE SECTION
SQL 문을 실행할 때 오류조건이 발생한다면, SQL이 무엇이 틀렸는지 알릴 방법이 필요하다. SQL-92 표준은 오류를 알리기 위해 SQLCODE와 SQLSTATE라는 두 개의 특수 변수를 인식한다.
- SQLCODE
- 둘 중에 더 오래된 것이고 오류 조건이 발생할 때 어떤 음수를 반환하도록 정의되며, 이 때 특별한 음수가 무슨 오류를 나타내는지 하는 표시가 없다.
- SQLSTATE
- 일반적인 몇 가지 오류 조건을 가진 미리 정의된 값들과 관련이 있다.
SQLCODE에 관련된 C타입은 long이며 SQLSTATE에 관련된 C타입은 char[6], 즉 다섯 문자(with null 종료)의 문자열이다.
SQL 문 내장하기
C에서 SQL 문은 앞에 EXEC SQL을 붙여야 한다.
간단한 예로서, 다음의 내장형 SQL문은 Sailors 릴레이션으로 한 행을 삽입하며, 그것의 열 값들은 그곳에 포함된 호스트 언어 변수 값을 기반으로 한다.
EXEC SQL
INSERT INTO Sailors VALUES (:c_sname, :c_sid, :c_rating, :c_age);
커서
C 같은 호스트 언어에 SQL 문을 내장함에 있어 가장 중요한 문제점은 C같은 언어가 레코드 집합 추상화를 분명히 지원하지 못하는데 반하여, SQL은 레코드 집합에 대해 동작하기 때문에 임피던스 부조화가 발생한다는 것이다. 해결책은 릴레이션으로부터 한 번에 한 행씩 가져오도록 허용하는 메카니즘인 커서(curor)를 제공하는 것이다.
어떤 릴레이션마다 혹은 어떤 SQL 질의마다 하나의 커서를 선언할 수 있다. 일단 커서가 선언되면, 그것을 개방(open)할 수 있고, 다음 행을 인출(fetch)하고, 커서를 이동(move)하며, 그 커서를 폐쇠(close)한다.
기본 커서 정의 및 사용
호스트 변수 c_sid에 한 값을 배정함으로써 표시된 뱃사람의 이름과 나이를 구해보자.
EXEC SQL SELECT S.sname, S.age
INTO :c_sname, :c_age
FROM Sailors S
WHERE S.sid = :c_sid;
INTO 절은 단일 답 행의 열 값들을 배정하도록 하므로 커서가 필요 없다. 만약 호스트 변수 c_minrating의 현재 값보다 높은 등급을 가진 모든 뱃사람들의 이름과 나이를 계산하기 위한 다음 질의를 보자.
EXEC SQL DECLARE sinfo CURSOR FOR
SELECT S.sname, S.age
FROM Sailors S
WHERE S.rating > :c_minrating;
위 질의에서 INTO 절은 여러 행들을 취급해야 하기 때문에 부적절하므로 커서를 사용했다. 이 코드는 일단 실행되면 커서 sinfo가 정의된다. 계속해서 그 커서를 다음과 같이 개방할 수 있다.
OPEN sinfo;
그 커서와 연관된 SQL 질의에서 c_minrating의 값은 그 커서를 개방할 때의 이 변수 값이다.
커서가 개방될 때, 그것은 첫 행 앞을 가리킨다. 호스트 언어 변수로 커서 sinfo의 첫 행을 읽기 위해 FETCH 명령을 사용할 수 있다.
FETCH sinfo INTO :c_sname, :c_age;
FECTH 문이 수행될 때, 커서는 다음 행 지점에 높이게 되고 그 행의 열 값들이 대응되는 호스트 변수들로 복사된다. 이 FECTH문을 반복 실행하면, 질의에 의해 계산된 모든 행들을 한 번에 한 행씩 읽을 수 있다. FETCH 문이 마지막 행 다음에 커서를 위치시키면, SQLSTATE는 더 이상 행이 없다는 것을 표시하기 위해, NO DATA를 나타내는 값 02000이 설정된다.
커서를 다 사용했을 때, 그것을 폐쇠할 수 있다.
CLOSE sinfo;
커서의 성질
커서 선언의 일반형은 다음과 같다.
DECLARE cursorname [INSENSITIVE] [SCROLL] CURSOR
[WITH HOLD]
FOR some query
[ORDER BY order-item-list]
[FOR READ ONLY | FOR UPDATE]
커서는 읽기 전용 커서(read only cursor)로 선언될 수도 있고 (FOR READ ONLY), 그것이 기반 릴레이션이나 갱신 가능 뷰에 대한 커서라면 갱신 가능 커서(updatable cursor)로 선언될 수도 있다(FOR UPDATE).
UPDATE나 DELETE 명령의 간단한 변화는 그 커서가 가리키는 행을 갱신하거나 삭제할 수 있다. 예를 들면, sinfo가 갱신 가능 커서이고 개방되어 있다면, 다음 문장을 수행할 수 있다.
UPDATE Sailors S
SET S.rating = S.rating -1
WHERE CURRENT of sinfo;
마찬가지로, 다음 문장을 수행함으로서 이 행을 삭제할 수 있다.
DELETE Sailors S
WHERE CURRNET of sinfo;
만약 키워드 SCROLL이 표시되면, 커서는 스크롤 가능(scrollable)이 되는데, 그것은 FETCH 명령의 변형이 매우 유연한 방법으로 커서를 위치시키기 위해서 사용될 수 있다는 것을 의미한다.
동적 SQL
DBMS로부터 데이터를 접근할 필요가 있는 스프레드시트나 그래픽적 전위와 같은 응용을 생각해 보자. 이러한 응용은 사용자로부터 명령을 받고, 사용자가 필요한 것에 맞추며, 필요한 데이터를 검색하기 위해 적절한 SQL문을 만들어야 한다. 이러한 상황에서, 비록 사용자의 명령이 제기되면 그 응용이 필요한 SQL 문을 구성해 주는 어떤 알고리즘이 있을 지라도, 무슨 SQL 문이 실행될 필요가 있는지 미리 예측할 수 없을지도 모른다.
SQL은 이러한 상황을 취급하기 위해 몇 가지 기능들을 제공하는데 이를 동적 SQL(Dynamic SQL)이라 부른다. 두 가지 주요 명령, PREPARE과 EXECUTE를 간단한 예를 통해 알아보자.
char c_sqlstring[] = {"DELETE FROM Sailors WHERE rating>5"};
EXEC SQL PREPARE readytogo FROM :c_sqlstring;
EXEC SQL EXECUTE readytogo;
첫 번째 문장은 C변수 c_sqlstring을 선언하고 그 값을 한 SQL 명령의 문자열 표현으로 초기화 한다. 두 번째 문장은 이 문자열이 SQL 명령으로서 파싱되고 컴파일되며, 그 실행 가능한 경과는 SQL 변수 readytogo로 바인드된다. 세 번째 문장은 이 명령을 실행한다.
많은 상황들이 동적 SQL의 사용을 필요로 한다. 그러나, 동적 SQL 명령의 준비는 실행 시간에 발생하고 실행 시간에 부하가 됨을 주의하자. 대화형이나 내장형 SQL 명령은 컴파일 시간에 한 번만 준비될 수 있고 원하는 대로 몇 번이든 재실행될 수 있다. 따라서 동적 SQL의 사용을 중요한 상황으로 제한해야 한다.
JDBC 소개
ODBC(Open DataBase Connectivity)와 JDBC(Java DataBase Connectivity)는 SQL과 범용 프로그래밍 언어를 통합할 수 있다. ODBC와 JDBC 모두 응용 프로그래밍 인터페이스(application programming interface:API)를 통해 응용 프로그래머에게 표준화된 방식으로 데이터베이스 특성들을 드러내 놓는다. 내장형 SQL과 대조적으로, ODBC나 JDBC는 재컴파일을 하지 않고도 다른 DBMS들을 접근하기 위한 단일 실행을 허용한다. 이와 같이, 내장형 SQL은 소스 코드 수준에서만 DBMS-독립(independent)이지만, ODBC나 JDBC를 사용한 응용들은 소스 코드 수준과 실행 수준에서 모두 DBMS-독립이다. 그뿐만 아니라, ODBC나 JDBC를 사용하면, 응용은 단 하나의 DBMS가 아니라 동시에 여러 개의 다른 DBMS에 접근할 수도 있다.
ODBC나 JDBC는 간접적 추가 단계를 소개함으로써 실행 수준의 호환성을 이룬다. 어느 특정 DBMS와의 모든 직접적인 상호 작용은 DBMS-전용 드라이버(driver)를 통하여 발생한다. 드라이버는 ODBC나 JDBC 호출을 DBMS-전용 호출로 변환해 주는 소프트웨어 프로그램이다. 응용이 접근할 DBMS들은 실행 시간에만 알려지므로 드라이버들은 요구에 의해 동적으로 적재된다. 사용 가능한 드라이버들은 드라이버 관리기(driver manager)에 등록된다.
ODBC나 JDBD를 통해 한 데이터 소스와 상호작용하는 응용은 데이터 소스를 하나 선택하고, 그에 해당하는 드라이버를 동적으로 적재하며, 그리고 그 데이터 소스에 연결을 설치한다. 연결을 개방하는 수에는 제한이 없으며, 한 응용이 다른 데이터 소스들에 여러 개의 연결을 개방할 수 있다.
아키텍처
JDBC의 아키텍처는 네 가지의 주 구성 요소를 가진다.
- 응용(Application)
- 데이터 소스와의 연결을 초기화하고 종료한다.
- 트랜잭션 경계를 설정하고, SQL문들을 제출하며, 결과들을 검색한다.
- 드라이버 관리기(Driver manager)
- JDBC 드라이버들을 적재하고 응용으로부터 알맞은 드라이버로 JDBC 함수 호출을 전달하는 것을 목표로 한다.
- JDBC 초기화와 응용으로부터의 정보 호출을 취급하고 모든 함수 호출들을 기록할 수도 있다.
- 약간의 기본적인 오류 검사도 수행한다.
- 다수의 데이터 소스 전용 드라이버(Driver)
- 해당 데이터 소스와의 연결을 설정한다.
- 요청을 제출하고 요청 결과를 되돌려 받을 뿐 아니라, 해당 데이터 소스 특유의 형식으로부터의 데이터, 오류 형태들, 오류 코드들을 JDBC 표준으로 변환해 준다.
- 데이터 소스(Data source)
- 드라이버로부터의 명령들을 처리하고 그 결과를 반환한다.
데이터 소스와 응용의 상대적인 위치에 따라, 여러 가지 구조적 시나리오가 가능하다. JDBC 드라이버들은 응용과 데이터 소스 사이의 구조적 관계에 따라 네 가지 타입으로 분류된다.
- 브리지(Bridge)
- JDBC 함수 호출을 DBMS 원래의 것이 아닌 다른 API의 함수 호출로 변환한다.
- 응용은 ODBC를 따르는 데이터 소스에 접근하기 위해 JDBC 호출을 사용할 수 있다.
- 응용을 기존의 설치 위에 두기 쉬우며, 어떠한 드라이버들도 새롭게 설치되지 않는다는 장점을 가진다.
- 단점
- 데이터 소스와 응용 사이에서 증가된 많은 수의 계층은 성능에 영향을 미친다.
- 사용자는 ODBC 드라이버를 지원하는 함수적 성질에 제한된다.
- Not good for the web
- 비-Java 드라이버를 통한 고유의 API로 직접 변환
- JDBC 함수 호출을 특정 데이터 소스의 API에 대한 메소드 시행으로 직접 변환한다.
- 브리지보다 더 좋은 성능을 가진다.
- API를 구현하는 데이터베이스 드라이버가 응용을 실행하는 각 컴퓨터에 설치될 필요가 있다.
- Not good for the Web
- 네트워크 브리지(Network bridge)
- 네트워크 상에서 JDBC 요청들을 DBMS-전용 메소드 시행으로 변환해 주는 미들웨어(middleware) 서버에 전송한다.
- 이 경우, 클라이언트 사이트상의 드라이버는 DBMS-전용이 아니다.
- 응용에 의해서 적재된 JDBC 드라이버는 매우 작을 수 있고, 구현할 필요가 있는 함수적인 것은 SQL 문을 미들웨어 서버에 전송하는 것뿐이다.
- Disadvantage: Need to maintain another server
- Java 드라이버를 통한 고유의 API로 직접 변환
- DBMS API를 직접 호출하는 대신에, 드라이버는 Java 소켓들을 통해 DBMS와 통신한다.
- 클라이언트 측의 드라이버는 Java로 작성되나, DMBS-전용이 된다. JDBC 호출을 데이터베이스 시스템 고유의 API로 변환한다.
- 중간층을 필요로 하지 않으며, 모든 구현이 Java로 이루어지므로, 성능이 매우 좋다.
- Disadvantage: Need a different driver for each database
JDBC 클래스와 인터페이스
JDBC는 Java 언어로 작성된 프로그램으로부터 데이터베이스를 접근할 수 있도록 해주는 Java 클래스 및 인터페이스들의 모임이다. JDBC는 원격 데이터 소스에 연결하고, SQL 문을 실행하며, SQL문으로부터 결과 집합을 조사하고, 트랜잭션 관리와 예외 처리(exception handling)를 하기 위한 메소드들을 포함한다. 이 클래스와 인터페이스들은 java.sql 패키지의 부분이다.
Steps to submit a database query
- Load the JDBC driver
- Connect to the data source
- Excute SQL statements
JDBC 드라이버 관리
JDBD에서, 데이터 소스 드라이버들은 Drivermanager 클래스에 의해 관리되는데, 현재 적재된 모든 드라이버들의 리스트를 유지한다. Drivermanager 클래스는 동적으로 드라이버들을 추가하거나 삭제할 수 있도록 하기 위해 registerDriver, deregisterDriver, getDrivers라는 메소드들을 가진다.
JDBC 드라이버를 데이터 소스와 연결하는 단계는 다음과 같다.
- 관련된 JDBC 드라이버를 적재한다.
- 클래스들을 동적으로 적재하기 위한 Java 메카니즘을 사용함으로서 달성된다.
- 다음과 같이 JDBC 드라이버를 명시적으로 적재한다.
- Class.forName(“oracle/jdbc.driver.OracleDriver”);
- Java 응용을 시작할 때 명령 줄에서 다음을 포함한다.
- -Djdbc.drivers=oracle/jdbc.driver
연결
데이터 소스를 가진 세션은 Connection 객체의 생성을 통하여 시작된다. 연결은 데이터 소스를 가진 논리적 세션을 식별한다. 연결들은 JDBC URL을 통해서 표시되며, 그 URL은 jdbc 프로토콜을 사용한다. URL은 다음 형태를 가진다.
다음과 같은 코드는 문자열 userId와 password가 정당한 값으로 설정된다는 가정 하에 Oracle 데이터베이스로 연결이 이루어진다.
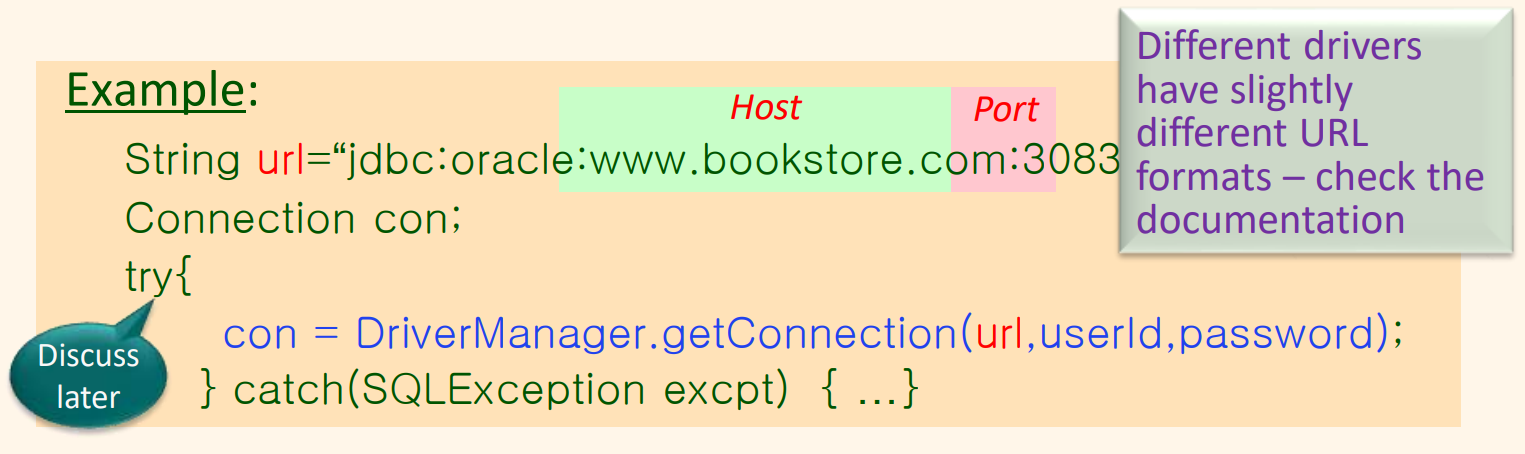
SQL문 실행
JDBC는 세 가지 방법의 실행문들을 지원한다.
- Statement
- 다른 두 문장 클래스들에 대한 기반 클래스이다.
- 정적 혹은 동적으로 생성된 SQL 질의로서 데이터 소스에 질의하는 것을 허용한다.
- PreparedStatement
- 여러 번 사용될 수 있는 미리 컴파일된 SQL 문들을 동적으로 생성한다.
- SQL 문들은 매개변수들을 가질 수 있으나, 구조는 PreparedStatement 객체가 생성될 때 고정된다.
- CallableStatement
- 저장 프로시저
PreparedStatement 객체를 사용하는 견본 코드를 살펴본다.
String sql = "INSERT INTO Books VALUES(?, ?, ?, 0, ?, ?)"; // ?: place holder, semi-static
PreparedStatement pstmt = con.prepareStatement(sql);
pstmt.clearParameters();
pstmt.setInt(1, sid);
pstmt.setString(2, sname);
pstmt.setInt(3, rating);
pstmt.setFloat(4, age);
int numRows = pstmt.executeUpdate();
SQL 질의는 질의 문자열을 표시하나, 매개변수들의 값들에 대해서는 “?”를 사용하고, 나중에 메소드 setInt, setString, setFloat 들을 사용하여 설정한다. 이전 값들을 제거하기 위하여 매개변수 값들을 설정하기 전에 clearParameter()를 항상 사용하는 것이 좋은 형식이다.
데이터 소스로 질의 문자열을 제출하는 방법이 있다. 위 코드에서 SQL문이 어떠한 레코드들도 반환하지 않는다는 것을 알 때 사용되는 executeUpdate 명령을 사용했다. executeUpdate 메소드는 그 SQL문이 수정한 행들의 수를 나타내는 정수를 반환한다. 어떠한 행도 수정하지 않은 성공적 수행에 대해서는 0을 반환한다.
ResultSet
문장 executeQuery는 커서와 유사한 ResultSet 객체를 반환한다. ResultSet 커서들은 전진, 후진 스크롤링과 위치 내 편집과 삽입을 허용한다.
가장 기본적인 형태에서, ResultSet 객체는 질의의 출력 중 한 번에 한 행을 읽도록 한다. 최초로, ResultSet은 첫 행의 앞에 위치하며, next() 메소드를 명시적으로 호출하여 첫 행을 검색한다. 질의 답에 더 이상 행이 없다면 next 메소드는 false를 반환하고, 그렇지 않으면 true를 반환한다.
String sqlQuery;
ResultSet rs=stmt.executeQuery(sqlQuery); // semi-static
// rs is now a cursor
while(rs.nest()){ // 원하는 데이터가 없을 때 false
// Process the data
}
common ResultSet Methods
- next(): 논리적으로 다음 행을 검색하기 위해 허용.
- previous(): 한 행 뒤로 이동한다.
- absolute(int num): 표시된 수에 대한 행으로 이동한다.
- relative(int num): 현재 위치에서 상대적으로 앞쪽 혹은 뒤쪽(num이 음수인 경우)으로 이동한다.
- relative(-1)은 previous와 같은 효과를 가진다.
- first(): 첫 행으로 이동한다.
- last(): 마지막 행으로 이동한다.
- getString(string columnName): 현재 행(row)에서 지정된 열(column)을 검색한다.
- getString(int columnName): 현재 행(row)에서 지정된 열(column)을 검색한다.
- getString(float columnName): 현재 행(row)에서 지정된 열(column)을 검색한다.
Java와 SQL 데이터 타입 부합
다음은 가장 일반적인 SQL 데이터 타입들에 대한 ResultSet 객체의 접근자 메소드(accessor method)를 보여준다.
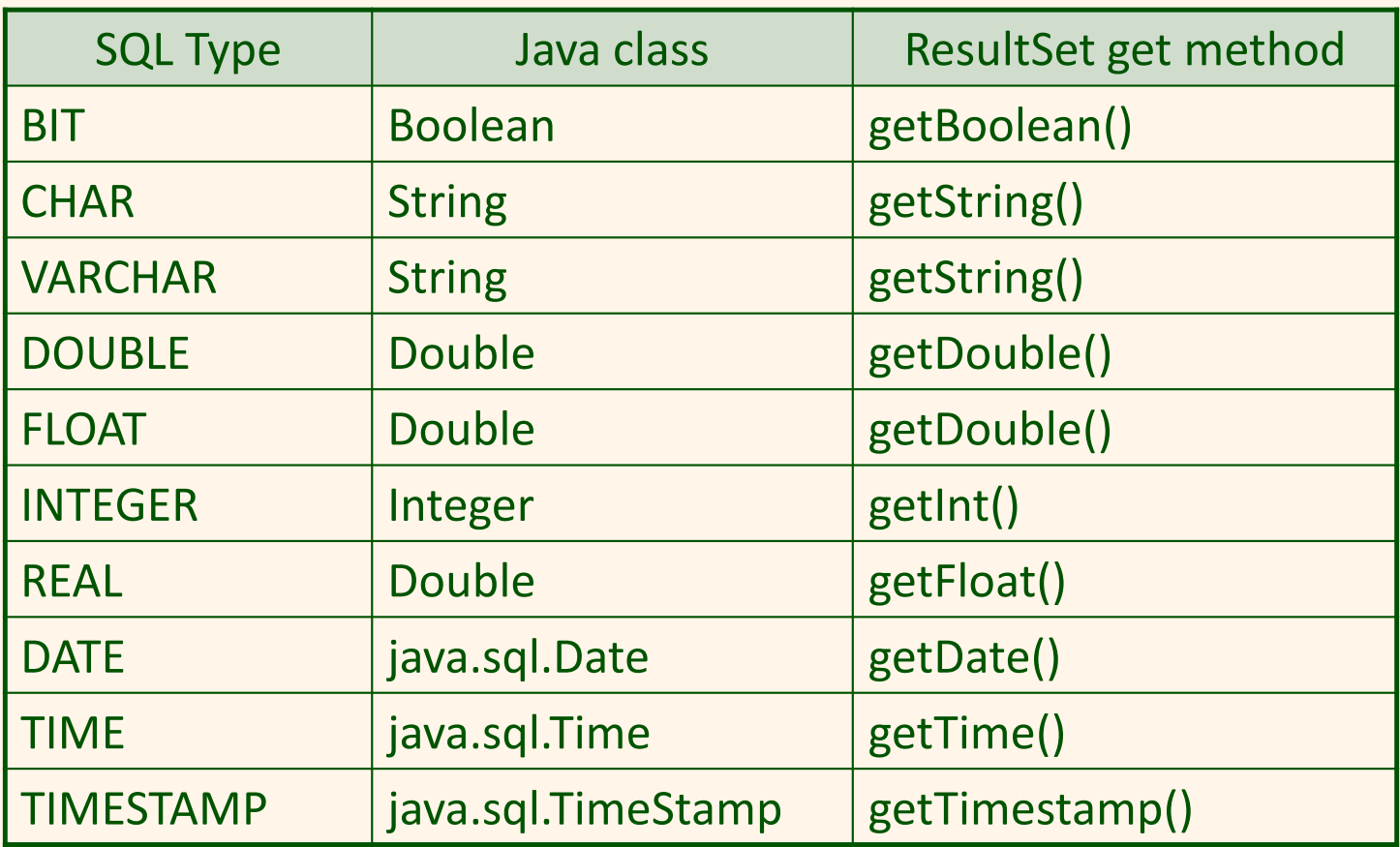
위 접근자 메소드를 가지고, ResultSet 객체에 의해 참조된 질의 결과의 현 행으로부터 값들을 검색할 수 있다. 각 접근자 메소드에 대해 두 가지 형태가 있다.
- 1로 시작한 열 인덱스에 의해 값들을 검색한다.
- 열 이름에 의해 값들을 검색한다.
SQL Data Types은 다음과 같다.
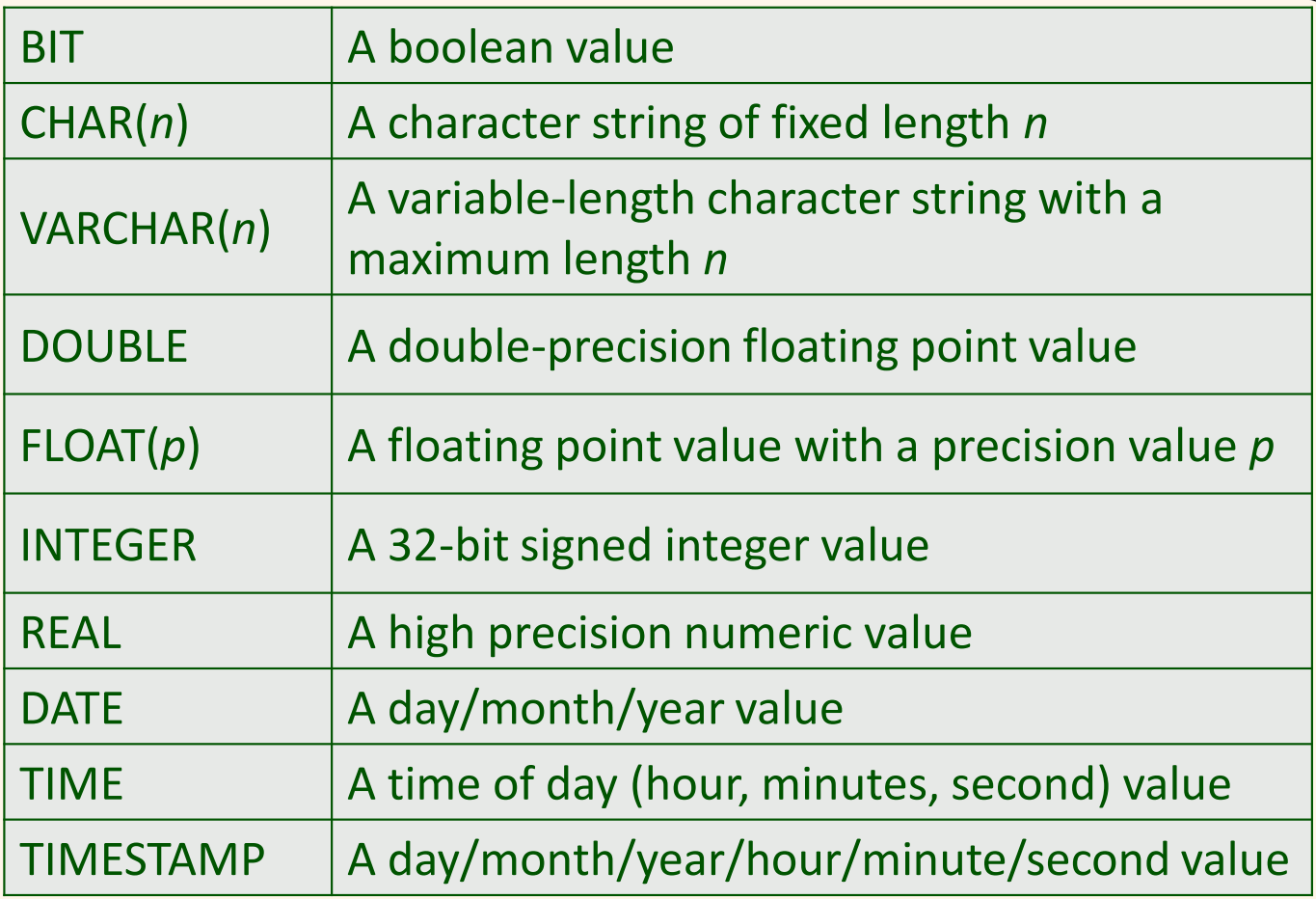
다음은 SQL 질의를 실행하는 다른 방법을 보여준다.
Statement stmt = con.createStatement(); // create an empty statement object
String query = "SELECT name, rating
FROM Sailors";
ResultSet rs = stmt.executeQuery(query); // The query can be dynamically created
예외와 경고
Java에서는 다음과 같이 예외처리를 한다.

SQLSTATE 변수와 유사하게, java.sql에서 대부분의 메소드들은 오류가 발생할 경우에 SQLException 타입의 예외를 내보낼 수 있다. 그 정보는 오류를 나타내는 문자열인 SQLState를 포함한다. Throwable로부터 상속된 표준 getMessage() 메소드 이외에, SQLException은 후속의 정보를 제공하는 두 부가적인 메소드들과, 다른 예외들을 얻기 위한 메소드를 갖는다.
- public String getSQLState(): SQL:1999 규격에 기초한 SQLState 식별자를 반환한다.
- public int getErrorCode(): 업체-전용(vendor-specific)의 오류 코드를 검색한다.
- public SQLException getNextException(): 현 SQLException 객체와 관련된 예외들의 체인에서 다음 예외를 얻는다.
예외처리는 다음과 같이 사용된다.

SQLWarning은 SQLException의 부 클래스이다. 경고들은 오류들처럼 심각하지 않으며 그 프로그램은 특별한 경고 처리 없이 항상 계속될 수 있다. 경고들은 다른 예외들처럼 내보내어지지 않으며, java.sql 문 주위의 try-catch 블럭의 부분처럼 잡혀지지 않는다. SQL 경고들을 검색할 수 있는 메소드는 getWarnings() 이다. getNextWarning()은 SQLwarning object에 연결된 경고를 검색한다. 경고들의 중복 검색은 clearWarnings()를 통하여 피할 수 있다. Statement 객체들은 다음 문장의 수행시 자동적으로 경고들을 깨끗이 치운다. ResultSet 객체들은 새로운 투플이 접근될 때마다 경고들을 깨끗이 치운다.
다음은 SQLWarning들을 얻기 위한 전형적인 코드는 다음과 같다.
try {
stmt = con.createStatement();
warning = con.getWarnings();
while( warning != null){
// handleSQLWarnings // code to process warning
warning = warning.getNextWarning(); // get next warning
}
con.clearWarnings();
stmt.executeUpdate(queryString);
warning = stmt.getWarnings();
while( warning != null){
// handleSQLWarnings // code to process warning
warning = warning.getNextWarning(); // get next warning
}
} // end try
catch( SQLException SQLe){
// code to handle exception
} // end catch
다른 예는 다음과 같다.

데이터베이스 메타 데이터 조사
데이터베이스 시스템 그 자체에 대한 정보뿐만 아니라 데이터베이스 목록으로부터의 정보를 얻기 위해 DatabaseMetaData 객체를 사용할 수 있다. 다음 코드 부분은 JDBC 드라이버의 이름과 드라이버 버전을 어떻게 얻는지를 보여준다.
DatabaseMetaData md = con.getMetaData();
System.out.printIn("Driver Information:");
System.out.printIn("Name:" + md.getDriverName()
+ "version:" + md.getDriverVersion());
DatabaseMetaData 객체는 더 많은 메소드들을 가진다.(134개) 다음은 몇 개의 메소드들을 나열한다.
- public ResultSet getCatalogs() throw SQLException: 모든 목록 릴레이션들에 대해 반복하기 위해 사용될 수 있는 ResultSet를 반환하다.
- 함수 getIndexInfo()와 getTables()가 비슷하게 동작한다.
- public int getMaxConnections() throw SQLException: 가능한 연결들의 최대 수를 반환한다.
-

다음은 데이터베이스 메타 데이터를 조사하는 예를 보여준다.
DatabaseMetaData md = con.getMetaData();
ResultSet tablesRS = md.getTables(null, null, null, null); // get all tables
String tableName;
While( tableRS.next()) {
tableName = tableRS.getString("TABLE_NAME"); // get TABLE_NAME field
// print out the attributes of this table
System.out.printIn("Table: " + tableName);
ResultSet columnsRS = md.getColumns(null, null, tableName, null);
while( columnsRS.next()) {
System.out.print(columnsRS.getString("COLUMN_NAME") + " ");
}
// print out the primary keys of this table
System.out.printIn("The key of table" + tableName + "are: ");
ResultSet keysRS = md.getPrimaryKeys(null, null, tableName);
while( keysRs.next()) {
System.out.print(keyRS.getString("COLUMN_NAME") + " ");
}
}
SQLJ
SQLJ는 정정 모델인 JDBC에서 질의들을 생성하는 동적 방법을 보환하기 위하여 개발되어 내장형 SQL과 매우 밀접하다. JDBC와는 달리 semi-static SQL 질의를 가지는 것은 컴파일러가 SQL 문법 점검, 각각의 SQL 애트리뷰트들과 호스트 변수들과의 일치성의 견고함 타입 점검, 컴파일 시에 모든 데이터베이스 스키마에 대한 질의의 일관성을 실행하도록 허용한다. 예를들어, SQLJ와 내장형 SQL은 호스트 언어의 변수들을 항상 같은 인수들에 정적으로 묶이고, JDBC에서는 각 변수를 인수에 묶고 그 결과를 검색하기 위하여 문장들을 분리할 필요가 있다.
다음 SQLJ문은 호스트 언어 변수들인 title, price, author를 커서 books의 반환 값들에 바인드한다.
#sql books = {
SELECT title, price INTO :title, :price // title is bound to :title
FROM Books WHERE author = :author
};
JDBC에서 호스트 언어 변수들이 질의 결과를 보유하는 것을 동적으로 결정할 수 있다. 다음 예에서, 만약 책이 Feynman에 이해 저술되었다면 책의 제목을 변수 ftitle로 읽으며, 그렇지 않으면 변수 otitle로 읽는다.
author = rs.getString(3); // get value of first attribute
if(author == "Feynman") {
ftitle = rs.getString(2);
}
else {
otitle = rs.getString(2);
}
SQLJ 응용을 작성할 때, 규칙들의 집합에 따라 정규 Java 코드와 내장 SQL 문들을 작성한다. SQLJ 응용들은 내장형 SQLJ 코드를 SQLJ Java 라이브러리로의 호출들로 바꾸어 주는 SQLJ 변환 프로그램을 통해 전처리된다. 수정된 프로그램 코드는 그런 후에 Java 컴파일러에 의해 컴파일 될 수 있다. 보통 SQLJ Java 라이브러리는 JDBC 드라이버로 호출하며, 이는 데이터베이스 시스템으로의 연결을 조절한다.
SQLJ나 JDBC는 표준에 집착하도록 강요하며, 결과 코드는 다른 데이터베이스 시스템간에 훨씬 더 휴대가 간편하다.
SQLJ 코드 작성
Int sid; String name; Int rating;
// declare the iterator class
#sql iterator Sailors(Int sid, String name, Int rating);
Sailors sailors; // instantiate(인스턴스 생성) an iterator object
// assume that the application sets rating
#sql sailors = {
SELECT sid, sname INTO :sid, :name
FROM Sailors WHERE rating = :rating
}; // initialize iterator
while (sailors.next()) {
// retrive rows from iterator object
System.out.printIn(sailors.sid + " " + sailors.sname);
}
sailors.close(); //close the iterator object
모든 SQLJ 문들은 특별한 접두어 #sql을 가진다. SQLJ에서, 기본적으로 커서인 반복자(iterator) 객체들을 가지고 SQL 질의의 결과들을 검색한다. 한 반복자는 반복자 클래스의 인스턴스이다. SQLJ에서 반복자 사용은 다섯 단계를 거친다.
- 반복자 클래스 선언
- #sql iterator Sailors(Int sid, String name, Int rating);
- 새로운 반복자 클래스로부터 반복자 객체 인스턴스화
- Sailors sailors;
- SQL 문을 사용한 반복자 초기화
- #sql sailors = {SELECT … FROM … WHERE …}
- 반복적으로, 반복자 객체로부터 행들을 읽음
- while (sailors.next()) { … }
- 반복자 객체 닫기
- sailors.close();
반복자 클래스의 두 가지 형태가 있다.
- 명칭 반복자(named iterator)
- 반복자 각 열이 다양한 타입과 명칭을 표시한다.
- 개별 열들을 검색하도록 한다.
- sailors.sid, sailors.sname
- 위치 반복자(positional iterator)
- 반복자의 각 열에 대한 변수 타입만 표시한다.
- 반복자의 개별 열들에 접근하기 위해, 내장형 SQL과 유사한 FETCH … INTO 구성을 사용한다.
-
#sql iterator Sailors(Int, String, Int); Sailors sailors; #sql sailors = {SELECT ... FROM ... WHERE ...}; // 위치 반복자 while(true) { #sql{FETCH :sailors INTO :sid, :name}; // fetch next sailor if(sailors.endFetch()) { break; } // exit loop if end of iterator // process the sailor }두 반복자 타입은 같은 성능을 가진다. 어떤 반복자를 사용하는가 하는 것은 프로그래머의 취향에 따른다.
저장 프로시저
저장 프로시저(stored procedure)는 데이터베이스 서버의 프로세스 공간에서 지역적으로 실행되고 완료될 수 있는 단일 SQL문을 통해 실행되는 프로그램이다. 그 결과는 하나의 큰 결과로 패키지화되고 응용으로 반환될 수 있거나, 혹은 그 응용 논리가 클라이언트로 어떠한 결과도 전송하지 않고 서버에서 직접 수행될 수 있다.
저장 프로시저들은 다음과 같은 장점을 가지고 있다.
- 한 저장 프로시저가 데이터베이스 서버에 등록되면, 다른 사용자들이 그 저장 프로시저를 재사용할 수 있다.
- SQL 질의 혹은 응용 논리를 작성하는 중복된 노력을 줄인다.
- 코드 유지 관리를 쉽게 만든다.
- 응용 프로그래머들은 모든 데이터베이스 접근을 저장 프로시저로 캡슐화한다면 데이터베이스 구조를 알 필요가 없다.
간단한 저장 프로시저 생성

저장 프로스저는 명칭을 가져야 한다. 이 저장 프로시저는 ‘showNumberOfOrders’라는 명칭을 가진다. 그렇지 않으면, 미리 컴파일 되고 서버에 저장된 SQL 문만 포함된다.
저장 프로시저들은 매개변수들을 가질 수 있다. 이 매개변수들은 유효한 SQL 타입이어야 하고, 세 개의 다른 형태 중 하나를 가진다.
- IN: 저장 프로시저 쪽으로의 인수이다.
- OUT: 저장 프로시저로부터 반환된다.
- 사용자가 처리할 수 있는 모든 OUT 매개변수에 값을 배정한다.
- INOUT: IN과 OUT 매개변수의 성질을 결합한다.
- 저장 프로시저로 전달되는 값들을 포함하며, 저장 프로시저는 변환 값으로서 그들의 값을 설정할 수 있다.
- 저장 프로시저는 완전한 타입 일치를 집행한다.
인수를 가진 저장 프로시저의 예는 다음과 같다.

위 코드에서 저장 프로시저는 sailor_sid, increase 두 인수를 가진다.
저장 프로시저는 SQL로 작성될 필요가 없다. 저장 프로시저는 임의의 호스트 언어로 작성될 수 있다. 다음 예에서 저장 프로시저는 클라이언트에 의해 호출될 때마다 데이터베이스 서버에 의해 동적으로 수행되는 Java 함수이다.

저장 프로시저 호출
저장 프로시저는 CALL 문장을 가진 대화형 SQL에서 호출될 수 있다.
CALL storedProcedureName(argument1, argument2, ..., argumentN);
내장형 SQL에서, 저장 프로시저의 인수들은 호스트 언어의 보통 변수들이다. 다음 예에서 IncreaseRating은 다음과 같이 호출된다.

JDBC와 SQLJ로부터 저장 프로시저 호출
CallableStatement 클래스를 사용하여 JDBC로부터 저장 프로시저를 호출할 수 있다.

SQLJ에서 다음과 같이 저장 프로시저 ShowSailors가 호출되었다.

댓글남기기