7장 인터넷 응용
Updated:
인터넷 개념
URI(균등 자원 식별자)
URI(Uniform Resource Identifiers)는 인터넷 상의 자원들을 유일하게 식별하기 위한 문자열이다. 자원(resource)은 URI에 의해 식별될 수 있는 정보의 일종이다. 자원의 가장 일반적인 종류는 정적 파일(HTML 문서와 같은)이나, 동적-생성된 HTML 파일, 영화, 프로그램의 출력 등이다.
URI는 세 부분을 가진다.
- 자원을 접근하기 위해 사용된 프로토콜의 이름
- 그 자원이 위치한 호스트 컴퓨터
- 그 호스트 컴퓨터상에서 자원 자체의 경로명
URI의 일반적인 명칭 부여방식 URL(Uniform Resource Locator)은 URI와 구별은 중요하지 않다.
HTTP(하이퍼텍스트 전송 프로토콜)
통신 프로토콜(communication protocol)은 각자의 메시지를 이해할 수 있도록 하기 위하여 통신하는 두 당사자들 사이의 메시지 구조를 정의하는 표준들의 집합이다. HTTP(Hypertext Transfer Protocol)는 인터넷 상에서 사용되는 가장 일반적인 통신 프로토콜이다. HTTP는 한 클라이언트(통상적으로 웹 브라우저)가 HTTP 서버에서 요구를 보내고, 서버는 그 클라이언트에게 응답을 보내는 클라이언트-서버 프로토콜이다. 사용자가 웹페이지를 요구하면(예, 하이퍼링크 클릭), 브라우저는 서버에게 그 페이지내의 객체들에 대한 HTTP 요구 메시지를 보낸다. 그 서버는 요구를 받아서 객체들을 포함하는 HTTP 응답 메시지를 가지고 응답한다. HTTP가 단지 파일들만이 아닌 모든 종류의 자원들을 전송하기 위해 사용되나, 오늘날 인터넷상의 거의 모든 자원들은 정적 파일들 혹은 서버측 스트립트들로부터 파일출력이라는 것을 인정하는 것은 중요하다.
예를들어, 사용자가 링크를 클릭한다면 HTTP 요구 메시지의 구조를 설명하고, HTTP 응답 메시지의 구조를 설명한다.
HTTP 요구
HTTP 요구의 일반적인 구조는 끝에 빈줄을 가진 몇 줄의 ASCII 본문으로 이루어진다.

첫 줄(요구 줄)은 세 필드를 가진다(HTTP 메소드 필드, URI 필드, HTTP 버전 필드). 메소드 필드는 GET과 POST 값을 가질 수 있다. 버전 필드는 HTTP 버전이 클라이언트에 의해 사용되며 프로토콜의 미래 확장을 위해 사용될 수 있음을 표시한다. User agent는 클라이언트에 타입을 표시한다(예, Netscape, Internet Explorer 버전). Accept를 가지고 시작하는 세 번째 줄은 클라이언트가 받아들이기를 원하는 파일 타입을 표시한다.
HTTP 응답
서버는 HTTP 응답 메시지를 가지고 응답한다. index.html 페이지를 검색하고, HTTP 응답 메시지를 만들기 위하여 페이지를 사용하며, 클라이언트에게 그 메시지를 전송한다.
HTTP/1.1 200 OK
Date: Mon, 04 Mar 2002 12:00:00 GMT
Content-Length:1024
Content-Type: text/html
Last-Modified: Mon, 22 Jun 1998 09:23:24 GMT
<HTML>
<HEAD>
</HEAD>
<H1>Barns and Nobble Internet Bookstore</H1>
Our investory:
<H3>Science</H3>
<B>The Character of Physical Law</B>
...
HTTP 응답은 세 부분을 가진다.
- 상태 줄
- 상태 줄은 HTTP 버전, 상태 코드, 관리 서버 메시지, 세 필드를 가진다.
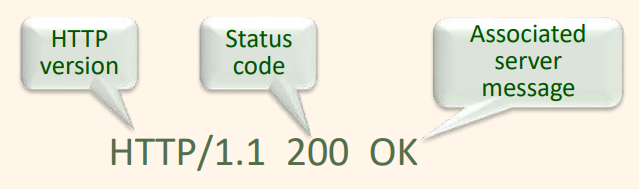
- 200 OK: 요구가 성공했고 객체가 응답 메시지의 본문에 포함된다.
- 404 Bad Request: 요구가 서버에 의해 만족될 수 없다는 것을 표시하는 일반적인 에러 코드.
- 404 Not Found: 요구된 객체가 서버에 존재하지 않는다.
- 505 HTTP Version Not Supported: 클라이언트가 사용하는 HTTP 프로토콜 버전이 서버에 의해 지원되지 않는다.
- 여러 표제 줄(header lines)
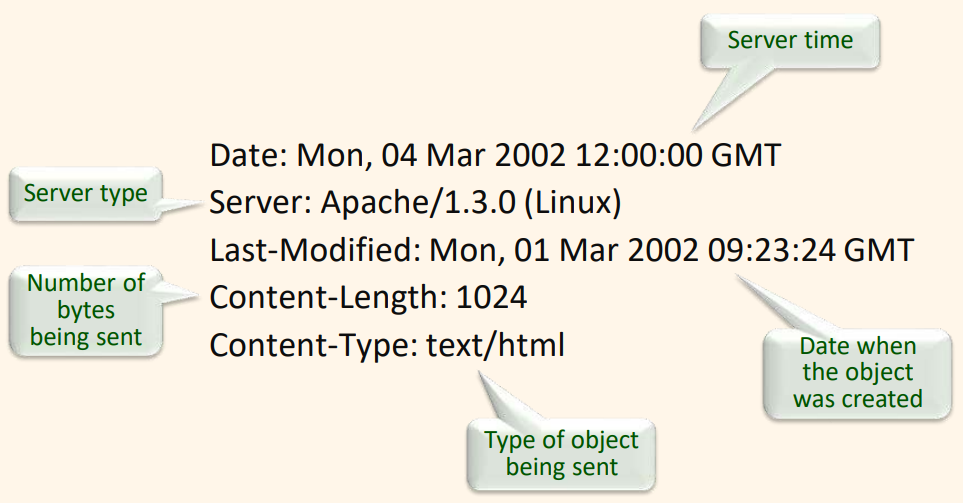
- Date 표제 줄은 HTTP 응답이 생성되었을 때의 시간과 날짜를 표시한다.
- Last-Modified 표제 줄은 객체가 생성되었을 때 나타낸다.
- Content-Length 표제 줄은 마지막 표제 줄 다음에 전송되는 객체의 바이트 수를 나타낸다.
- Content-Type 표제 줄은 개체 본문의 객체가 HTML 문서임을 나타낸다.
- 메시지 본문(클라이언트가 요구한 실제 객체를 포함한다)
클라이언트(웹 브라우저)는 응답 메시지를 받아서, HTML 파일을 추출하고, 그것을 파싱하며, 그리고 화면에 표시한다. 처리 중에, 파일에서 추가로 URI들을 발견할 수도 있는데, 그것은 매번 새로운 접속을 시도하는 이들 각 자원들을 검색하기 위하여 HTTP 프로토콜을 사용한다.
가장 중요한 논점은 HTTP 프로토콜이 무상태 프로토콜(stateless protocol)이라는 것이다. 모든 메시지(클라이언트로부터 HTTP 서버까지 혹은 그 역방향)는 자급자족(self-contained)이며 요구를 수립한 접속은 응답 메시지가 전송될 때까지만 유지된다. 프로토콜은 클라이언트와 서버 사이에서 앞의 상호작용을 자동적으로 ‘기억’하는 메카니즘을 제공하지 않는다.
HTTP 프로토콜의 무상태 특성은 어떻게 인터넷 응용들이 작성되었는지에 관한 중요한 영향력을 가진다. 서점 응용 예제와 상호작용하는 사용자를 살펴보자. 그 서점은 사용자들이 사이트에 로그인하는 것을 허용하며, 그리고나서 책 주문 혹은 주소 변경과 같은 여러 동작들을 다시 로그인하지 않고 수행한다고 가정하자. 한 사용자가 로그인되었는지 아닌지를 유지하는지를 보자. HTTP는 무상태이므로, 프로토콜 단계에서 다른 상태로 변경시킬 수 없다. 대신에, 그 사용자(웹 브라우저)가 서버에 전송하는 모든 요구에 대해, 사용자 로그인 상태와 같은 응용에 의해 요구된 어떤 상태 정보를 기호화해야 한다. 선택적으로, 서버측 응용 코드는 이 상태 정보를 유지해야하며 요구당 근거를 찾아야 한다.(쿠키(Cookies) 등)
HTTP의 무상태성은 HTTP 프로토콜의 구현이 용이함과 응용 개발의 용이함 사이의 흥정이다. HTTP의 설계자들은 프로토콜 그 자체를 간단하게 유지하도록 선택하고, 객체들의 요구이외의 어떤 기능성을 HTTP 프로토콜 위의 응용 계층으로 지연시킨다.
HTML 문서
웹 데이터 형식에는 다음이 있다.

HTLM은 문서를 기술하기 위해 사용되는 간단한 언어이다. HTML은 웹 브라우저에 대해 특별한 의미를 가지는 ‘표시’를 가지고 정규 텍스트를 확장함으로서 동작하기 때무에 마트업 언어(markup language)라고도 불린다. 언어에서 명령들은 태그라 불리는 <TAG>와 </TAG>라는 형식의 시작 태그와 종료 태그로 각각 구성된다. 다음 HTML 언어를 살펴보자.
<HTML>
<HEAD>
</HEAD>
<BODY>
<H1>Barns and Nobble Internet Bookstore</H1>
Our inventory:
<H3>Science</H3>
<B>The Character of Physical Law</B>
<UL>
<LI>Author: Richard Feynman</LI>
<LI>Published 1980</LI>
<LI>Hardcover</LI>
</UL>
<H3>Fiction</H3>
<B>Waiting for the Mahatma</B>
<UL>
<LI>Author: R.K. Narayan</LI>
<LI>Published 1987</LI>
</UL>
<B>The English Teacher</B>
<UL>
<LI>Author: R.K Narayan<LI>
<LI>Published 1980<LI>
<LI>Paperback<LI>
<UL>
</BODY>
</HTML>
문서는 <HTML>과 <HTML> 태그들로 둘러싸여 있으며, 그것은 일종의 HTML 문서라는 표시이다. 문서의 나머지는 <BODY> </BODY>로 둘러싸인 책 세권에 대한 정보로 구성되어 있다. 각 책에 대한 데이터는 항목들이 LI태그로 표시된 무순서 리스트(UL)로 표현된다. HTML은 허용되는 태그들의 집합과 그 의미를 정의하고있다. 예를 들면, HTML은 태그 <TITLE>이 문서의 제목을 나타내는 유효한 태그라는 것을 표시한다. 다른 예를 들면, 태그 <UL>은 항상 무순서 리스트를 나타낸다.
오디오나 비디오, 그리고 프로그램들 조차도 HTML 문서들에 포함될 수 있어 이는 풍부한 멀티미디어 표현이다. HTML 문서가 쉽게 작성될 수 있고 또 인터넷 브라우저를 사용하여 접근하기도 쉽다는 것이 웹의 폭발적 성장을 더욱 촉진시켰다.
XML 문서
HTML이 디스플레이 목적을 위한 문서의 구조를 표시하는 데 사용될 수 있지만, 더 일반적인 응용을 위한 내용의 구조를 표현하기에는 부적합하다. HTML은 제품 규격 혹은 가격을 포함하는 복잡한 문서들의 교환에는 적합하지 못하다.
XML(Extensible Markup Language)은 HTML의 단점을 개선하기 위해 만든 마크업 언어이다. HTML에서처럼 태그는 의미가 언어에 의해 표시되는 고정된 집합인데 반해, XML은 사용자가 전송하고 싶은 어떠한 유형의 데이터나 문서를 구성하기 위해 사용될 수 있는 새로운 태그들의 모음을 사용자로 하여금 정의할 수 있도록 허용한다. 이전보다 데이터베이스 시스템을 웹 응용에 더 밀접하게 통합시킬 가능성을 가지게 되었다.

XML 소개
다음 예를 보자.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<BOOKLIST>
<BOOK genre="Science" format="Hardcover">
<AUTHOR>
<FIRSTNAME>Richard</FIRSTNAME>
<LASTNAME>Feynman</LASTNAME>
</AUTHOR>
<TITLE>The Character of Physical Law</TITLE>
<PUBLISHED>1980</PUBLISHED>
</BOOK>
<BOOK genre="Fiction">
<AUTHOR>
<FIRSTNAME>Charles</FIRSTNAME>
<LASTNAME>Dickens</LASTNAME>
</AUTHOR>
<TITLE>Oliver Twist</TITLE>
<PUBLISHED>2002</PUBLISHED>
</BOOK>
<BOOK genre="Fiction">
<AUTHOR>
<FIRSTNAME>Jane</FIRSTNAME>
<LASTNAME>Austen</LASTNAME>
</AUTHOR>
<TITLE>Pride and Prejudice</TITLE>
<PUBLISHED>1983</PUBLISHED>
</BOOK>
</BOOKLIST>
- 원소(Elements)
- 원소는 태그라고도 불리는 XML 문서의 기본적인 구성 블럭이다.
- 원소 ELM에 대한 내용의 시작은 <ELM>으로 표시되고, 시작 태그라 불리며 그 내용의 끝은 </ELM>으로 표시되는데 이것은 종료 태그라 불린다.
- XML 원소는 대 소문자를 구별한다.
- 원소들은 적당히 중첩되어야 한다.
- 애트리뷰트(Attributes)
- 원소는 그에 대한 추가적인 정보를 제공하는 설명용 애트리뷰트들을 가질 수 있다.
- 애트리뷰트 값들은 원소의 시작 태그 내에서 설정된다.
- ELM이 애트리뷰트 att를 가진 원소를 나타낸다고 하면 <ELM att=”value”>로 설정할 수 있다.
- 모든 애트리뷰트 값들은 인용부호로 둘러 싸여야 한다.
- Structure
- XML은 HTML과 비슷하다
- XML은 애트리뷰트와 데이터와 함께 원소라 불리는 user-defined tags의 계층이 있다.
- 데이터는 요소에 의헤 묘사되고, 요소는 애트리뷰트에 의해 묘사된다.
- <BOOK genre=”Science” format=”Hardcover”>…</BOOK>
- 개체 참조(Entity References)
- 개체들은 보통의 텍스트 부분 혹은 외부 파일의 내용에 대한 단축형이며, XML 문서에서 한 개체의 사용을 개체 참조라고 한다.
- 개체 참조가 문서 내에 나타나는 곳이면 어디라도, 그것은 모두 해당 텍스트 내용으로 대체된다.
- 개체 참조는 ‘&’로 시작하고 ‘;’으로 끝난다. XML의 미리 정의된 다섯 개의 개체는 XML에서 특수한 의미를 가진 문자의 위치 보유자이다.
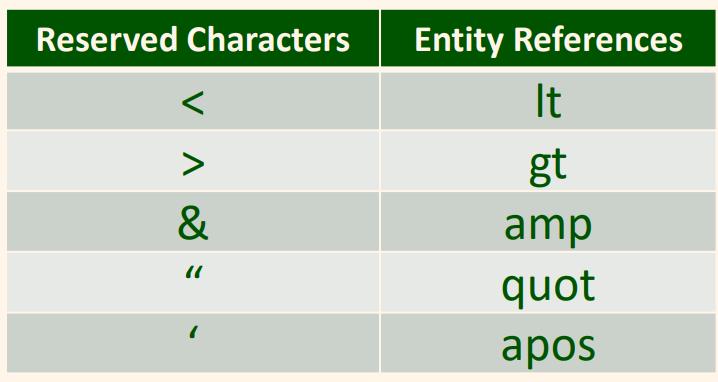
- 텍스트 ‘1<5’는 “& apos;1 & lt;5 & apos;”와 같이 부호화된다.
- 주석(Comments)
- XML 문서에서는 어디든지 주석을 넣을 수 있다.
- 주석은 <!-로 시작하고 ->로 끝난다.
- 주석은 문자열 –을 제외하고는 어떠한 텍스트도 포함할 수 있다.
- DTT(Document Type Declarations, 문서 타입 선언)
- XML에서 사용자 자신의 마크업 언어를 정의할 수 있다.
- DTD는 사용자 자신의 원소, 애트리뷰트, 개체들의 집합을 표시할 수 있도록 허용하는 규칙의 집합이다.
- DTD는 기본적으로 어떠한 태그들이 허용되는지, 어떠한 순서로 태그가 나타날 수 있는지, 어떻게 중첩될 수 있는지를 표시하는 문법이다.
XML-Storage
Storage is done just like an n-ary tree
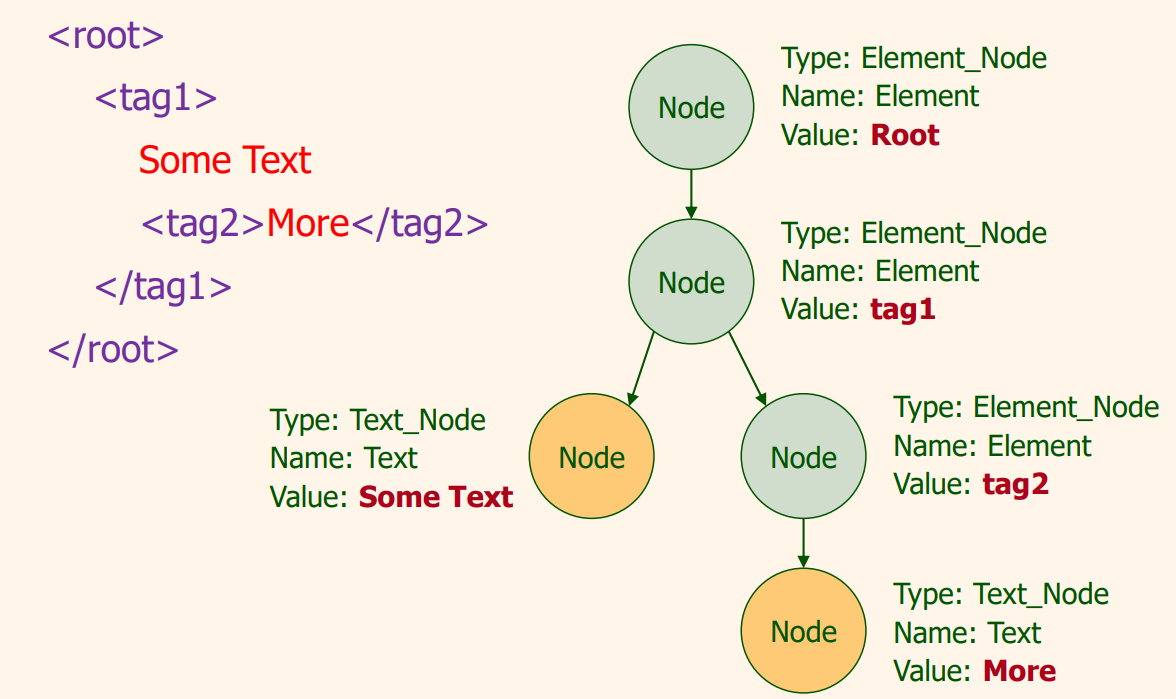
HTML vs XML

XML DTD
DTD는 사용자 자신의 원소, 애트리뷰트, 개체들의 집합을 표시할 수 있도록 허용하는 규칙의 집합이다. DTD는 어떠한 원소를 우리가 사용할 수 있으며 이들 원소에 대해 어떠한 제약조건들이 있는지를 표시한다. 만약 DTD가 문서와 관련 있으며 또 그 문서가 DTD의 규칙 집합에 따라 구조화되어 있다면 유효한(valid) 문서라고 한다. 다음 DTD의 예를 보자.
<!DOCTYPE BOOKLIST [
<!ELEMENT BOOKLIST (BOOK)*>
<!ELEMENT BOOK (AUTHOR,TITLE,PUBLISHED?)>
<!ELEMENT AUTHOR (FIRSTNAME,LASTNAME)>
<!ELEMENT FIRSTNAME (#PCDATA)>
<!ELEMENT LASTNAME (#PCDATA)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT PUBLISHED (#PCDATA)>
<!ATTLIST BOOK GENRE (Science|Fiction) #REQUIRED>
<!ATTLIST BOOK FORMAT (Paperback|Hardcover) “Paperback”>
]>
하나의 DTD는 <! DOCTYPE name [DTD선언]>로 둘러싸이는데, 여기에서 name은 가장 밖에서 둘러싸는 태그의 이름이고, DTD선언은 DTD 규칙들의 텍스트이다. DTD는 최외곽 원소(루트 원소)로 부터 시작하는데 위 예에서는 BOOKLIST이다.
<!ELEMENT BOOKLIST (BOOK)*>
이 규칙은 원소 BOOKLIST가 0개 이상의 BOOK 원소들로 구성된다는 것을 말해준다. BOOK 뒤의 *기호는 BOOKLIST 원소 안에 얼마나 많은 BOOK 원소가 나타날 수 있는지를 표시한다.
- *: 0회 이상의 존재
- +: 1회 이상의 존재
- ?: 0회나 1회 존재
다음 규칙을 보자.
<!ELEMENT BOOK (AUTHOR,TITLE,PUBLISHED?)>
이 규칙은 BOOK 원소가 AUTHOR 원소, TITLE 원소, 선택적인 PUBLISHED 원소를 포함한다는 의미이다. 원소의 0 혹은 1회 존재를 가짐으로 인해 정보가 선택적인 것으로 된다는 것을 표시하기 위해 ?를 사용하였다.
<!ELEMENT FIRSTNAME (#PCDATA)>
<!ELEMENT LASTNAME (#PCDATA)>
이 규칙에서 LASTNAME은 다른 원소들을 포함하지 않고, 실제 텍스트를 포함하는 원소이다. 다른 원소들만 포함하는 원소들은 원소 내용(element content)을 가진다고 말하고, #PCDATA도 포함하는 원소들은 혼합 내용(mixed content)을 가진다고 말한다. 일반적으로, 원소 타입 선언은 <!ELEMENT (content Type)>과 같은 구조를 가진다. 다섯 가지의 내용 타입이 가능하다.
- 다른 원소들
- #PCDATA: 문자 데이터를 표시한다.
- EMPTY: 원소가 내용을 가지지 않는다는 것을 표시한다. 내용을 가지지 않는 원소들은 종료 태그를 가질 필요가 없다.
- ANY: 어떠한 내용도 허용된다는 것을 표시한다. 이 내용은 그 원소내의 문서 구조를 모두 검사할 수 없게 되므로 가능한 피해야할 것이다.
- 앞의 네 가지 선택으로부터 구성되는 정규식
- exp1, exp2, exp3: An ordered list of regular expressions.
- exp*: An optional expression(zero or more occurrences).
- exp?: An optional expression (zero or one occurrences)
- exp+: A mandatory expression (one or more occurrences)
- exp1 | exp2: exp1 or exp2
원소의 애트리뷰트들은 그 원소 외부에서 선언된다. 다음 애트리뷰트 선언을 보자.
<!ATTLIST BOOK GENRE (Science|Fiction) #REQUIRED>
위 XML DTD 부분은 원소 BOOK의 한 애트리뷰트인 GENRE를 표시한다. 이 애트리뷰트는 Science,Fiction 두 값을 취할 수 있다. 애트리뷰트는 #REQUIRED를 표시함으로서 요구되므로 각 BOOK 원소는 GENRE 애트리뷰트가 시작 태그에 기술되어야 한다. DTD 애트리뷰트 선언의 일반적인 구조는 <!ATTLIST elementName (attName attType default)+>와 같다.
키워드 ATTLIST는 애트리뷰트 선언의 시작을 나타낸다. 문자열 elementName은 그 뒤에 나오는 애트리뷰트 정의에 해당하는 원소의 이름이다. 그 뒤에 나오는 것은 하나 이상의 애트리뷰트 선언이다. 각 애트리뷰트는 attName으로 표시되는 이르므 가지고, attType으로 표시되는 타입을 가진다. XML은 여러 가지 가능한 애트리뷰트에 대하 타입을 정의한다. 문자열 타입의 애트리뷰트는 어떠한 문자열도 값으로 취할 수 있다. 이와 같은 애트리뷰트는 타입 필드에 CDATA라고 설정함으로서 선언할 수 있다: <!ATTLIST BOOK edition CDATA “1”>
만약에 애트리뷰트가 나열형 타입을 가지면, 애트리뷰트를 선언시 가능한 모든 값들을 열거해 준다. 위 예에서 애트리뷰트 GENRE는 나열형 애트리뷰트 타입이다. 가능한 애트리뷰트 값으로는 Science와 Fiction이다.
애트리뷰트 선언의 마지막 부분은 디폴트 명세라 불리어 진다.
<!ATTLIST BOOK GENRE (Science|Fiction) #REQUIRED>
<!ATTLIST BOOK FORMAT (Paperback|Hardcover) “Paperback”>
#REQUIRED는 애트리뷰트가 필요하고 그와 관련된 원소가 XML 문서의 어딘가에 나타날 때에는 언제나 이 애트리뷰트에 대한 값이 반드시 표시되어야 한다는것을 표시한다. 문자열 “Paperback”으로 표시된 디폴트 명세는 이 애트리뷰트가 필수적인 것은 아니다. 관련 원소가 이 애트리뷰트에 대한 값을 설정해 주지 않은 채 나타날 때마다, 그 애트리뷰트는 자동적으로 ‘Paperback’이라는 값을 취한다. 예를 들면 다음과 같은 GENRE 애트리뷰트에 대한 디폴트 애트리뷰트 값으로 ‘Science’를 만들 수 있다.
<!ATTLIST BOOK GENRE (Science|Fiction) "Science">
DTD를 참조하는 XML문서는 다음과 같다.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<BOOKLIST>
<BOOK genre="Science" format="Hardcover">
<AUTHOR>
...
다음 예를 보자.
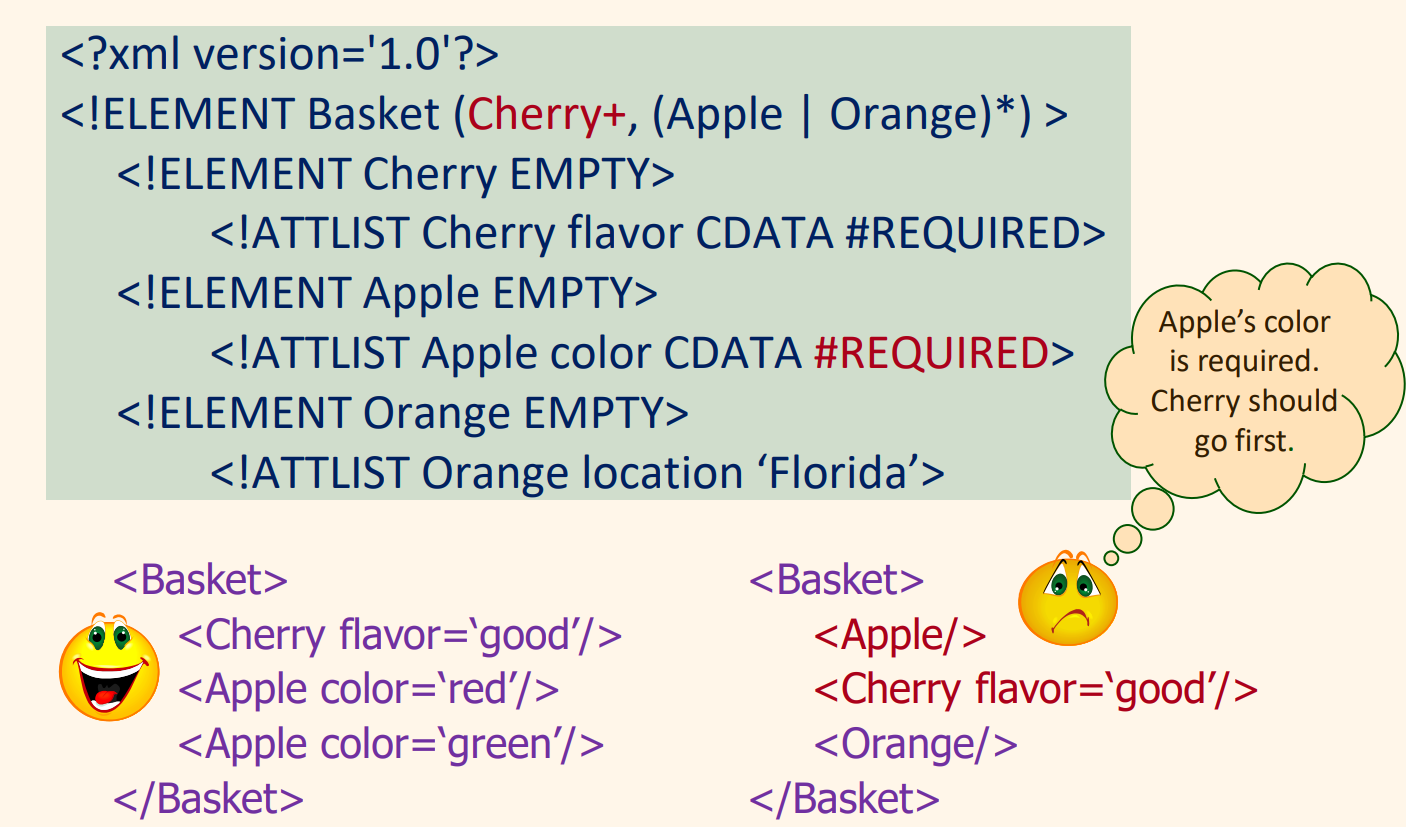

도메인-특화 DTD
최근 DTD는 몇 가지 특수한 도메인에 대하여 개발되고 있다. 예를들어 MathML(Mathematical Markup Language), Chemical Markup Language가 있다. 표준화된 DTD는 이질적인 소스들 사이에서 한결같은 데이터 교환을 할 수 있다. XML을 위한 Sophisticated(정교한) query language로 Xquery, XPath가 있다.
3-계층 응용 아키텍처
데이터 집약 인터넷 응용들은 세 가지 다른 기능적 구성 요소로 이해될 수 있다.
- 데이터 관리
- 응용 논리
- 표현
데이터 관리를 취급하는 구성 요소는 데이터 저장 구조를 위해 보통 DBMS를 사용하나, 응용 논리와 표현은 DBMS 자체보다는 더 많은 것을 포함한다.
단일-계층과 클라이언트-서버 아키텍처
처음에는, 데이터 집약 응용들이 다음과 같이 DBMS, 응용 논리, 사용자 인터페이스를 포함하는 단일-계층(Single-Tier Architectures)으로 결합되었다.
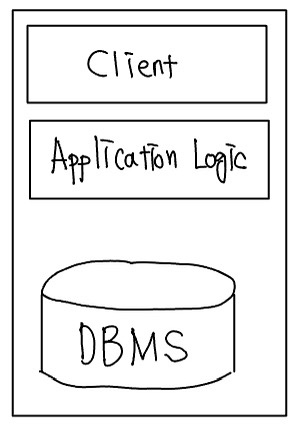
응용은 전형적으로 메인프레임에서 작동하고, 사용자는 단지 데이터 입력과 디스플레이만 수행할 수 있는 덤 터미널을 통하여 응용에 접근한다. 이 접근법은 중앙 관리자에의해 쉽게 유지되는 장점을가진다.
단일-계층 아키텍처는 중요한 문제점을 가진다. 사용자들은 단순한 덤 터미널 보다는 훨씬 더 많은 계산 능력을 요구하는 그래픽 인터페이스를 기대한다. 그래픽 디스플레이의 중앙 집중화된 계산 처리는 단일 서버가 할 수 있는 것보다 훨씬 더 많은 계산 능력을 요구한다.
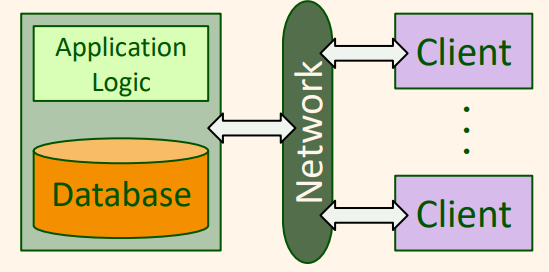
클라이언트-서버 아키텍처(Client-Server Architectures)라고도 불리는 2-계층 아키텍처는 잘 정의된 프로토콜을 통하여 서로 대화하는 한 클라이언트 컴퓨터와 한 서버 컴퓨터로 구성된다. 기능성의 어떤 부분을 클라이언트가 구현하며, 서버에 어떤 부분이 남아있는 지는 변할 수 없다. 전통적인 클라이언트-서버 아키텍처에서, 클라이언트는 단지 그래픽 사용자 인터페이스만 구현하고, 서버는 업무 논리와 데이터 관리의 두 부분을 구현한다. 이와 같은 클라이언트를 얇은 클라이언트(thin client)라고 부르고 이 아키텍처는 다음과 같다.
사용자 인터페이스와 업무 논리의 두 부분을 구현하는 더 강력한 클라이언트나, 혹은 사용자 인터페이스와 업무 논리의 일부분을 구현하는 클라이언트가 존재하고, 나머지 부분(데이터 관리)은 서버 단계에서 구현된다. 이와 같은 클라이언트를 굵은 클라이언트(thick client)라고 부르고 구조는 다음과 같다.
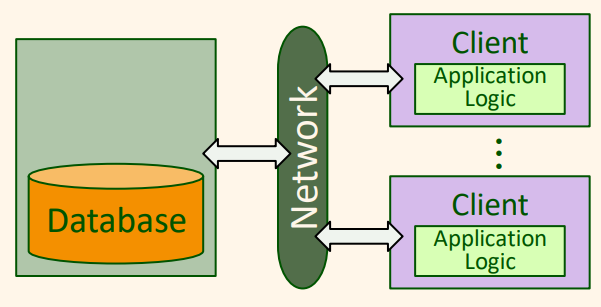
단일-계층 아키텍처와 비교해서, 2-계층 아키텍처들은 사용자 인터페이스를 데이터 관리계층으로부터 물리적으로 분리한다. 2-계층 아키텍처들은 구현하기 위해서, 클라이언트 측에 덤 터미널을 더 이상 가질 필요가 없다. 복잡한 표현 코드를 작동하는 컴퓨터들을 요구한다.
굵은-클라이언트 모델은 얇은-클라이언트 모델과 비교될 때 몇 가지 단점을 가진다.
- 응용 코드가 많은 클라이언트 사이트들에서 동작하므로, 업무 논리를 갱신하고 유지하기 위한 주된 위치가 없다.
- 많은 신뢰가 서버와 클라이언트들 사이에서 요구된다.
- DBMS는 데이터베이스를 일관된 상태로 유지하도록 신뢰해야 한다.
- 한 가지 해결 방법은 저장 프로시저를 통해서 접속하는 것이다.(Encapsulate all database access into stored procedures)
- 클라이언트의 수를 확장하지 못한다.
- 수백보다 많은 클라이언트를 처리할 수 없다.
- 큰 질의 결과들이 클라이언트와 서버사이에서 전송되지 못한다.
- 응용을 점점 더 데이터베이스 시스템에 접근하도록 확장하지 않는다.
- 서로 다른 x개의 데이터베이스 시스템들은 y개의 클라이언트들이 접근한다고 하면, 어느 시점에서 xy개의 다른 접속이 개방되어 해결할 수 없다.
3-계층 아키텍처
2-계층 아키텍처는 본래 응용의 나머지로부터 제기된 표현을 분리한다. 3-계층 아키텍처(Three-Tier Architecture)는 한 단계 더 나아가서, 데이터 관리로부터 응용 논리를 마찬가지로 분리한다.
- 표현 계층(Presentation tier)
- Primary interface to the user
- 사용자가 요구들을 제출할 수 있는 폼을 제공하고, 중간계층이 생성하는 응답들을 디스플레이한다.
- 다른 디스플레이 장비들과 양식들에 적응하기 쉽다.(PC, cell phone)
- 사용자는 요구를 만들고, 입력을 제공하고, 결과를 보기 위해서 자연적인 인터페이스를 필요로 한다.
- 인터넷의 광범위한 사용은 더욱 더 인기 있는 웹기반 인터페이스를 만들었다.
- 중간 계층(Middle tier)
- 응용의 업무 논리를 구현하는 코드를 가동한다.
- 한 동작이 실행될 수 있기 전에 어떤 데이터가 입력될 필요가 있는지를 제어하고, 다중 동작 단계들 사이의 제어 흐름을 결정하며, 데이터베이스 계층에 접근하는 것을 제어하고, 가끔 데이터베이스 질의 결과들로부터 동적으로 생성된 HTML 페이지들을 수집한다.
- 응용에 포함된 모든 다른 역할들을 지원할 책임이 있다.
- 기업급 응용은 복잡한 업무 처리를 반영하고, C++, Java와 같은 범용 언어로 작성된다.
- Access different data management systems
- 데이터 관리 계층(Data management tier)
- 데이터 집약 웹 응용들이 DBMS를 포함한다.
- One or more standard database management systems
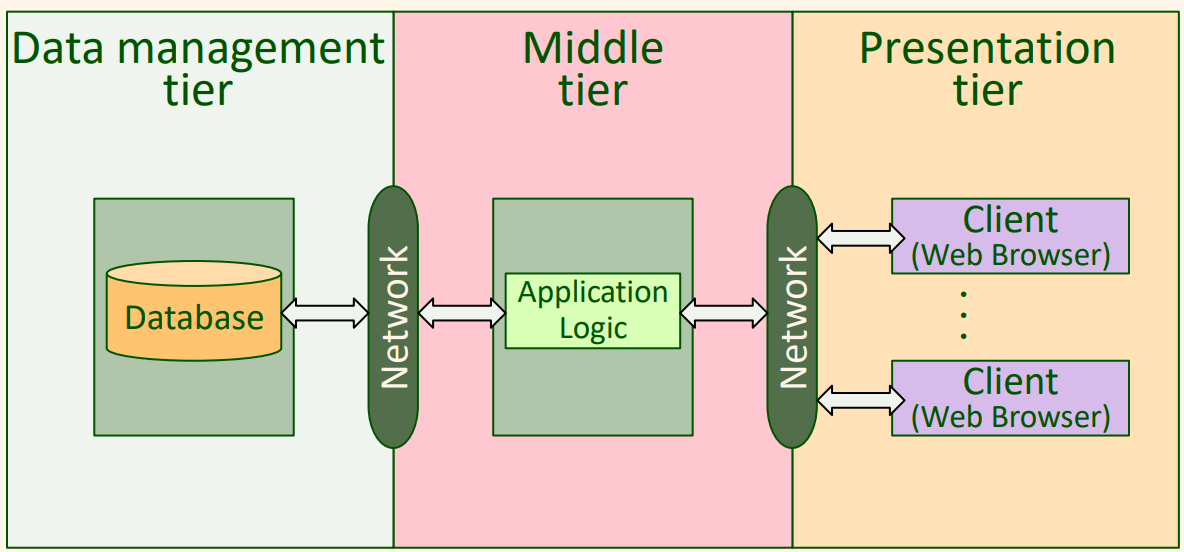
위는 기본적인 3-계층 아키텍처를 보여준다. 여러 가지 다른기술들이 여러 하드웨어 플랫폼과 여러 다른 물리적 사이트들을 웅용의 세 계층에 기여할 수 있도록 개발되었다. 다음 예를 보자.


다음은 3-계층에 대한 기술들을 보여준다.
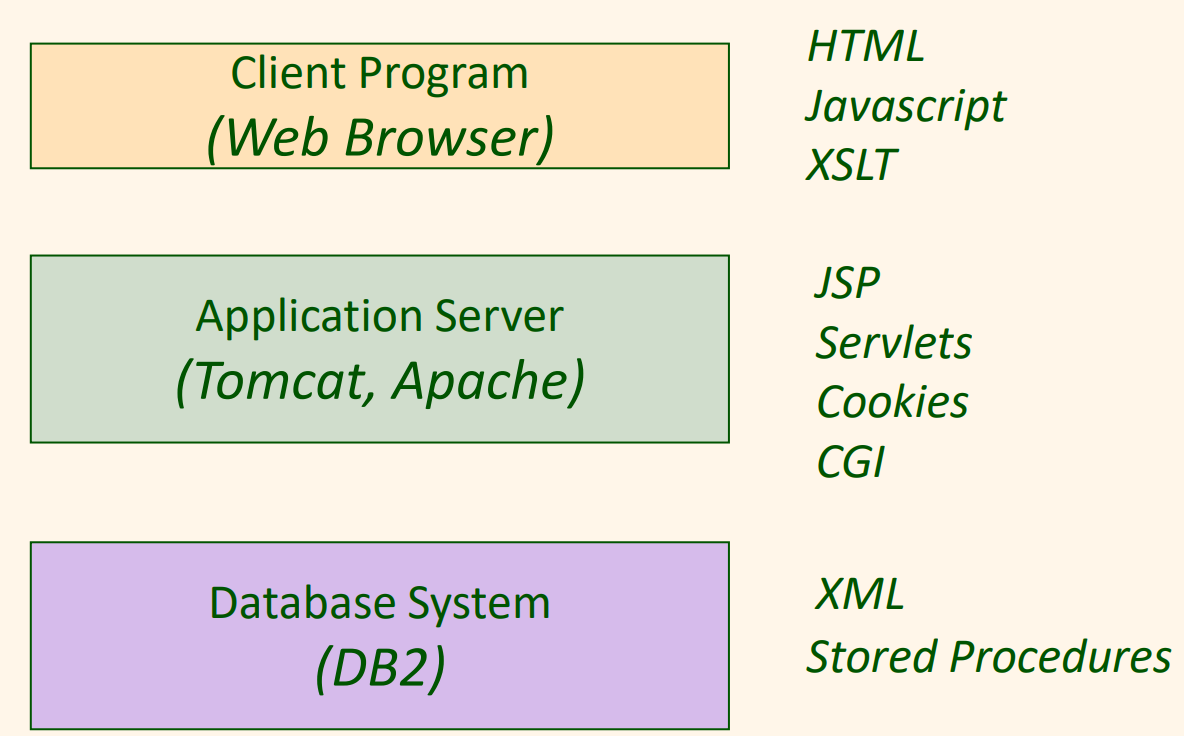
3-계층 아키텍처의 장점
3-계층 아키텍처는 다음의 장점들을 가진다.
- 이종 시스템(Heterogeneous systems)
- 다른 계층들에 영향을 주지 않고 어떤 계층에서 코드를 수정하거나 바꾸는 것이 쉽다.
- 얇은 클라이언트들(Thin clients)
- 클라이언트들은 오직 표현 계층에 대해서만 충분한 계산 능력이 필요하다. 일반적으로 클라이언트들은 웹 브라우저들이다.
- 통합된 데이터 접근(Integrated data access)
- 많은 응용에서 데이터는 여러 소스들로부터 접근되어야 한다.
- 모든 데이터베이스 시스템에 포함되는 접속을 중앙 관리할 수 있는 중간 계층에서 취급될 수 있다.
- 많은 클라이언트들로의 확장성(Scalability)
- 각 클라이언트는 경량급이고 그 시스템으로의 모든 접근은 중간 계층을 통한다.
- 중간 계층은 클라이언트들에 걸쳐 데이터베이스 접속들을 공유할 수 있고, 만약 중간 계층이 병목화되면 중간 계층코드를 실행하는 여러 서버들을 배치할 수 있다.
- 소프트웨어 개발 장점들(Software development)
- 업무 논리는 중앙 집중화되어 유지하고, 잘못을 고치고, 바꾸기 쉽다.
- 계층들 사이의 상호 작용은 잘 정의되고 표준화된 API들을 통해 발생한다.
표현 계층
클라이언트로부터 중간 계층으로(표현 계층으로부터 중간 계층으로) 인수들을 전송하는 HTML 폼, 클라이언트 계층에서 가벼운 계산을 위해 사용될 수 있는 자바 스트립트, 스타일 시트를 나타냄으로서 클라이언트 측 기술들을 알아본다. 스타일 시트들은 다른 표현 능력들을 가진 클라이언트들에 대해 다른 포매팅으로 같은 웹 페이지를 표현하는 것을 허용하는 언어들이다.
HTML 폼
HTML 폼들은 클라이언트 계층으로부터 중간 계층으로 데이터를 전달하는 공통의 방법이다. 폼의 일반적 양식은 다음과 같다.
<FORM ACTION=“page.jsp” METHOD=“GET” NAME=“LoginForm”>
...
</FORM>
단일 HTML 문서는 여러 개의 폼을 포함할 수 있다. HTML 폼 내에서는, 다른 FORM 원소를 제외하고 어떠한 HTML 태그들도 가질 수 있다.
FORM 태그는 세 가지 중요한 애트리뷰트를 가진다.
- ACTION
- 폼의 내용들이 제출되는 페이지의 URI를 표시한다.
- 만약 ACTION 애트리뷰트가 없으면, 현재 페이지의 URI가 사용된다.
- 위 폼에서, 폼 입력은 page.jsp라는 이름의 페이지로 제출될 것이고, 그 페이지는 폼으로부터의 입력을 처리하기 위한 논리를 제공할 것이다.
- METHOD
- HTTP/1.0 메소드는 채워진 폼으로부터 사용자 입력을 웹 서버로 제출하기 위해 사용된다.
- GET, POST가 있다.
- NAME
- 폼에 이름을 짓는다.
- 반드시 필요하지는 않지만, 폼 명명은 좋은 형식이다.
다음 예들을 보자.



HTML 폼등 내에서 가장 간단한 사용자 입력 원소는 INPUT 필드로서, 종료 태그를 자지지 않는 독립형 태그이다. INPUT 태그의 예는 다음과 같다.
<INPUT TYPE="text" NAME="username" VALUE="Joe">
INPUT 태그는 여러 개의 애트리뷰트를 가진다.
- TYPE: 입력 필드의 타입을 결정한다.
- text: 텍스트 입력 필드
- password: 기입된 문자들이 화면 위에 별들로 디스플레이 되는 텍스트 필드
- reset: 폼내의 모든 입력 필드들을 디폴트 값으로 새로 고치는 단순한 버튼
- submit: 폼 내의 다른 입력 필드들의 값들을 서버로 보내는 버튼
- reset과 submit은 전체 폼에 영향을 끼친다.
- NAME: 이 필드에 대한 상징적인 이름을 표시하며 서버로 보내어질 때 이 입력 필드의 값을 식별하기 위하여 사용된다.
- submit, reset을 제외한 모든 타입들의 INPUT 태그를 위해 설정되어야 한다.
- VALUE: 그 필드의 디폴트 내용을 표시하기 위해 텍스트 혹은 암호(password) 필드를 사용할 수 있다.
- 버튼 submit, reset을 위해, VALUE는 버튼의 이름표를 결정한다.
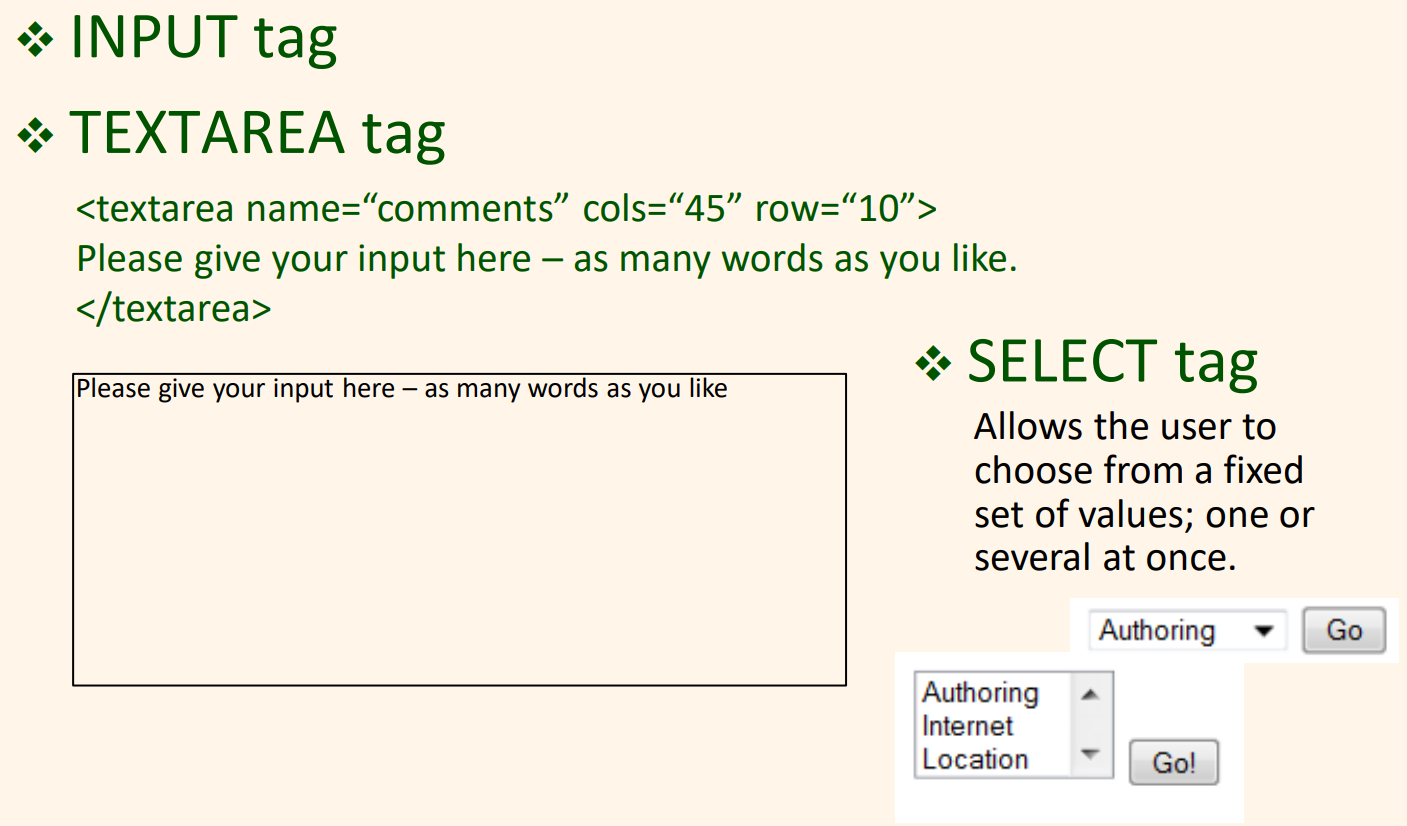
사용자 입력 원소들을 표시하는 태그들에는 INPUT, SELECT, TEXTAREA 태그들이 있다.
서버측 스크립트로 인수 전달
HTML 폼 데이터를 웹 서버로 제출하는 두 가지 다른 방법이 있다.
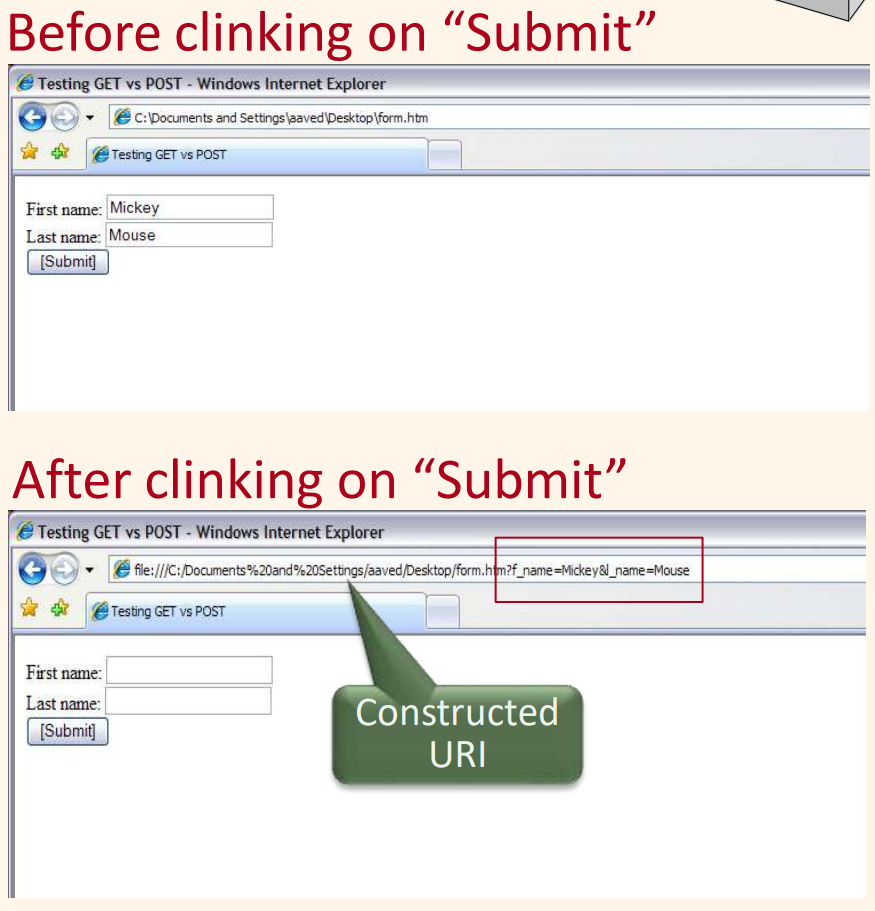
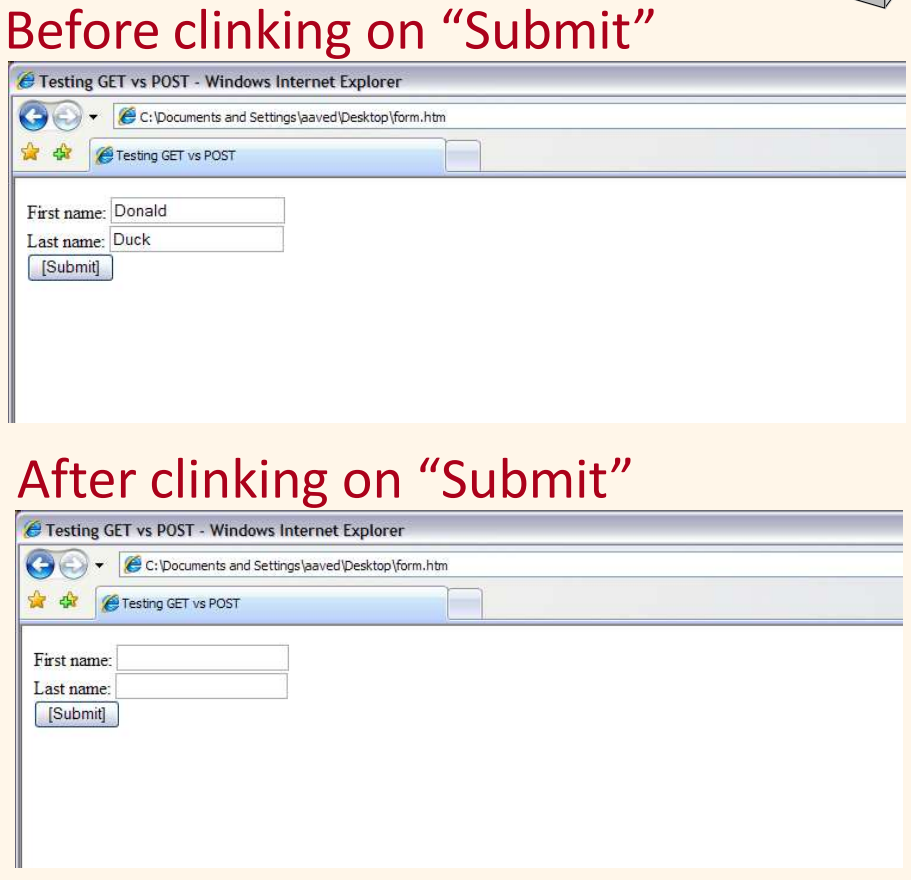
- GET: 그 폼의 내용들은 질의 URI로 모아져서 서버로 보내진다.
- POST: 그 폼의 내용들은 GET 메소드에서처럼 부호화되나, 내용들은 URI로 직접 그들을 첨가하는 대신에 분리된 데이터 블록으로 보내어진다.
그러므로, GET 메소드에서 폼 내용들은 작성된 URI로서 사용자에게 직접 보이는 반면에, POST 메소드에서 폼 내용들은 HTTP 요구 메시지 본체 내에서 보내어지고 사용자에게 보이지 않는다.
GET 메소드 사용은 작성된 URI를 가진 페이지를 책갈피하고 계속되는 세션에서 그곳으로 직접 이동할 기회를 사용자들에게 준다. 이것은 POST 메소드를 가지고는 불가능하다.
GET 메소드가 사용될 때의 URI의 부호화는 “action?name1=value1&name2=value2&name3=value3”형식을 가진다. action은 FORM 태그의 ACTION 애트리뷰트에서 표시된 URI이거나, 혹은 ACTION 애트리뷰트가 표시되지 않는다면 현재 문서의 URI이다. ‘name=value’ 쌍은 폼의 INPUT 필드로부터의 사용자 입력들이다. 사용자가 어떠한 입력도 하지 않은 폼 INPUT 필드에 대해, 그 이름은 아직까지 빈 값(name=)으로 존재한다. 다음 예를 보자.
폼들로부터 사용자 입력은 여백 문자와 같은 일반적인 ASCII 문자들을 포함할 수 있으나, URI들은 단일의 연속되는 여백없는 문자열이다. 그러므로, 여백, ‘=’, 다른 프린트할 수 없는 문자들과 같은 특수한 문자들은 특별한 방법으로 부호화된다. 부호화된 폼 필드들을 가지는 URI를 생성하기 위해, 다음과 같은 세 단계를 실행한다.
- 이름과 값들내의 모든 특수 문자들을 ‘%xyz’로 변환, 여기서 ‘xyz’는 그 문자의 ASCII 값에대한 16진수이다.
- 모든 여백 문자들을 ‘+’ 문자로 변환
- 개별적인 HTML INPUT 태드로부터 관련된 이름과 값들을 ‘=’를 가지고 함께 묶고, 그리고나서 폼들의 요구 URI를 창조하기 위해 다른 HTML INPUT 태그들로부터 이름-값 쌍들을 ‘&’를 사용해서 함께 붙인다.
POST 메소드에서 폼 내용들을 작성하여 보내질때는 다음과 같다.
자바스크립트
자바스크립트는 클라이언트에서 직접 작동하는 웹 페이지에 프로그램들을 추가할 수 있는 클라이언트 계층의 스크립팅 언어이다. 자바스크립트는 클라이언트에서 다음 형태의 계산을 위해 자주 사용된다.
- 브라우저 탐지
- 자바스크립트는 브라우저 타입을 탐지하고 브라우저 관련 페이지를 적재하기 위해 사용될 수 있다.
- 폼 정당화
- 자바스크립트는, 예를 들어 전자우편 주소를 요청하는 폼 입력이 문자 ‘@’를 포함하는지, 폼 필드들에 대한 간단한 일관성 검사를 실행하기 위해 사용된다. 혹은 모든 필요한 필드들이 사용자에 의해 입력되는지를 점검한다.
- 브라우저 제어
- 개별화된 윈도우에서 개시 페이지들을 포함한다.(Open new windows, e.g. pop-up ads)
자바스크립트는 항상 SCRIPT 태그인 특별한 태그를 가지고 HTML 문서로 내장된다. SCRIPT 태그는 다음과 같은 애트리뷰트를 가진다.
- LANGUAGE: 그 스크립트가 작성되는 언어를 표시하는 애트리뷰트이다.
- 자바스크립트를 위해, 언어 애트리뷰트에 JavaScript를 설정한다.
- SRC: HTML 문서로 자동적으로 내장되는 자바스크립트 코드를 가진 외부 파일을 표시한다.
- 항상 자바스크립트 소스 코드 파일들은 ‘.js’ 확장자를 사용한다.
다음은 HTML 문서에 포함되는 자바스크립트 파일을 보여준다.
<SCRIPT LANGUAGE="JavaScript" SRC="validateDorm.js"> </SCRIPT>
SCRIPT 태그를 인식하지 못하는 웹 브라우저에서는 자바스크립트 코드가 그대로 디스플레이되지 않도록 SCRIPT 태그는 HTML 주석 내에 놓일 수 있다. 다음과 같이 HTML 주석 내에서 팝업 상자를 창조하는 자바스크립트 코드감싸는 것을 보자.
<SCRIPT LANGUAGE="JavaScript">
<!-- alert("Welcome to our bookstore");
//-->
</SCRIPT>
실제, ‘<!- -‘는 한줄 주석의 시작을 표시하며, 그것은 자바스크립트 주석 표기를 사용한 위 예제에서 HTML 시작 주석 ‘<!- -‘을 표시할 필요가 없는 이유이다. HTML 종결 주석 ‘- ->’은 다르게 해석되므로 자바스크립트에서 주석처리 되어야 한다.;; 실제로 주석 처리 안되는데
자바스크립트는 두 가지 다른 주석 형식을 제공한다.
- ’//’ 문자로 시작하는 한줄 주석
- ’/*‘로 시작하고, ‘*/’로 끝나는 여러 줄 주석
자바스크립트는 수, 논리 값, 문자열 등의 데이터 타입들이 될 수 있는 변수들을 가진다. 전역 변수들은 var를 가지고 그들의 사용이 미리 선언될 수 있으며, 그들은 HTML 문서내의 어디에서든지 사용될 수 있다. 자바스크립트 함수에 지역적인 변수들은 선언될 필요가 없다. 고정된 타입을 가지지 않으나, 묵시적으로 배정된 데이터의 타입을 가진다.
자바스크립트는 다음과 같은 연산자를 가진다.
- 배정 연산자
- =, += 등
- 수식 연산자
- +, -, *, /, %
- 비교 연산자
- ==, !=, >= 등
- 논리 연산자
- &&, ||, !
문자열들은 ‘+’ 문자를 사용하여 연결될 수 있다. 한 객체의 타입은 연산자의 행동을 결정한다. 예를 들면, 1+1은 수들을 더하는 것이므로 2이며, “1”+”1”은 문자열들을 연결하는 것이므로 “11”이다. 자바스크립트는 다음과 같은 문장들을 포함한다.
- if(조건) {문장들;} else{문장들;}
- 순환문(for-loop, do-while, while-loop)
자바스크립트는 function 키워드를 사용하여 “function f(arg1, arg2) {문장들;}”과 같이 함수들을 생성하는 것을 허용한다. 다음 예를 보자.
<SCRIPT LANGUAGE = "JavaScript">
<!--
function testLoginEmpty() {
loginForm = document.LoginForm; // "document" is an implicitly defined variable referring to the current HTML page
if((loginForm.userid.value == " ") || (loginForm.password.value == " ")){
alert('Please enter values for userid and password.');
return false;
}
else
return true;
}
//-->
</SCRIPT>
<H1 ALIGN = "CENTER">Barns and Nobble Internet Bookstore</H1>
<H3 ALIGN = "CENTER">Please enter your userid and password:</H3>
<FORM NAME = "LoginForm" METHOD="POST" ACTION="TableOfContents.jsp" onSubmit="return testLoginEmpty()">
<!-- The form contents are submitted to server if function(testLoginEmpty) returns true -->
Userid: <INPUT TYPE="TEXT" NAME="userid"><P>
Password: <INPUT TYPE="PASSWORD" NAME="password"><P>
<INPUT TYPE="SUBMIT" VALUE="Login" NAME="SUBMIT">
<INPUT TYPE="RESET" VALUE="Clear Input" NAME="RESET">
</FORM>
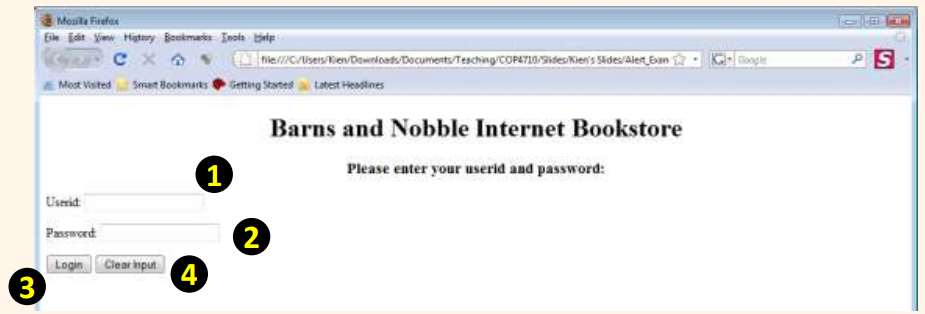
자바스크립트 코드는 LoginForm이란 이름의 폼에서 두 입력 필드의 어떠한 것이 비어 있는지를 검사하는 testLoginEmpty로 호출되는 함수이다. 함수 testLoginEmpty에서, 우선 현재의 HTML 페이지를 지칭하는 묵시적으로 정의된 변수인 document를 사용한 폼 LoginForm을 참조하는 변수 loginForm을 사용한다.(자바스크립트는 묵시적으로 정의된 객체들의 라이브러리를 가진다.) 그 다음 loginForm.userid.value 혹은 loginForm.password.value가 비어 있는지를 점검한다.
함수 testLoginEmpty는 폼 이벤트 처리기내에서 점검된다. 이벤트 처리기(event handler)는 어떤 이벤트가 웹 페이지의 객체에서 발생한 경우 호출되는 함수이다. 여기서 사용하는 이벤트 처리기는 onSubmit이며, submit 버튼이 눌러질 경우에 호출된다.(혹은 사용자가 폼의 텍스트 필드에서 반환을 누르는 경우) 만약 이벤트 처리기가 true를 반환하면, 폼 내용들이 서버에 제출되고, 그렇지 않으면 폼 내용들은 서버에 제출되지 않는다.
스타일 시트
스타일 시트는 다른 표현 양식들에 같은 문서 내용들을 적응시키기 위한 방법이다. 스타일 시트는 웹 브라이저에게 문서의 데이터를 클라이언트의 디스플레이를 위해 적당한 표현으로 변환시키는 방법을 말하는 사용 설명을 포함한다.
스타일 시트들은 페이지의 렌더링 모양들로부터 페이지의 변환 모양을 구별한다. 두 가지 스타일 시트 언어가 있다.
- XSL: XML 문서를 위해 만들어졌다.
- CSS: HTML을 위해 만들어졌다.
CSS
CSS(Cascading Style Sheet)는 HTML 원소들을 어떻게 디스플레이하는지를 정의한다. 스타일들은 보통 스타일 시트들에 저장되며, 그들은 스타일 정의를 포함하는 파일들이다. 웹사이트의 모든 문서처럼 많은 다른 HTML 문서들이 동일한 CSS를 참조할 수 있다. 그러므로, 한 파일을 바꿈으로서 한 웹사이트의 양식을 바꿀 수 있다. 이것은 동시에 많은 웹 페이지들의 배치를 바꾸는 매우 편리한 방법이며, 표현들로부터 내용을 분리하는 첫 단계이다. 다음은 스타일 시트의 예를 보여준다.
BODY {BACKGROUND-COLOR: yellow} /*<BODY BACKGROUND-COLOR="YELLOW">와 같은 효과를 가진다.*/
H1 {FONT-SIZE: 36pt}
H3 {COLOR: blue}
P {MARGIN-LEFT: 50px; COLOR: red}
위 코드는 다음과 같이 HTML 파일에 포함된다.
<LINK REL="style sheet" TYPE="text/css" HREF="books.css">
CSS 시트의 각 줄은 세 부분으로 구성된다: Selector {property: value}
- 선택자(Selector): 정의하는 포맷의 원소 혹은 태그이다.
- 특성(Property): 스타일 시트에서 설정하기를 원하는 값의 태그 애트리뷰트를 표시한다.
- 값(Value): 애트리뷰트의 실제 값
같은 선택자에 대해 여러 가지 특성은 세미클론에 의해서 구분될 수 있다.
XSL
XSL은 스타일 시트를 표현하기위한 일정의 언어이다. XSL의 특성들은 다음과 같다.
- XSLT라는 XSL 변환 언어를 포함한다.
- 입력 XML 문서를 다른 구조를 가진 XML 문서로 변환하도록 한다.
- XML 경로 언어(XPath)를 포함한다.
- XML 문서의 부분들을 참조하도록 한다.
- XSL 포매팅 객체를 포함한다.
- XSL 변환의 출력을 포매팅한다.
중간 계층
- CGI
- 인수들을 HTML 폼들로부터 중간 계층에서 작동하는 응용 프로그램으로 전송하기 위해 사용되는 일종의 프로토콜이다.
- 응용 서버(Application servers)
- Runtime environment at the middle tier
- 서블릿(Servlets)
- Java programs at the middle tier
- JavaServer Pages
- Java scripts at the middle tier
- 상태 유지(Cookies)
- Used to maintain state at the middle tier
CGI
CGI(Common Gateway Interface, 공통 게이트웨이 인터페이스)는 HTML 폼들을 응용 프로그램으로 연결한다. 간단하게 CGI 프로그램의 예를 보자. CGI를 통해 웹 서버로 통신하는 프로그램들을 CGI 스트립트라 하는데, 왜냐하면 그와 같은 많은 응용 프로그램들이 스크립팅 언어로 작성되었기 때문이다. 다음은 CGI를 통해 HTML 폼을 가지고 접속하는 프로그램의 예이다.
<HTML><HEAD><TITLE>The Database Bookstore</TITLE></HEAD>
<BODY>
<FORM ACTION="find_books.cgi" METHOD=POST>
Type an author name:
<INPUT TYPE="text" NAME="authorName" SIZE=30 MAXLENGTH=50>
<INPUT TYPE="submit" VALUE="Send it">
<INPUT TYPE="reset" VALUE="Clear form">
</FORM>
</BODY></HTML>
이 웹페이지는 사용자가 저자의 이름을 채울 수 있는 한 폼을 포함한다. 만약에 사용자가 ‘Send it’ 버튼을 누르면, ‘find_books.cgi’라는 Perl 스크립트가 별도의 프로세스처럼 수행된다. CGI 프로토콜은 그 폼과 스크립트 사이에서 통신이 수행되는 방법을 정의한다.
다음은 Perl로 작성된 CGI 스크립트의 예를 보여준다. 편의를 위해 오류 점검 코드는 생략한다.
#!/usr/bin/perl
use CGI;
###part1
$dataIn = new CGI; # Instantiate a CGI object
$dataIn->header(); # The header() function prints out the: "Content-Type: text/html" statement
$authorName = $dataIn->param('authorName'); # HTML 폼의 인수를 추출
###part2
print("<HTML><TITLE>Argument passing test</TITLE>"); # 출력 HTML 페이지를 조립
print("The user passed the following argument:");
print("authoeName: ", $authorName);
###part3
print("</HTML>"); # 완료 양식 태그를 결과 페이지에 추가
exit;
perl은 CGI 스크립팅을 위해 자주 사용되는 해석 방식의 언어이며, 모듈이라 불리는 많은 Perl 라이브러리들은 CGI 프로토콜에게 고수준의 인터페이스들을 제공한다.
CGI에는 다음과 같은 이슈들이 있다.

응용 서버
응용 프로그램은 CGI 프로토콜을 사용하여 불러내는 서버측 프로그램들을 통해서 시행될 수 있다. 그러나, 각 페이지는 새로운 프로세스 생성의 결과들을 요구하므로, 이 해결책은 많은 수의 동시 요구로 잘 확장되지 않는다. 이 성능 문제는 응용 서버(application server)라 불리는 특수한 프로그램들의 개발을 이끌어 냈다.
응용 서버들은 프로세스 생성 부하(process creation overhead)를 제거하기위해 다음을 수행한다.

응용 서버를 가진 웹사이트에 대한 가능한 아키텍처는 다음과 같다.
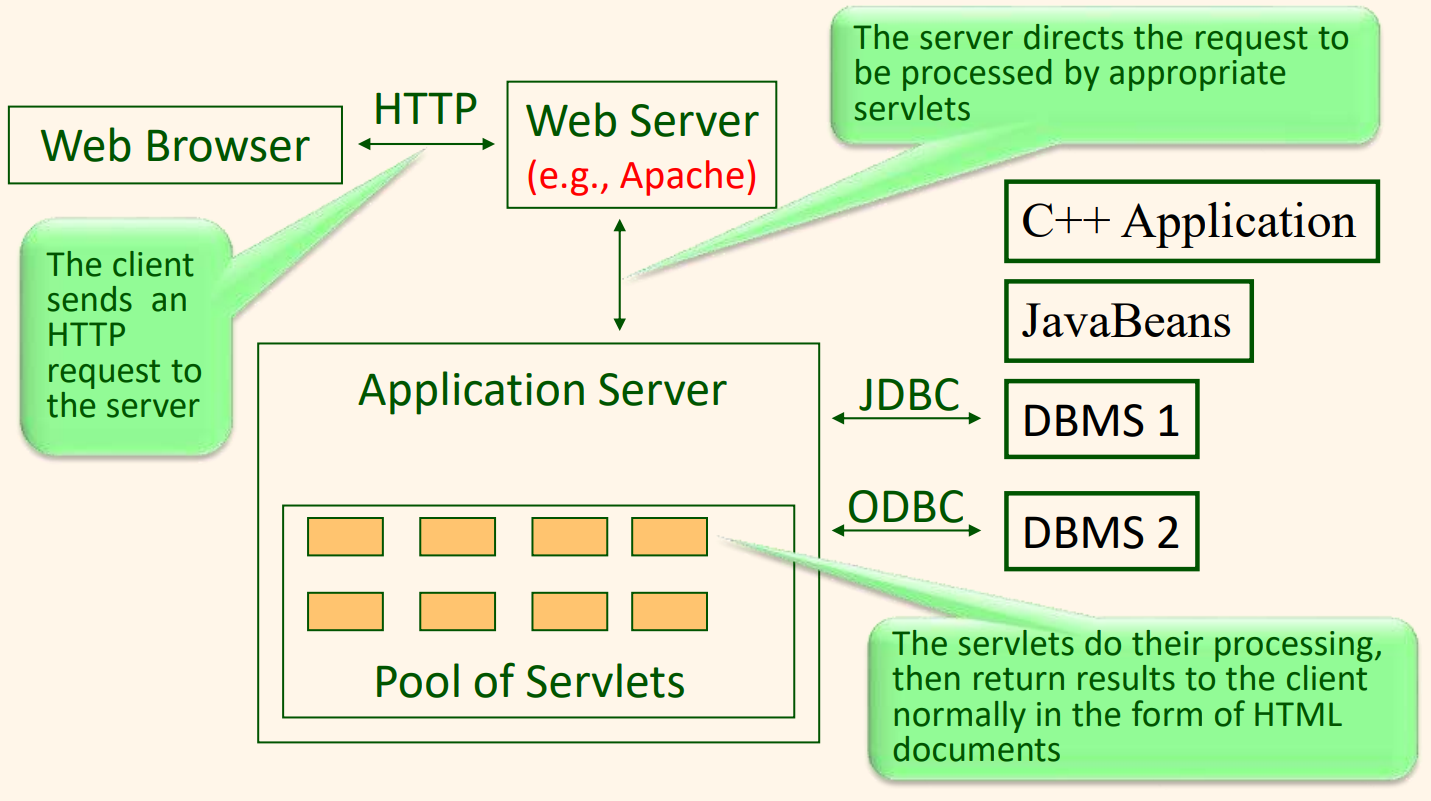
클라이언트는 HTTP 프로토콜을 통하여 웹 서버와 상호 작용한다. 웹 서버는 정적 HTML 페이지나 XML 페이지를 클라이언트에게 직접 전달한다. 동적 페이지들을 조립하기 위해, 웹 서버는 응용 서버로 요구를 보낸다. 응용 서버는 필요한 데이터를 검색하거나 데이터 소스들에게 갱신 요구들을 보내기 위해 하나 이상의 데이터 소스들과 접촉한다. 데이터 소스들과의 상호작용이 완료된 후, 응용 서버는 웹 페이지를 조립하고 그 결과를 웹 서버에게 보고하며, 웹 서버는 그 페이지를 검색해서 그것을 클라이언트로 전달한다.
서블릿
Servlets are Java`s answer to CGI programming. 자바 서블릿(Java servlet)은 중간 계층인 웹 서버나 응용 서버들에서 작동하는 자바 코드들이다. 대부분의 경우에, 서블릿들은 HTTP를 통해 클라이언트와 통신하는 서버들을 위해 특수한 HttpServlet 클래스로 확장된다. HttpServlet 클래스는 HTML 폼들로부터 인수들을 받기 위해 doGet과 doPosr하는 메소드를 제공하며, 그것은 HTTP를 통해 클라이언트로 그 결과를 돌려준다.
서블릿들은 항상 HTML 폼들로부터의 요구를 처리하며, 클라이언트와 서버사이의 상태를 유지한다. 일반적인 서블릿 구조의 형틀은 다음과 같다.
import java.io.*;
import java.servlet.*;
import java.servlet.http.*;
public class ServetTemplate extends HttpServlet {
public void doGet(HTTPServletRequest request, // request object is used to read HTML form data
HTTPServletResponse response) // 객체 response는 HTTP 응답 상태 코드와
// HTTP 응답의 머리말을 표시하기 위해 사용된다.
throws SerletException, IOException {
PrintWriter out=response.getWriter();
//Use ‘out’ to send content to browser
out.println(“Hello World”);
}
}
이 간단한 서블릿은 “Hello World” 두 단어만 출력하지만, 완성된 서블릿의 일반 구조를 보여준다.
HTTP는 상태 줄, 머리말, 빈 줄, 문맥을 되돌려준다. 즉시 이 서블릿은 단순한 텍스트만 반환한다. HTML로 내용 타입을 설정하고 다음처럼 HTML을 생성함으로서 이 서블릿을 확장할 수 있다.
import java.io.*;
import java.servlet.*;
import java.servlet.http.*;
import java.util.*;
public class ReadUserName extends HttpServlet {
public void doGet( HttpServletRequest request,
HttpSevletResponse response)
throws ServletException, IOException {
reponse.setContentType(“text/html”); // Prepare "Content-Type: text/html" statement in header of Web page
PrintWriter out=response.getWriter();
out.println(“<HTML><BODY>\n <UL> \n” +
“<LI>” + request.getParameter(“userid”) + “\n” +
“<LI>” + request.getParameter(“password”) + “\n” +
“<UL>\n<BODY></HTML>”); // We extend the servlet to dynamically generate HTML
}
public void doPost( HttpServletRequest request,
HttpSevletResponse response)
throws ServletException, IOException {
doGet(request,response);
}
}
서블릿의 라이프 사이클에 대한 설명은 다음과 같다.

JSP(JavaServer Pages)
서블릿들은 출력을 위해 내장된 HTML을 가지고 응용 논리를 통합하는 자바 코드이다. JSP들은 특별한 HTML 태그 내에 내장된 서블릿형 코드를 가지고 HTML에서 작성된다. 따라서, 서블릿들과 비교하여, JSP들은 인터페이스를 빠르게 구성하는 데 더 적합하나, 복잡한 응용 논리를 위해서는 서블릿을 사용하는것이 좋다.
다음은 간단한 JSP 예를 보여준다. HTML 코드의 중간 부분에서, 한 폼으로부터 전달된 정보에 접근한다.
<html>
<head><title>Welcome to B&N</title></head>
<body>
<h1>Welcome back!</h1>
<% String name = “NewUser”;
if (request.getParameter(“username”) != null) {
name=request.getParameter(“username”);
}
%>
You are logged on as user <%=name%>
<p>
Regular HTML for all the rest of the on-line store`s webpage.
</body>
</html>

상태 유지
HTTP 프로토콜은 무상태이다.
- 장점
- 프로그램하고 사용하기 쉽다.
- 정적 정보의 검색만 요구하는 응용들에 대해서는 훌륭하다.
- 상태를 유지하기 위하여 추가 메모리가 전혀 사용되지 않고, 프로토콜 그 자체는 매우 효율적이다.
- 단점
- 표현 계층과 중간 계층에서 어떠한 부가적인 메카니즘 없이, 이전의 요구를 기록하지 못하고, 장바구니 혹은 사용자 로그인을 프로그램할 수 없다.
HTTP 프로토콜은 상태를 유지할 수 없으므로, 중간 계층이나 쿠기의 형태로 데이터를 저장함으로서 클라이언트측에 상태를 유지할 수 있다.
중간 계층에서 상태 유지
중간 계층에서 어디에 상태를 유지하느냐에 대해 여러 선택지가 있다.
- 데이터 베이스 서버의 바닥 계층
- 상태는 시스템의 고장에서도 생존한다.
- 데이터베이스 접근은 질의하거나 상태를 갱신라기 위해 요구되며, 잠재적 성능은 병목화된다.
- 주기억장치(local memory)
- 정보가 휘발성이며 많은 주기억장치를 차지한다.
두 접근법들 사이를 절충함으로서 중간 계층의 지역 파일에 상태를 저장할 수 있다.
일반적 규칙으로는 중간 계층 혹은 많은 다른 사용자 세션들에서 지속될 필요가 있는 데이터만을 위해 데이터베이스 계층에서 상태 유지를 사용하는 것이다. 예로, 과거 고객 주문들, 웹사이트를 통한 사용자 이동을 기록하는 마우스로 선택하는 연속 데이터, 개별적인 사이트 배치에 대한 결정과 같은 사용자가 만드는 다른 영구적인 선택이 있다.
표현 계층에서 상태 유지: 쿠기
표현 계층에서 상태를 저장하고 그것을 모든 HTTP 요구를 가진 중간 계층으로 전달하는 것이다. 본래 추가의 정보를 모든 요구와 함께 보냄으로서 HTTP 프로토콜의 무상태성에 대해 작업한다. 그와 같은 정보는 쿠키라 불린다.
쿠키는 표현 계층과 중간 계층들에서 조작될 수 있는 <이름, 값> 쌍의 모임이다.
- 장점
- 자바 서블릿과 JSP에서 사용하기가 쉽다.
- 클라이언트에서 중요하지 않은 데이터를 지속하도록 만드는 간단한 방법을 제공한다.
- 브라우저가 닫혀진 후에서조차 브라우저 캐시에 지속되기 때문에 여러 클라이언트 세션들을 살아남게 된다.
- 단점
- 쿠키가 가끔 침략적인 것으로 파악되어, 많은 사용자들이 웹 브라우저에서 쿠키의 기능을 억제한다. 브라우저들은 쿠키가 그들의 기계에 저장되는 것을 막도록 사용자에게 허용한다.
- 쿠키내의 데이터가 현재로는 4KB로 제한되어 있으나, 대부분의 응용에 대해 나쁜 제한은 아니다.
사용자의 장바구니, 로그인 정보, 현재의 세션에서 만들어진 영구적이지 않은 다른 선택들과 같은 정보를 저장하기 위하여 쿠키를 사용할 수 있다.
서블릿 쿠키 API
자바 Cookie 클래스를 통해 중간 계층 응용 코드에서 새로운 쿠키를 생성한다.
Cookie myCookie = new Cookie(“username”, “jeffd”);
Cookie.setDomain(www.bookstore.com); // Web site that receives this cookie
Cookie.setSecure(false): // no SSL required
Cookie.setMaxAge(60*60*24*31) // one month lifetime
response.addCookie(myCookie);
이 코드의 각 부분을 살펴보자.
- <이름, 값> 쌍으로 표시된 새로운 Cookie 객체를 생성한다.
- 그 쿠키의 애트리뷰트를 설정한다.
- 쿠키는 클라이언트로 보내어지는 자바 서블릿내의 request 객체에 더해진다.
- 쿠키를 한 사이트로부터 받을 때, 클라이언트의 웹 브라우저는 그 쿠기가 만료될 때까지 이 사이트로 보낸 모든 HTTP 요구들에게 그 쿠키를 덧붙인다.
- 중간 계층 코드에서 request 객체의 getCookies() 메소드를 통해 쿠키의 내용들을 접근할 수 있으며, 그 메소드는 쿠키 객체들의 배열을 반환한다.
- 다음 코드는 배열을 읽어서 이름 ‘username’을 가진 쿠키를 찾는다.
Cookie[] cookies = request.getCookies(); // returns an array of cookies String theUser; for(int i=0; i < cookies.length; i++) { Cookie cookie = cookies[i]; if(cookie.getName().equals(“username”)) theUser = cookie.getValue(); } // at this point theUser == “username”
간단한 검사는 사용자가 쿠키들을 없애는 지를 점검하기 위해서 사용될 수 있다. 사용자에게 쿠키를 보내고, 그런 다음 반환된 request 객체가 쿠키를 아직까지 포함하는지를 점검한다. 사용자는 세션주일 때를 포함한 어느 시점이라도 임의의 쿠키를 쉽게 살피고, 수정하며, 지울 수 있으므로, 쿠키는 암호화되지 않은 암호나 다른 사적이고 암호화되지 않은 데이터를 결코 포함하지 않는다. 응용 논리는 쿠키내의 데이터가 정당하다는 것을 보장하기 위해 충분한 일관성 검사를 할 필요가 있다.
- 다음 코드는 배열을 읽어서 이름 ‘username’을 가진 쿠키를 찾는다.
댓글남기기