인메모리 저장소 및 캐싱 전략
Updated:
Redis는 Remote DIctionary Server를 줄인말로, Java의 Map과 같은 방식으로 데이터를 저장하는 데이터베이스이다. 일반적인 관계형 데이터베이스와 다른 가장 큰 특징은 In-Memory 데이터베이스라는 특징이 있다.
관계형 데이터베이스는 영속성을 제공하는데 목적을 두고 있어 데이터가 사라지지 않게 하기 위해 파일시스템(SSD, HDD)에 저장한다는 의미이며, 컴퓨터가 종료되어도 데이터가 사라지진 않지만 기본적으로 데이터를 읽고 쓰는데 오래걸린다.
하지만 Redis는 메모리에 데이터를 저장하기 때문에, 복잡한 입출력 과정이 필요하지 않다. 그래서 일반적인 관계형 데이터베이스에 비해 더 빠르게 동작하는 대신, 언제든 사라질 수 있는 데이터를 다룬다는 차이를 가지고 있다. 그래서 특정 게시글의 조회수와 같이 빠르게 업데이트되는 데이터, 또는 사용자 세션, 장바구니와 같은 시간이 지나면 삭제되는 데이터등을 저장하기 위해서 가장 많이 사용된다. 또한 내부적으로 데이터를 저장하는 방식이 RDBMS와 다르다는 특징도 가지고 있다.
관계형 데이터베이스는 일반적으로 테이블 형식으로 데이터를 저장하고, 그 데이터를 회수하기 위해 SQL을 사용한다. 반면 Redis는 단순 문자열(String)부터, 리스트, 집합, Hash 등 다양한 형태의 데이터를 저장하며, 이 데이터를 회수하기 위해 SQL을 사용하지 않는다.
SET greeting "Hello, Redis!"
GET greeting
Redis는 대표적인 NoSQL 데이터베이스이다. NoSQL은 데이터베이스를 만드는 접근법의 일종으로, Not only SQL을 의미한다. 이들은 일반적인 관계형 데이터베이스가 약점을 가진 확장성, 유연성, 성능에 대한 문제를 해결하기 위해 사용되는 경우가 많으며, 컴퓨터 기술의 발전과 웹의 활성화로 인해 비정형 데이터를 더 높은 성능으로 사용하는데 초점이 맞춰진 경우가 많다.
스키마와 SQL을 사용하는 관계형 데이터베이스와 달리, NoSQL 데이터베이스는 데이터를 관리하는 방법이 서로 다르며, 사용법도 판이하게 다르다.
- Key-Value: 가장 단순한 형태의 데이터베이스로, Key에 Value를 저장하는 형태
- JSON, Python의 Dictionary, Java의 Map의 형태로 데이터를 관리
- 대표적으로 Redis가 존재
- Document: 객체를 표현하는 Document라는 단위로 데이터를 저장하는 형태
- Key - Value에서 발전했다고 볼 수 있으며, JSON, XML 등 복잡한 데이터를 저장하고 관리
- 대표적으로 MongoDB가 존재
- Column-Family: 각 Row의 Column이 고정되어있지 않고, 필요한 데이터 Column을 이름, 데이터, Timestamp와 함께 저장하는 형태의 데이터베이스
- 대표적으로 cassandra가 존재
관계를 기준으로 데이터를 다루지 않기 때문에 스키마를 만들지 않고, 그렇기 때문에 비정형 대규모 데이터를 매우 빠르게 다룰 수 있다.
Redis는 NoSQL 중에서도 Key-Value Store로 작동하는 인메모리 데이터베이스로, 지연이 적은 읽기, 쓰기 성능을 가지고있다. 그렇기 때문에 일시적인 데이터, 변경이 잦은 데이터를 다뤄야 되는 상황에서 많이 활용된다.
- Session Clustering: 여러 애플리케이션 인스턴스에서 같은 세션 정보를 사용할 수 있도록 도와줌
- Caching: 자주 사용되는 데이터를 저장해두어, 데이터베이스 조회를 줄이고 전반적인 응답속도를 개선
- 지원하는 다양한 자료구조를 바탕으로 리더보드, 방문수 트래킹, 좌표 기반 검색 등의 기능을 쉽게 구현할 수 있게 해줌
로컬환경에 Redis를 설치하기 위해서는 Docker를 이용하면 된다. Docker Hub에서 Redis를 검색하면 다음과 같은 결과가 나온다.
redis: 여태까지 가장 많이 사용되어 오던 Redis 서버의 핵심(Core)- 가장 간단한 형태의 연습을 하고 싶다면 redis를 사용
redis/redis-stack-server: 여러 플러그인이 추가된 Redis Stack 서버 이미지- 확률형 데이터, JSON 문서 등을 사용하고 싶다면 선택
redis/redis-stack:redis/redis-stack-server에 Redis Insight가 추가된 이미지- Redis Insight를 같이 사용하고 싶다면 선택
이번에는 redis-stack 이미지를 사용한다. 다음 docker-compose.yml 파일을 만들고 docker compose up -d 를 진행한다.
services:
redis-stack:
image: redis/redis-stack
container_name: redis-stack-compose
restart: always
environment:
REDIS_ARGS: "--requirepass systempass"
ports:
- 6379:6379
- 8001:8001
- 위
systempass가 비밀번호의 역할을 한다.

이제 Intellij와 연결한다.
위 docker-compose에서 redis Insight도 같이 설치되었다. localhost:8001에 접속하고 redis를 연결하면 다음과 같은 화면을 볼 수 있다.
Redis 타입
Redis는 Key - Value 데이터베이스로, 대부분의 명령이 Key를 바탕으로 동작하게 되며, Value로 사용하고자 하는 자료형에 따라 다른 명령어를 사용하게 된다. 또한 대부분의 명령이 존재하지 않는 Key를 이용해도 정상적으로 동작하며, 없는 Key에 데이터를 저장하면 Key를 생성한다. 단, 이미 만든 Key에 해당하는 데이터와 다른 자료형의 명령을 사용하는 경우 오류가 발생할 수 있다.
다음은 Redis의 타입들이다.
String
가장 기본적인 자료형이며, Redis가 Java의 Map<String, String>처럼 동작한다. 저장할 수 있는 최대 크기는 512MB이다.
- GET, SET
SET user:email alex@example.com GET user:emailSET <key> <value>:key에value문자열 데이터를 저장,"으로 공백 구분GET <key>:key에 저장된 문자열 반환- 만약 저장된 데이터가 정수 데이터라면 데이터를 바로 증가, 감소가 가능하다.
- INCR, DECR
SET user:count 1 INCR user:count DECR user:countINCR key:key에 저장된 데이터를 1 증가DECR key:key에 저장된 데이터를 1 감소- 여러 Key - Value를 한번에 다루고 싶다면
MSET,MGET을 활용할 수 있다.
- MSET, MGET
MSET user:name alex user:email alex@example.com MGET user:name user:emailMSET key value [key value …]:key value의 형태로 주어진 인자들을 각key에value를 저장MGET key [key]: 주어진 모든key에 해당하는 데이터를 반환- 단순 문자열이지만, 문자열은 결국 바이트 배열이므로 이미지, 음성, 영상, 파일, 또는 이메일 본문 등도 보관이 가능하다.
- 그래서 분산된 구조에서 비교적 큰 사이즈의 데이터를 주고받아야 하는 상황에 Key만 전달해서 데이터는 여기있다 전달하는 방식으로 활용할 수 있다.
List
여러 문자열 데이터를 Linked List의 형태로 보관하는 자료형이다. 리스트의 경우 소셜 네트워크에서 많이 사용하는 자료형이다. Linked List이기 때문에, 중간의 데이터 보다는 양끝의 데이터, 즉 스택 또는 큐 처럼 사용할 수 있다.
PUSH 또는 POP을 L 또는 R과 조합하여, 왼쪽 또는 오른쪽에 데이터를 추가, 제거가 가능하다.
- LPUSH, RPUSH, LPOP, RPOP
LPUSH user:list alex # [alex] LPUSH user:list brad # [brad, alex] RPUSH user:list chad # [brad, alex, chad] RPUSH user:list dave # [brad, alex, chad, dave] LPOP user:list # brad RPOP user:list # chadLPUSH key value:key에 저장된 리스트의 앞쪽에value를 저장RPUSH key value:key에 저장된 리스트의 뒤쪽에value를 저장LPOP key:key에 저장된 리스트의 앞쪽에서 값을 반환 및 제거RPOP key:key에 저장된 리스트의 뒤쪽에서 값을 반환 및 제거Map<String, List<String>>의 형태로 사용한다고 생각하면 된다.- 리스트를 사용하면서 흔히 사용하는 길이 구하기, 범위 내 원소 반환하기 등의 기능도 제공
- LLEN, LRANGE
LLEN user:list LRANGE user:list 0 3 LRANGE user:list 0 -1LLEN key:key에 저장된 리스트의 길이를 반환LRANGE key start end:key의start부터end까지 원소들을 반환LLEN은 없는 Key를 대상으로 하면 0이 되지만, 다른 자료형을 저장한 Key를 대상으로 하면 오류가 발생한다.LRANGE의 경우 (언제나 그렇듯) 시작을 0으로 생각하고,end가 실제 길이를 벗어나도 오류가 발생하진 않는다.start>end일 경우 빈 결과가 반환된다. 음수의 경우 리스트의 뒤에서부터 데이터를 가져온다.
Set
문자열의 집합이다. 집합인 만큼 중복값을 제거하며, 순서가 존재하지 않는다.
- SADD, SREM, SMEMBERS, SISMEMBER, SCARD
SADD user:java alex # [alex] SADD user:java brad # [alex, brad] SADD user:java chad # [alex, brad, chad] SREM user:java alex # [brad, chad] SMEMBERS user:java # [alex, brad, chad] SISMEMBER user:java brad # true SISMEMBER user:java dave # falseSADD key value:key에 저장된 집합에value를 추가SREM key value:key에 저장된 집합의value를 제거SMEMBERS key:key에 저장된 집합의 모든 원소를 반환SISMEMBER key value:key에 저장된 집합에value가 존재하는지 반환SCARD key:key에 저장된 집합의 크기를 반환- 여기에 복수의 집합이 있다면, 교집합, 합집합 등의 기능을 제공한다. 결과 집합 자체를 반환하기도, 결과 집합의 크기를 반환하기도 한다.
- SINTER, SUNION, SINTERCARD
# 다른 Set에 추가한 뒤, SADD user:python alex SADD user:python dave SINTER user:java user:python # [alex] SUNION user:java user:python # [alex, brad, chad, dave] SINTERCARD 2 user:java user:python # 1SINTER key1 key2:key1과key2에 저장된 집합들의 교집합의 원소들을 반환SUNION key1 key2:key1과key2에 저장된 집합들의 합집합의 원소들을 반환SINTERCARD number key1 [key2 ...]:number개의key에 저장된 집합들의 교집합의 크기를 반환- 중복을 허용하지 않으며, 어떤 데이터의 존재 여부를 확인하는
SISMEMBER같은 경우 O(1)의 시간복잡도를 가지고 있다. 그래서 중복 없는 방문 수, 인증 토큰 블랙리스트 등을 구현할때 활용할 수 있다. - 단, 매우 높은 방문수를 기록하는 서비스의 경우 실제 데이터가 필요하지 않다면, 근사값을 돌려주는 확률형 자료형을 사용하는게 권장된다.
Hash
Field - Value 쌍으로 이뤄진 자료형이다. Hash 데이터를 가져오기 위해 Key를 사용하고, 이후 다시 Key에 저장된 Hash 데이터에 Field - Value 쌍을 넣어주는 형식으로 동작하게 된다. 즉, Redis 전체가 Map 이라면 Hash는 Map<String, Map<String, String>>의 형식이라고 생각할 수 있다.
- HSET, HGET, HMGET, HGETALL, HKEYS, HLEN
HSET user:alex name alex age 25 HSET user:alex major CSE HGET user:alex name HGET user:alex age HMGET user:alex age major HGETALL user:alex HKEYS user:alex HLEN user:alexHSET key field value [field value]:key의 Hash에field에value를 넣는다. 한번에 여러field-value쌍을 넣어줄 수 있다.HGET key field:key에 저장된 Hash의field에 저장된value를 반환. 없는field의 경우null.HMGET key field [field]:key에 저장된 Hash에서 복수의field에 저장된value를 반환.HGETALL key:key에 저장된 Hash에 저장된field-value를 전부 반환.HKEYS key:key에 저장된 Hash에 저장된field를 전부 반환HLEN key:key에 저장된 Hash에 저장된field의 갯수를 반환- Hash는 본래 하나의 키에 복잡한 데이터 (객체의 데이터 라던지)를 하나의 키에 저장하는 용도로 주로 활용되고, 공식 문서에서도 여러 Key에 걸쳐 객체의 데이터를 표현하기 보단 Hash를 자주 활용할 것을 권장하고 있다.
- 장바구니 같은 기능은 사용자별로, 어떤 물품이 몇개나 담겨있는지와 같은 정보가 포함되어야 한다. 사용자 마다 Hash 데이터를 생성하고, 물품 - 갯수 형식으로 데이터를 저장하면 사용자별 장바구니를 쉽게 저장할 수 있다.
Sorted Set
이름처럼 정렬된 집합이다. 기본적으로 Set과 동일하게, 유일한 값들만 유지하지만 여기에 더해 각 값들에 score라고하는 실수를 함께 보관한다. 그리고 데이터를 가져올 때, score를 바탕으로 정렬하여 값들을 가져올 수 있다.
- ZADD, ZINCRBY, ZRANK, ZRANGE, ZREVRANK, ZREVRANGE
ZADD user:ranks 10 alex ZADD user:ranks 9 brad 11 chad ZADD user:ranks 8 dave ZINCRBY user:ranks 2 alex ZRANK user:ranks alex ZRANGE user:ranks 0 3 ZREVRANK user:ranks alex ZREVRANGE user:ranks 0 3ZADD key score member [score member ...]:key의 Sorted Set에score를 점수로 가진member를 추가, 이미 있는member의 경우 새로운score를 설정ZRANK key member:key의 Sorted Set의member의 순위를 오름차순 기준으로 0에서 부터 세서 반환ZRANGE key start stop:key의 Sorted Set의member들을start부터stop순위까지 오름차순 기준으로 반환ZREVRANK key member:key의 Sorted Set의member의 순위를 내림차순 기준으로 0에서 부터 세서 반환ZREVRANGE key start stop:key의 Sorted Set의member들을start부터stop순위까지 내림차순 기준으로 반환ZINCRBY key increment member:key의 Sorted Set의member의score를increment만큼 증가 (음수를 전달하면 감소)- 대표적으로 리더보드나 Rate Limiter, 즉 순위와 관련된 기능을 만드는데 사용된다.
- Rate Limiter란, API 등을 제공할 때 짧은 시간에 지나치게 많은 요청을 막기 위한 기능을 의미한다.
그 외 공용 명령
그 외 자료형과 상관없이 사용할 수 있는 명령들이 있다. 이 중 대표적으로 많이 사용하는 건, Key를 제거하기 위한 DEL, 만료시각 설정을 위한 EXPIRE 등이 있다.
- DEL, EXPIRE, EXPIRETIME
SET somekey "to be deleted" DEL somekey SET expirekey "to be expired" EXPIRE expirekey 5 EXPIRETIME expirekeyDEL key:key(와 저장된 데이터)를 제거EXPIRE key seconds:key의 TTL(유효시각)을seconds로 설정,seconds초가 지나면key제거EXPIRETIME key:key가 만료되는 시각을 Unix Timestamp로 반환- 만약 저장된 모든 Key를 확인하고 싶다면, 다음과 같이 사용할 수 있습니다. 이는 glob 패턴 형식을 전달하여, 패턴에 일치하는 키를 반환하는 메서드이다.
KEYS *- 여기서
*은 Linux 파일시스템 등에서 흔히 사용하는 Glob 패턴이며,*은 임의갯수의 글자를 대체하는 와일드카드이다. 지금은*만 있으므로, 모든 Key와 일치하는 패턴이기 때문에 모든 Key가 반환된다.
- 여기서
- 마지막으로, 모든 Key를 제거하고 싶다면
FLUSHDB를 사용할 수 있다.FLUSHDB
Spring에서 Redis 사용
Spring Web, Lombok, Spring Data Redis (Access+Driver) dependencies를 추가해 Spring 프로젝트를 생성한다. 이후 application.yml을 다음과 같이 작성한다.
spring:
data:
redis:
host: localhost
port: 6379
username: default
password: password
host와 port를 작성하지 않으면 localhost:6379에 연결을 시도한다.
다음과 같이 Item 도메인 객체와 Repository를 작성한다.
@Getter
@Setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
@RedisHash("item")
public class Item implements Serializable {
@Id
private Long id;
private String name;
private String description;
private Integer price;
}
- RedisHash: Entity 어노테이션과 비슷
- Serializable: 직렬화가 가능하다는 것을 나타내는 어노테이션
public interface ItemRepository extends CrudRepository<Item, Long> {}
- JpaRepository 대신 CrudRespository 사용
- CrudRepository는 특별히 메서드를 선언하지 않아도 기본적인 CRUD 작업을 위한 메서드가 마련됨
간단한 CRUD 작업을 테스트 코드에서 작성해본다.
@SpringBootTest
public class RedisRepositoryTests {
@Autowired
private ItemRepository itemRepository;
@Test
public void createTest() {
// 객체 생성
Item item = Item.builder()
.name("keyboard")
.description("Very Expensive Keyboard")
.price(100000)
.build();
// save 호출
itemRepository.save(item);
}
}
이를 실행시키고 Redis의 데이터를 살펴보면 다음과 같다.
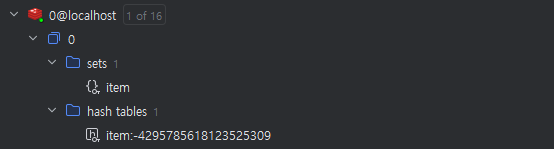
이를 보면 sets에 item이 생기고 hash tables에는 item의 id 값이 1부터 증가하는 Entity와 다르게 랜덤한 Long 값으로된 key가 들어가는 것을 확인할 수 있다. item:key를 확인해보면 다음과 같이 Item 객체의 데이터가 담긴 것을 확인할 수 있다.
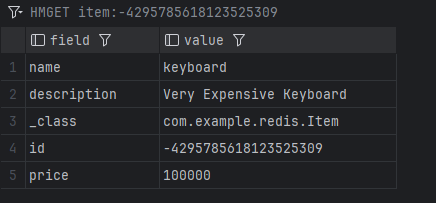
다음과 같이 id를 지정할 수도 있다.
@Test
public void createTest() {
// 객체 생성
Item item = Item.builder()
.id(1L)
.name("keyboard")
.description("Very Expensive Keyboard")
.price(100000)
.build();
// save 호출
itemRepository.save(item);
}
나머지 테스트도 작성해본다.
@Test
public void readOneTest() {
Item item = itemRepository.findById(1L).orElseThrow();
System.out.println(item.getDescription());
}
@Test
public void updateTest() {
Item item = itemRepository.findById(1L).orElseThrow();
item.setDescription("On Sale!!!");
itemRepository.save(item);
System.out.println(item.getDescription());
}
@Test
public void deleteTest() {
itemRepository.deleteById(1L);
}
각각 순서대로 실행하면 최종적으로 Redis의 모든 키들이 사라지게 된다. 만약 Item 클래스에서 Id의 타입을 Long에서 String으로 바꿔주게 된다면 UUID가 자동으로 배정된다.
Repository를 사용하는 것은 CRUD작업을 손쉽게 만들 수 있으며, JPA와 유사하다는 장점을 가지고 있다. 한편 Redis의 서로 다른 자료형, 그 자료형을 활용한 복잡한 기능을 만드는데는 한계가 있다.
RedisTemplate 사용
flushdb를 한 후 RedisTemplate를 사용해본다. 복잡한 작업 없이 Java의 문자열만 다루는 경우, StringRedisTemplate가 기본으로 만들어진다. 이는 Key와 Value를 전부 Java의 문자열이라고 가정한다. 문자열 데이터를 주고받기 위한 작업들을 준비하며, 기본 설정을 가지고 자동으로 만들어져 주입되는 Spring Bean이다.
@SpringBootTest
public class RedisTemplateTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void StringOpsTest() {
// 문자열 조작을 위한 클래스
// 지금 RedisTemplate에 설정된 타입을 바탕으로 Redis 문자열 조작을 할 거다.
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
ops.set("simpleKey", "simpleValue");
System.out.println(ops.get("simpleKey"));
// 집합을 조작하기 위한 클래스
SetOperations<String, String> setOps = stringRedisTemplate.opsForSet();
setOps.add("hobbies", "games");
setOps.add("hobbies",
"coding", "alcohol", "games");
System.out.println(setOps.size("hobbies"));
stringRedisTemplate.expire("hobbies", 10, TimeUnit.SECONDS);
stringRedisTemplate.delete("simpleKey");
}
}
- StringRedisTemplate는 각 자료형에 대응하는 Operations 인터페이스 구현체를 반환할 수 있는 메서드들을 가지고 있음
- opsForValue() 메서드를 호출하게 될 경우
ValueOperations<String, String>이 반환
- opsForValue() 메서드를 호출하게 될 경우
- ValueOperations<String, String>은 Java의 String 데이터를 Key와 Value로, Redis의 String 작업을 할 수 있는 메서드를 보유하고 있음
- set, get, multiSet, multiGet 등 원래 String 데이터 타입을 기준으로 사용하던 다양한 명령들이 메서드로 구현되어 있음
- EXPIRE, DEL과 같은 공용 기능은 StringRedisTemplate 자체에 정의되어 있음
@RedisHash가 적용된 Item 대신 사용할 ItemDto를 생성한다.
@Getter
@ToString
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ItemDto implements Serializable {
private String name;
private String description;
private Integer price;
}
그리고 @Configuration을 적용한 RedisConfig 클래스를 생성한다.
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, ItemDto> itemRedisTemplate(
RedisConnectionFactory connectionFactory
) {
RedisTemplate<String, ItemDto> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
template.setKeySerializer(RedisSerializer.string());
template.setValueSerializer(RedisSerializer.json());
return template;
}
}
- RedisTemplate를 만들면서, 타입 파라미터를 String, ItemDto로 설정한다.
- Key는 Java의 String, Value는 ItemDto를 사용해 Redis와 소통한다는 의미
- Redis와의 연결을 담당할 RedisConnectionFactory를 template에 전달한다.
- RedisConnectionFactory의 경우 application.yml 파일의 내용을 바탕으로 내부적으로 만들어 Bean 객체로 등록
- 데이터 직렬화 방법을 결정한다.
- key는 문자열로 직렬화, 역직렬화를 진행
- value는 데이터를 JSON으로 직렬화
- template를 반환하면 Bean 객체로 등록
이제 위 RedisTemplate를 사용하는 테스트를 작성해본다.
@Autowired
private RedisTemplate<String, ItemDto> itemRedisTemplate;
@Test
public void itemRedisTemplateTest() {
ValueOperations<String, ItemDto> ops = itemRedisTemplate.opsForValue();
ops.set("my:Keyboard", ItemDto.builder()
.name("Mechanical Keyboard")
.price(250000)
.description("OMG")
.build());
System.out.println(ops.get("my:Keyboard"));
ops.set("my:mouse", ItemDto.builder()
.name("mouse mice")
.price(100000)
.description("OMG")
.build());
System.out.println(ops.get("my:mouse"));
}
MGET을 해보면 다음과 같이 출력된다.
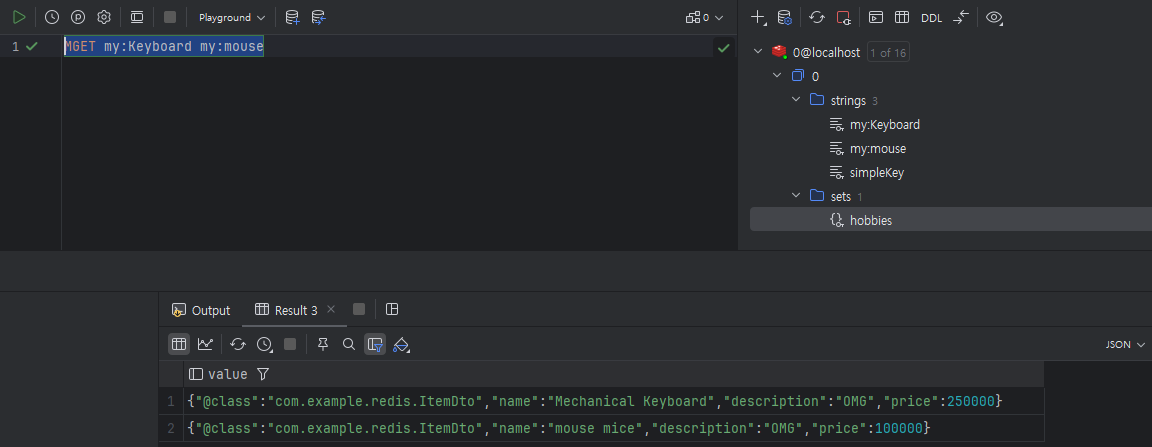
이처럼 Redis의 특정 기능을 상세하게 사용하고 싶다면, RedisTemplate를 사용할 수 있다.
실습 - 블로그 조회수
1. 내 블로그 글 별 조회수를 Redis로 확인하고 싶다.
1. 블로그 URL의 PATH는 `/articles/{id}` 형식이다.
2. 로그인 여부와 상관없이 새로고침 될때마다 조회수가 하나 증가한다.
3. 이를 관리하기 위해 적당한 데이터 타입을 선정하고,
4. 사용자가 임의의 페이지에 접속할 때 실행될 명령을 작성해보자.
2. 블로그에 로그인한 사람들의 조회수와 가장 많은 조회수를 기록한 글을 Redis로 확인하고 싶다.
1. 블로그 URL의 PATH는 `/articles/{id}` 형식이다.
2. 로그인 한 사람들의 계정은 영문으로만 이뤄져 있다.
3. 이를 관리하기 위해 적당한 데이터 타입을 선정하고,
4. 사용자가 임의의 페이지에 접속할 때 실행될 명령을 작성해보자.
5. 만약 상황에 따라 다른 명령이 실행되어야 한다면, 주석으로 추가해보자.
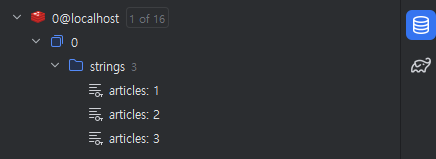
1번 문항을 Redis에서 명령어로 작성해보자.
-- INCR articles:{id}
INCR articles:1
INCR articles:2
INCR articles:3
-- 오늘의 조회수를 따로 관리하고 싶다면?
INCR articles:1:today
RENAME articles:1:today articles:20XX-XX-XX
2번 문항을 Redis에서 명령어로 작성해보자.
-- 중복을 허용하면 안되므로 set 사용
SADD articles:1 alex
SADD articles:1 brad
SADD articles:1 chad
SCARD articles:1
SADD articles:2 alex
SADD articles:2 chad
SCARD articles:2
-- SADD의 결과에 따라 명령어를 실행하거나 말거나
-- 0은 스킵 (중복된 데이터가 SADD 될 경우는 0이 출력)
-- 1일 경우 Sorted Set에 넣어주자
ZINCRBY articles:ranks 1 articles:1
ZINCRBY articles:ranks 1 articles:2
ZRANGE articles:ranks 0 -1
-- 제일 조회수가 많은 글 조회
ZREVRANGE articles:ranks 0 0
ZRANGE articles:ranks 0 0 REV
실습 - 주문
1. 주문 ID, 판매 물품, 갯수, 총액, 결제 여부에 대한 데이터를 지정하기 위한 `ItemOrder` 클래스를 `RedisHash`로 만들고,
1. 주문 ID - String
2. 판매 물품 - String
3. 갯수 - Integer
4. 총액 - Long
5. 주문 상태 - String
2. 주문에 대한 CRUD를 진행하는 기능을 만들어보자.
1. `ItemOrder`의 속성값들을 ID를 제외하고 클라이언트에서 전달해준다.
2. 성공하면 저장된 `ItemOrder`를 사용자에게 응답해준다.
새로운 Spring 프로젝트에서 실습을 진행해본다.
@Getter
@Setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
@RedisHash("order")
public class ItemOrder {
@Id
private String id;
private String item;
private Integer count;
private Long totalPrice;
private String status;
}
public interface OrderRepository extends CrudRepository<ItemOrder, String> {}
@RequiredArgsConstructor
@RestController
@RequestMapping("orders")
public class OrderController {
private final OrderRepository orderRepository;
@PostMapping
public ItemOrder create(@RequestBody ItemOrder order) {
return orderRepository.save(order);
}
@GetMapping
public List<ItemOrder> readAll() {
List<ItemOrder> orders = new ArrayList<>();
orderRepository.findAll().forEach(orders::add);
return orders;
}
@GetMapping("{id}")
public ItemOrder readOne(@PathVariable("id") String id) {
return orderRepository.findById(id)
.orElseThrow(() -> new ResponseStatusException(HttpStatus.NOT_FOUND));
}
@PutMapping("{id}")
public ItemOrder update(@PathVariable("id") String id, @RequestBody ItemOrder order) {
ItemOrder target = orderRepository.findById(id)
.orElseThrow(() -> new ResponseStatusException(HttpStatus.NOT_FOUND));
target.setItem(order.getItem());
target.setCount(order.getCount());
target.setTotalPrice(order.getTotalPrice());
target.setStatus(order.getStatus());
return orderRepository.save(target);
}
@DeleteMapping("{id}")
public void delete(@PathVariable("id") String id) {
orderRepository.deleteById(id);
}
}
Postman에서 다음과 같이 요청을 보내본다.
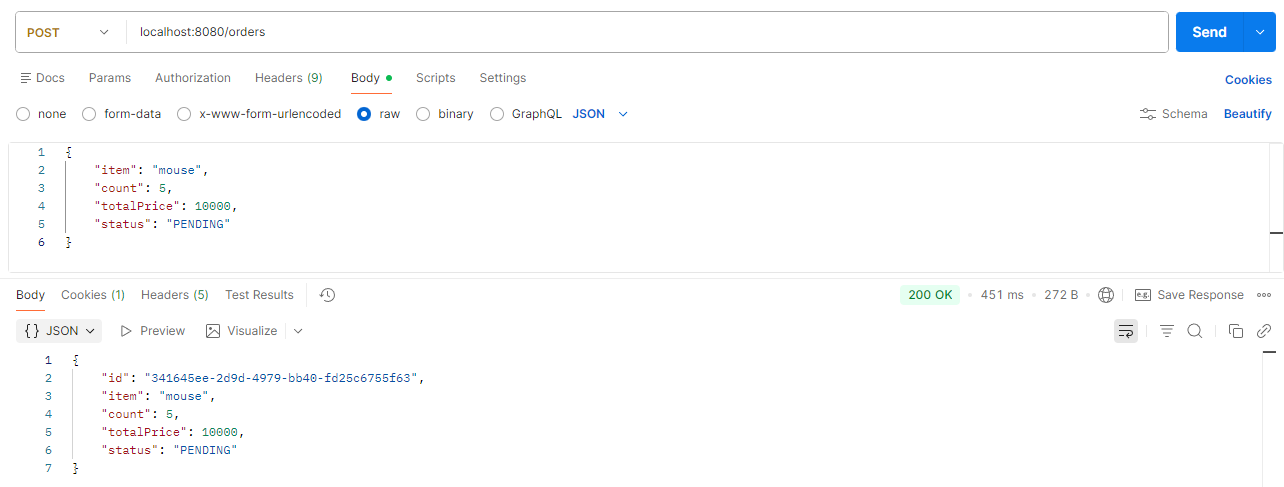
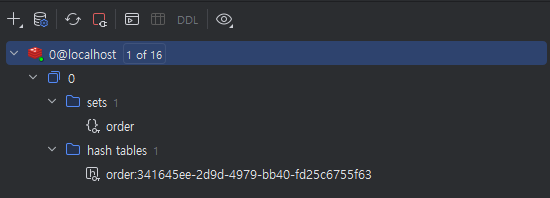
나머지 API들도 잘 동작함을 알 수 있다.
이번에는 새로운 Spring 프로젝트에 다음 기능을 만들어본다.
실제 Entity 등은 만들지 않고, Redis에 데이터만 저장해보자.
-- Redis의 문자열은 저장된 데이터가 정수라면
-- INCR, DECR 등으로 값을 쉽게 조정할 수 있다.
-- 추가로 존재하지 않는 데이터에 대해서 실행할 경우 0으로 초기화된다.
INCR articles:{id}
다음과 같이 코드를 작성한다.
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Integer> articleTemplate(
RedisConnectionFactory redisConnectionFactory
) {
RedisTemplate<String, Integer> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
template.setKeySerializer(RedisSerializer.string());
template.setValueSerializer(new GenericToStringSerializer<>(Integer.class));
return template;
}
}
@RestController
@RequestMapping("articles")
public class ArticleController {
private final ValueOperations<String, Integer> ops;
public ArticleController(RedisTemplate<String, Integer> articleTemplate) {
ops = articleTemplate.opsForValue();
}
@GetMapping("{id}")
@ResponseStatus(HttpStatus.NO_CONTENT)
public void read(@PathVariable Long id) {
ops.increment("articles: %d".formatted(id));
}
}
Postman에서 다음과 같이 /1, /2, /3으로 실행해본다.

댓글남기기